
Learning an Effective Evolution Equation for Particle-Mesh Simulations Across Cosmologies
Authors
Nicolas Payot, Pablo Lemos, Laurence Perreault-Levasseur, Carolina Cuesta-Lazaro, Chirag Modi, Yashar Hezaveh
Abstract
Particle-mesh simulations trade small-scale accuracy for speed compared to traditional, computationally expensive N-body codes in cosmological simulations. In this work, we show how a data-driven model could be used to learn an effective evolution equation for the particles, by correcting the errors of the particle-mesh potential incurred on small scales during simulations. We find that our learnt correction yields evolution equations that generalize well to new, unseen initial conditions and cosmologies. We further demonstrate that the resulting corrected maps can be used in a simulation-based inference framework to yield an unbiased inference of cosmological parameters. The model, a network implemented in Fourier space, is exclusively trained on the particle positions and velocities.
Concepts
The Big Picture
Imagine trying to model the entire universe, every clump of dark matter, every gravitational tug between galaxies, using a computer. Now imagine the most accurate way to do it would take longer than the age of the universe itself. That’s what cosmologists face when they run N-body simulations, the gold-standard tool for tracing how large-scale cosmic structure formed and evolved over 13 billion years.
The math is brutal: simulating gravitational interactions between n particles means every particle must feel the pull of every other. Double the particles, quadruple the work. Physicists reached for a shortcut. Particle-mesh (PM) simulations bin particles onto a grid and solve gravity using Fast Fourier Transforms, a technique that converts spatial information into frequency components and makes the computation vastly cheaper. These run in a fraction of the time.
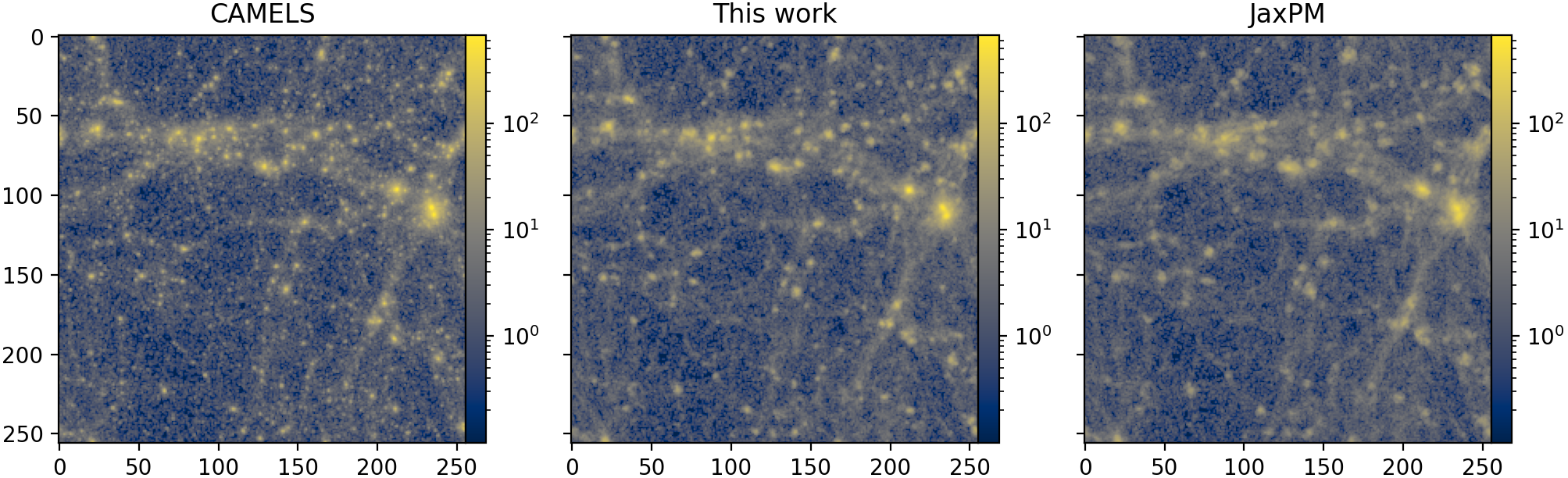
The catch? The grid is coarse. Small-scale details get blurred or lost entirely: the dense clumps of dark matter where galaxies form, the fine threads of the cosmic web. It’s like trading a 4K camera for a disposable film camera. You capture the scene, but you lose the texture.
A team from the Université de Montréal, Mila, MIT, and the Flatiron Institute found a way to recover most of that resolution by training a neural network to learn, from data alone, exactly how the fast simulation goes wrong and how to fix it.
Key Insight: A small neural network operating in Fourier space can learn to correct the gravitational errors in fast particle-mesh simulations, enabling accurate predictions across a wide range of cosmologies without ever being told which cosmology it’s running in.
How It Works
The approach is grounded in effective field theory, a framework physicists use to model behavior at one scale without tracking every detail at smaller scales. Instead of adding back fine-grained particle interactions by hand, the researchers asked: can a neural network learn the effective equation of motion that a coarse simulation should be following?
Their simulator, JaxPM, is written in JAX and treats the simulation as a system of ordinary differential equations (ODEs), step-by-step equations describing how particle positions and velocities evolve over time. This makes the simulator differentiable: training signals can flow all the way back through the simulation, enabling end-to-end learning.
The correction pipeline works in four steps:
- Run a PM simulation as normal (fast but inaccurate at small scales).
- Apply a neural network correction to the gravitational potential in Fourier space, before computing forces on each particle.
- Update particle positions and velocities using the corrected forces.
- Repeat at each time step as the simulation evolves from redshift z = 127 (the early universe) to z = 0 (today).
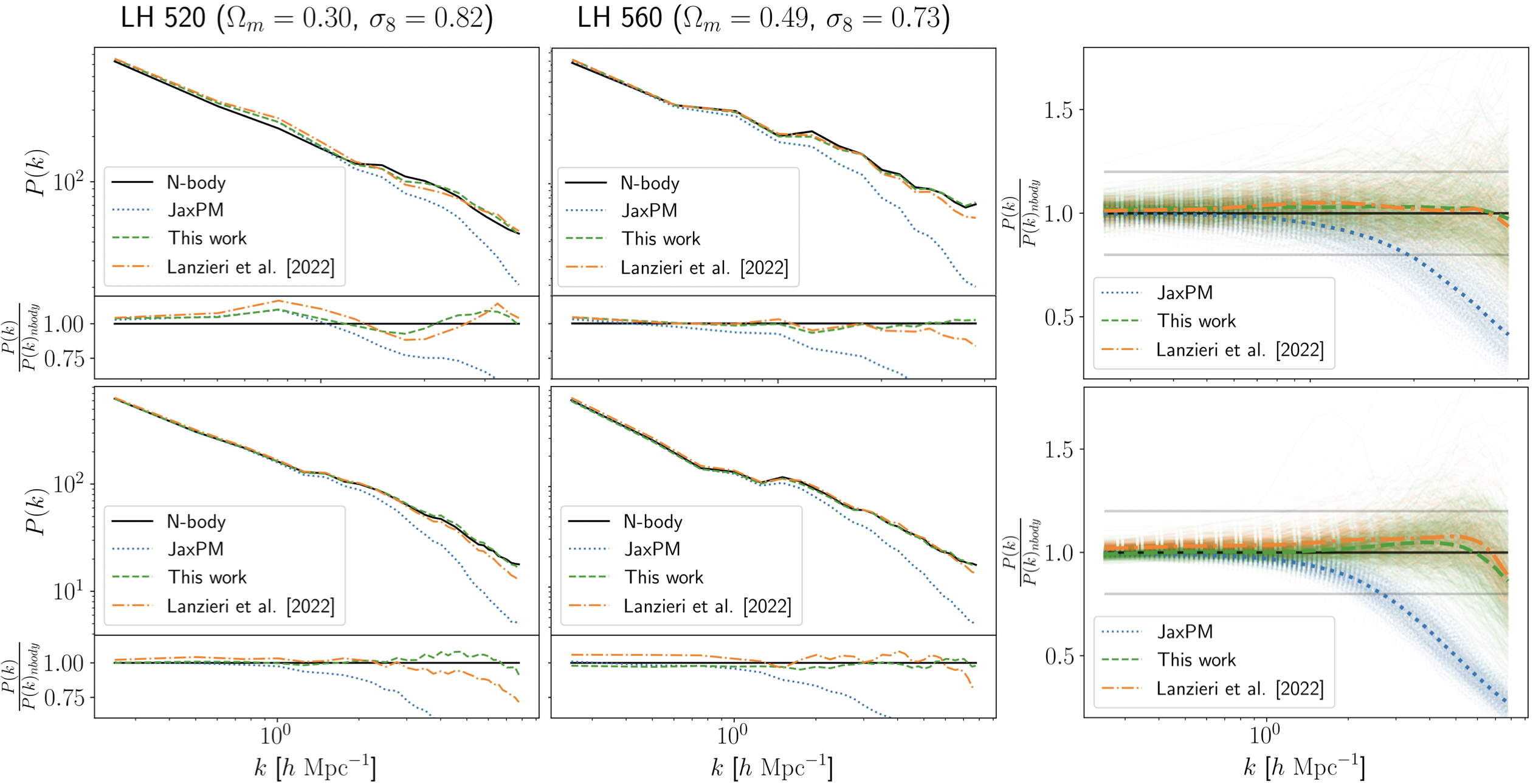
The network is small on purpose: five hidden layers of 64 neurons each, with sinusoidal activations. Its outputs are coefficients of a B-spline, a smooth mathematical curve that shapes how the correction varies across spatial scales. Inputs are minimal: the scale factor a (how expanded the universe is), the wavenumber |k| (which spatial scale is being corrected, where large |k| means small-scale structure), and two cosmological parameters, Ω_m (matter density) and σ₈ (amplitude of density fluctuations).
The network is isotropic, treating all spatial directions equally and respecting a fundamental symmetry of the universe. Training used 1,000 simulations from the CAMELS suite, dark matter-only runs spanning a wide range of cosmological parameters via a Latin Hypercube sampling grid that spreads training examples evenly across a high-dimensional parameter space.
The loss function was simple: just the L2 distance between corrected PM particle positions and velocities versus the reference N-body simulation. No power spectrum matching. No fancy statistics. Just: make the particles end up in the right place, moving at the right speed.
Why It Matters
The payoff comes in two parts. First, the correction generalizes. Tested on cosmologies never seen during training, the corrected simulations dramatically outperform uncorrected PM runs, recovering small-scale structure the fast method would otherwise miss.
This is not obvious. Neural networks that learn corrections inside dynamical systems can easily overfit to specific training conditions. That this one doesn’t suggests the network has learned something close to a true physical correction, not just a statistical patch.
Second, the corrected simulations plug directly into simulation-based inference (SBI), a modern approach to cosmological parameter estimation that bypasses writing down an explicit likelihood function. In practice, instead of compressing simulations into mathematical summaries, SBI uses the raw simulation outputs to ask which cosmological parameters best fit the data.
The researchers showed that feeding corrected PM outputs into an SBI pipeline yields unbiased constraints on Ω_m and σ₈. Uncorrected PM simulations introduce systematic errors that would skew those measurements. This matters for upcoming surveys like DESI, Euclid, and the Rubin Observatory, which demand sub-percent accuracy in cosmological parameter inference.
The broader lesson is architectural: by keeping the correction physically grounded (Fourier-space operations, symmetry-respecting design, trained only on positions and velocities), the team built something more transferable than a black-box emulator. The network corrects the dynamics, not just the final outputs, inheriting the simulation’s physical structure rather than working around it.
Bottom Line: By learning a small but precise correction to how gravity is computed in fast cosmological simulations, this work makes cheap simulations nearly as accurate as expensive ones, and does it in a way that generalizes across cosmologies, opening the door to unbiased parameter inference at scale.
IAIFI Research Highlights
This work fuses differentiable N-body simulation, symmetry-guided neural network design, and simulation-based inference into a single pipeline, a product of collaboration between AI institutes (Mila, IAIFI) and astrophysics centers (Flatiron, CfA).
Physically motivated inductive biases (isotropy, Fourier-space operations, ODE-embedded training) allow a small network to generalize across dynamical regimes where purely data-driven approaches would fail.
Corrected particle-mesh simulations that accurately recover small-scale structure enable unbiased inference of fundamental cosmological parameters, supporting precision tests of the universe's composition and growth history.
Future work could extend the correction to baryonic effects and larger simulation volumes. The paper appeared at the Machine Learning and the Physical Sciences Workshop at NeurIPS 2023 ([arXiv:2311.18017](https://arxiv.org/abs/2311.18017)).