
LEAPS: A discrete neural sampler via locally equivariant networks
Authors
Peter Holderrieth, Michael S. Albergo, Tommi Jaakkola
Abstract
We propose "LEAPS", an algorithm to sample from discrete distributions known up to normalization by learning a rate matrix of a continuous-time Markov chain (CTMC). LEAPS can be seen as a continuous-time formulation of annealed importance sampling and sequential Monte Carlo methods, extended so that the variance of the importance weights is offset by the inclusion of the CTMC. To derive these importance weights, we introduce a set of Radon-Nikodym derivatives of CTMCs over their path measures. Because the computation of these weights is intractable with standard neural network parameterizations of rate matrices, we devise a new compact representation for rate matrices via what we call "locally equivariant" functions. To parameterize them, we introduce a family of locally equivariant multilayer perceptrons, attention layers, and convolutional networks, and provide an approach to make deep networks that preserve the local equivariance. This property allows us to propose a scalable training algorithm for the rate matrix such that the variance of the importance weights associated to the CTMC are minimal. We demonstrate the efficacy of LEAPS on problems in statistical physics.
Concepts
The Big Picture
Imagine trying to find a needle in a haystack the size of a continent, most of it empty. This is sampling from complex probability distributions: drawing representative examples from a distribution you can’t fully describe, while navigating a vast space of possibilities. In physics, the problem appears everywhere, from simulating magnets to understanding protein folding. In AI, it underlies Bayesian inference, language modeling, and generative systems.
The workhorse solution has long been Markov chain Monte Carlo (MCMC): run a random process long enough and it eventually explores the distribution. But “long enough” can mean astronomically long, especially when the distribution has multiple peaks separated by low-probability valleys. Algorithms get stuck. Convergence stalls.
Researchers have layered on techniques like annealed importance sampling (AIS) and sequential Monte Carlo (SMC) to help, but these introduce their own problem. The importance weights, correction factors that compensate for the mismatch between your approximate sampler and the true target, can have enormous variance. Estimates become unreliable.
A team from MIT and Harvard has proposed a method called LEAPS that learns a transport process over discrete state spaces, settings where the system exists in distinct, countable configurations (like spins that are either up or down) rather than a continuous range. LEAPS moves samples from a simple starting distribution to a complex target while keeping those correction weights tightly controlled through a novel neural network architecture.
Key Insight: LEAPS learns a dynamic transport process over discrete state spaces that minimizes the variance of importance weights, making sampling both statistically rigorous and practically scalable.
How It Works
Instead of running a Markov chain until it equilibrates, LEAPS constructs a time-dependent path: a continuous interpolation between a simple distribution at time t = 0 and the hard-to-sample target at time t = 1. A continuous-time Markov chain (CTMC), a process where the system jumps between configurations at random moments rather than at fixed discrete steps, is trained to follow this path.
The transport is driven by a rate matrix Q_t(y, x), which encodes at each moment how likely the chain is to jump from state x to state y. When the rate matrix satisfies the Kolmogorov forward equation (a classical result describing how a distribution must evolve over time), walkers initialized from the simple distribution automatically arrive at the target at t = 1.
Any learned rate matrix will be imperfect in practice. LEAPS corrects for this using Radon-Nikodym derivatives, reweighting factors that account for the difference between the trajectory your chain actually took and the one it should have taken. Minimizing the variance of these weights turns out to be equivalent to optimizing a physics-informed neural network (PINN) loss, a loss function from scientific computing that penalizes deviations from the governing equations.
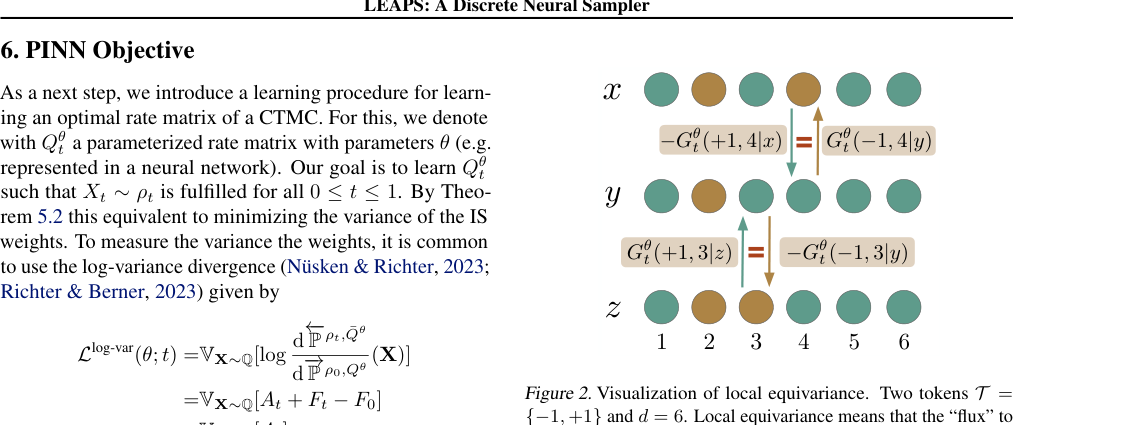
The catch: computing these weights naively requires summing over all possible transitions at every time step. For S states, a naive rate matrix has S² entries, which is intractable at realistic scale. The team’s solution is the paper’s most original contribution: the locally equivariant function.
For physical systems on a lattice (a regular grid of sites, like squares on a chessboard, each holding a value), the transition from state x to state y differs by only a local flip. A locally equivariant network exploits this structure: the output f(y; x) for a target state differing from x by flipping site i depends only on the local neighborhood of i. This drops complexity from O(S²) to O(S · d), where d is the number of sites.
The researchers construct locally equivariant versions of:
- Multilayer perceptrons (MLPs), by processing local difference vectors
- Attention layers, by applying equivariant attention over site neighborhoods
- Convolutional networks, which inherit local equivariance naturally from their structure
They also prove that composing locally equivariant layers preserves the property. This means you can stack deep networks that capture complex dependencies without blowing up computation.
Why It Matters
The physics application in the paper, sampling from the Ising model, is a canonical benchmark. The Ising model describes a lattice of binary spins interacting with neighbors, producing the kind of multimodal, correlated distributions that defeat naive MCMC. LEAPS produces correct samples in high dimensions, confirming that both the theory and the architecture work as advertised.
The implications go well beyond spin systems. Discrete distributions show up everywhere: protein sequences, genomic data, combinatorial optimization, language. Continuous generative models like diffusion and flow matching have advanced rapidly, but their discrete counterparts have lagged. LEAPS offers both the theoretical framework and the practical architecture to start closing that distance.
The locally equivariant architecture is itself a reusable building block. Any application where transitions are local and the state space is structured can plug it in. Plenty of open questions remain: how LEAPS scales to much larger state spaces, whether it extends to non-lattice structures like graphs or trees, and whether learned CTMCs can combine with modern sampling techniques to tackle genuinely intractable posteriors.
Bottom Line: LEAPS fills a long-standing gap in machine learning by bringing learned measure transport to discrete distributions, using a locally equivariant architecture that makes the math tractable and the sampling provably correct.
IAIFI Research Highlights
LEAPS applies deep learning architecture design to a core problem in statistical physics, constructing efficient samplers for spin models, with theoretical foundations drawn from measure theory and non-equilibrium dynamics.
The locally equivariant neural network framework enables scalable parameterization of rate matrices over large discrete state spaces, creating a foundation for learned discrete generative models with statistical guarantees.
By providing a rigorous, efficient sampler for distributions like the Ising model, LEAPS offers a new computational tool for studying phase transitions, lattice field theories, and other problems in statistical and quantum physics where exact normalization constants are unknown.
Future work may extend LEAPS to protein design, language modeling, and lattice QCD applications. See [arXiv:2502.10843](https://arxiv.org/abs/2502.10843) for the full paper.
Original Paper Details
LEAPS: A discrete neural sampler via locally equivariant networks
2502.10843
["Peter Holderrieth", "Michael S. Albergo", "Tommi Jaakkola"]
We propose "LEAPS", an algorithm to sample from discrete distributions known up to normalization by learning a rate matrix of a continuous-time Markov chain (CTMC). LEAPS can be seen as a continuous-time formulation of annealed importance sampling and sequential Monte Carlo methods, extended so that the variance of the importance weights is offset by the inclusion of the CTMC. To derive these importance weights, we introduce a set of Radon-Nikodym derivatives of CTMCs over their path measures. Because the computation of these weights is intractable with standard neural network parameterizations of rate matrices, we devise a new compact representation for rate matrices via what we call "locally equivariant" functions. To parameterize them, we introduce a family of locally equivariant multilayer perceptrons, attention layers, and convolutional networks, and provide an approach to make deep networks that preserve the local equivariance. This property allows us to propose a scalable training algorithm for the rate matrix such that the variance of the importance weights associated to the CTMC are minimal. We demonstrate the efficacy of LEAPS on problems in statistical physics.