
Learning Efficient Representations of Neutrino Telescope Events
Authors
Felix J. Yu, Nicholas Kamp, Carlos A. Argüelles
Abstract
Neutrino telescopes detect rare interactions of particles produced in some of the most extreme environments in the Universe. This is accomplished by instrumenting a cubic-kilometer scale volume of naturally occurring transparent medium with light sensors. Given their substantial size and the high frequency of background interactions, these telescopes amass an enormous quantity of large variance, high-dimensional data. These attributes create substantial challenges for analyzing and reconstructing interactions, particularly when utilizing machine learning (ML) techniques. In this paper, we present a novel approach, called om2vec, that employs transformer-based variational autoencoders to efficiently represent the detected photon arrival time distributions of neutrino telescope events by learning compact and descriptive latent representations. We demonstrate that these latent representations offer enhanced flexibility and improved computational efficiency, thereby facilitating downstream tasks in data analysis.
Concepts
The Big Picture
Imagine trying to catch a ghost. Neutrinos, nearly massless particles streaming from supernova explosions, black hole jets, and the cores of active galaxies, pass through ordinary matter almost entirely undetected. To catch even a handful, physicists buried 5,160 basketball-sized light sensors a mile and a half deep in Antarctic ice, creating a detector the size of a cubic kilometer. This is the IceCube Neutrino Observatory.
But catching ghosts creates a data problem. IceCube records about 3,000 events per second, most of them background noise from cosmic rays rather than the precious neutrino signals physicists actually want. Each event is a sprawling record of when and where light flashed across thousands of sensors. Some sensors near an interaction might detect tens of thousands of photons; others, farther away, catch only a handful. The result is data that is enormous, inconsistent, and brutally hard to feed into machine learning tools.
Researchers at Harvard and IAIFI have developed a new approach called om2vec that uses a transformer, a type of AI architecture trained to recognize patterns in sequences, to compress this messy, variable output into compact, uniform summaries. The actual physics analysis becomes dramatically more manageable.
Key Insight: om2vec learns to squeeze each sensor’s complete record of light detections into a fixed-size “fingerprint” that retains the essential physics while enabling fast, flexible analysis of neutrino telescope data.
How It Works
The raw data from each optical module (OM) is a photon arrival time distribution (PATD), a histogram showing when photons arrived at nanosecond resolution over microsecond-long events. These distributions are complex, variable in length, and wildly different from sensor to sensor depending on proximity to the particle interaction.
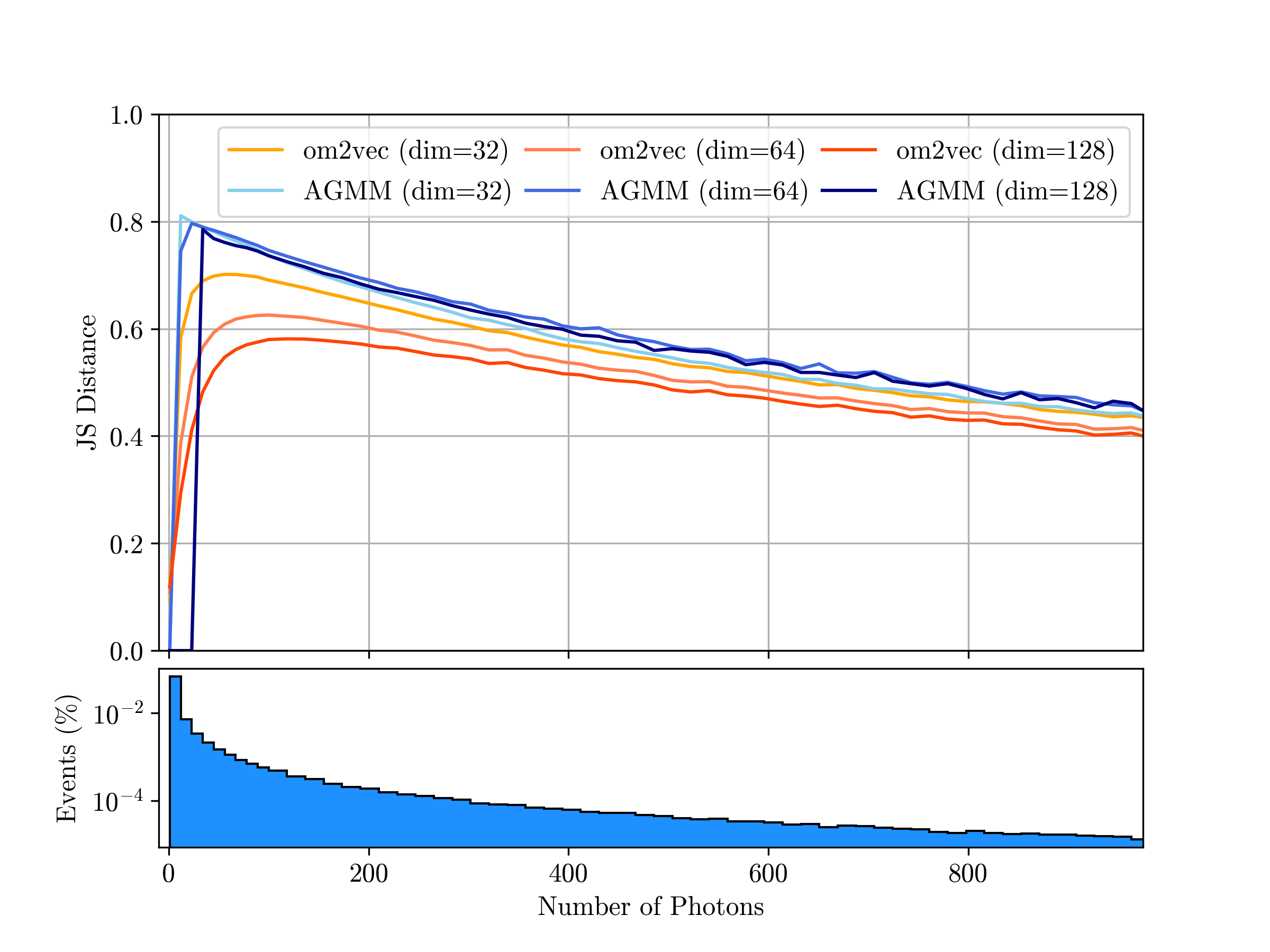
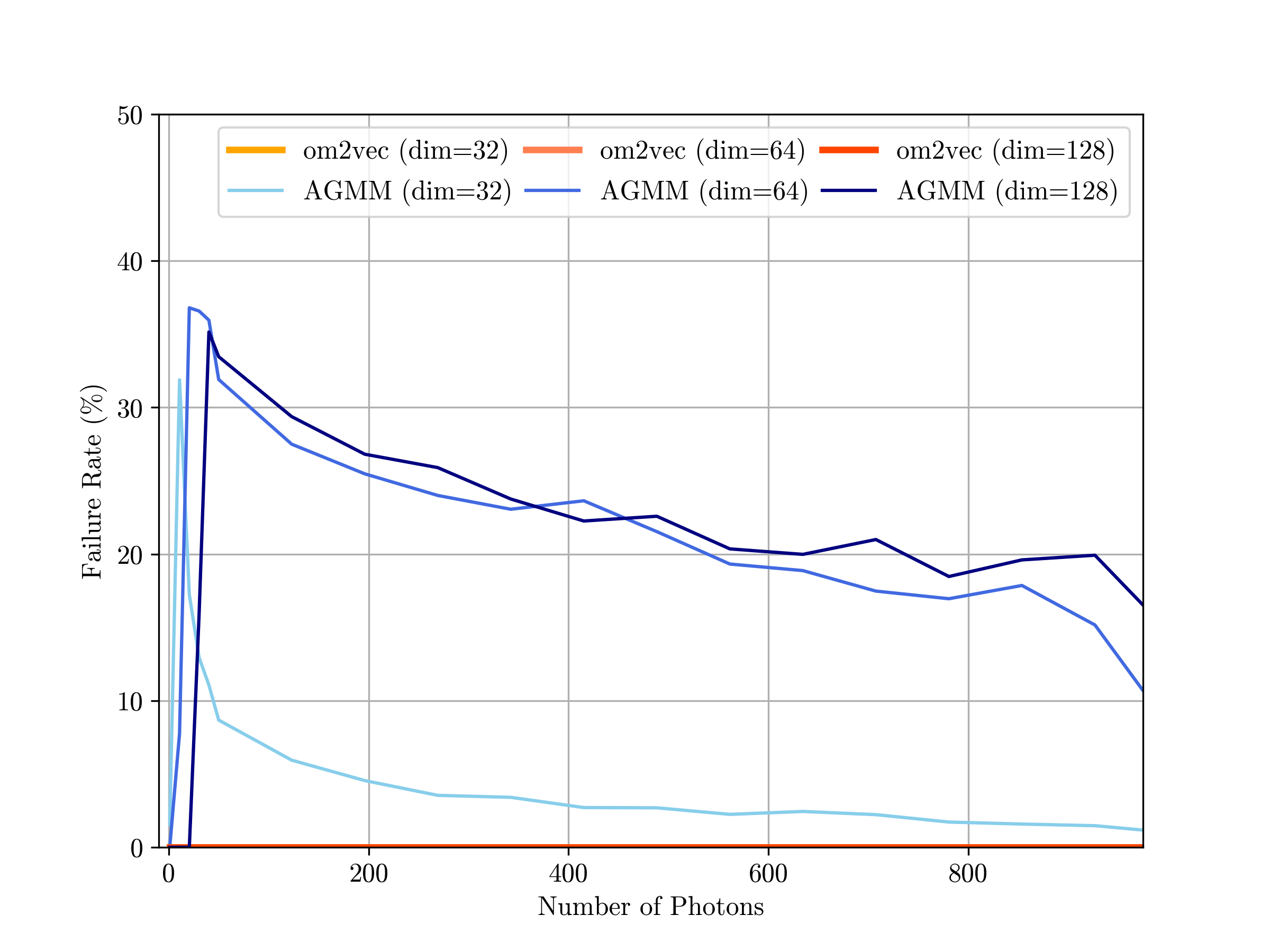
Previous approaches tried two strategies. The first used summary statistics, boiling each PATD down to a few key numbers like total charge and mean arrival time. Fast and uniform, but information is lost forever. The second fit an asymmetric Gaussian mixture model (AGMM), a mathematical curve, to each sensor’s data. More faithful to the original signal, but slow, sensitive to hyperparameter choices, and prone to failure on difficult inputs.
om2vec takes a third path. It trains a variational autoencoder (VAE) enhanced with transformer layers, an architecture that excels at finding patterns across sequences:
- Input embedding: The timing data is converted into a richer numerical form the network can process.
- Transformer encoding: Attention layers, which weigh how different parts of the sequence relate to each other, capture relationships across the timing record. Feedforward networks progressively condense the sequence.
- Latent representation: The encoder distills the sequence into a compact fixed-size vector (a mathematical fingerprint) by learning the most likely summary and how much uncertainty to allow around it.
- Reconstruction: A symmetric decoder expands the fingerprint back to the original timing distribution. The network learns during training to make this round-trip as faithful as possible.
One subtle design choice matters here: the decoder uses a learned memory embedding, its own internal reference, rather than passing the encoder’s output through directly. This keeps the decoder independent, so the latent vector truly acts as a self-contained summary rather than a compressed encoder state.
The team trained om2vec on simulated IceCube data covering both cascade-like events (roughly spherical light distributions from neutrino interactions) and track-like events (elongated signatures from muons). A single model handles the full diversity of IceCube data without task-specific tuning.
Why It Matters
The physics payoff is real. When tested on reconstruction tasks (recovering a particle’s energy, direction, and type from the learned fingerprints alone) om2vec matched or outperformed both summary statistics and AGMM, often running substantially faster. The representations drop into existing machine learning pipelines with no architectural changes, acting as a universal preprocessing layer.
This matters beyond IceCube. Several next-generation neutrino telescopes are under construction or planned: KM3NeT in the Mediterranean, Baikal-GVD in Russia, P-ONE in the Pacific, and IceCube-Gen2, which would expand the Antarctic detector tenfold. Each will generate more data at higher rates. A general-purpose representation learner that works at the earliest stage of data collection could become infrastructure, deployed at the detector level, quietly enabling everything downstream.
There is also a machine learning angle here. Transformers have revolutionized language and vision, but applying them to irregular, variable-length physics data requires architectural care. The hybrid encoder design (attention across features, feedforward networks across sequence length) is a specific engineering choice that the paper validates empirically, showing transformers outperform fully connected baselines on this task.
The VAE’s continuous, structured latent space also creates possibilities that previous approaches didn’t offer. Nearby points in latent space correspond to similar physical events, which means the representations can support anomaly detection, generative modeling, and semi-supervised learning, all active frontiers in particle physics data analysis.
Bottom Line: om2vec converts messy, variable neutrino detector data into compact, physics-rich representations that are faster to process and more flexible than existing methods, a potential building block for next-generation neutrino telescope analysis.
IAIFI Research Highlights
This work brings transformer-based deep learning, a tool honed on language and vision, to bear on the specific data challenges of high-energy neutrino physics, producing a method validated on IceCube simulation data.
The hybrid transformer-VAE architecture shows how to encode irregular, variable-length sequential data into structured latent spaces, an approach transferable to other scientific domains with similarly messy data.
om2vec enables more efficient and accurate reconstruction of neutrino event properties (energy, direction, and type), which is foundational to IceCube's search for high-energy cosmic neutrino sources and tests of the Standard Model.
The authors release source code, datasets, and pre-trained checkpoints publicly, positioning om2vec for adoption by the broader neutrino telescope community as detectors like IceCube-Gen2 scale up; see [arXiv:2410.13148](https://arxiv.org/abs/2410.13148).
Original Paper Details
Learning Efficient Representations of Neutrino Telescope Events
[2410.13148](https://arxiv.org/abs/2410.13148)
Felix J. Yu, Nicholas Kamp, Carlos A. Argüelles
Neutrino telescopes detect rare interactions of particles produced in some of the most extreme environments in the Universe. This is accomplished by instrumenting a cubic-kilometer scale volume of naturally occurring transparent medium with light sensors. Given their substantial size and the high frequency of background interactions, these telescopes amass an enormous quantity of large variance, high-dimensional data. These attributes create substantial challenges for analyzing and reconstructing interactions, particularly when utilizing machine learning (ML) techniques. In this paper, we present a novel approach, called om2vec, that employs transformer-based variational autoencoders to efficiently represent the detected photon arrival time distributions of neutrino telescope events by learning compact and descriptive latent representations. We demonstrate that these latent representations offer enhanced flexibility and improved computational efficiency, thereby facilitating downstream tasks in data analysis.