
Learning to Optimize Quasi-Newton Methods
Authors
Isaac Liao, Rumen R. Dangovski, Jakob N. Foerster, Marin Soljačić
Abstract
Fast gradient-based optimization algorithms have become increasingly essential for the computationally efficient training of machine learning models. One technique is to multiply the gradient by a preconditioner matrix to produce a step, but it is unclear what the best preconditioner matrix is. This paper introduces a novel machine learning optimizer called LODO, which tries to online meta-learn the best preconditioner during optimization. Specifically, our optimizer merges Learning to Optimize (L2O) techniques with quasi-Newton methods to learn preconditioners parameterized as neural networks; they are more flexible than preconditioners in other quasi-Newton methods. Unlike other L2O methods, LODO does not require any meta-training on a training task distribution, and instead learns to optimize on the fly while optimizing on the test task, adapting to the local characteristics of the loss landscape while traversing it. Theoretically, we show that our optimizer approximates the inverse Hessian in noisy loss landscapes and is capable of representing a wide range of inverse Hessians. We experimentally verify that our algorithm can optimize in noisy settings, and show that simpler alternatives for representing the inverse Hessians worsen performance. Lastly, we use our optimizer to train a semi-realistic deep neural network with 95k parameters at speeds comparable to those of standard neural network optimizers.
Concepts
The Big Picture
Every time you train a neural network, you’re wandering through a vast, mountainous terrain trying to find the lowest valley. The gradient tells you which direction is downhill, but says nothing about how far to step. A clever hiker reads the terrain as they walk, adjusting their stride based on whether the slope is gentle or treacherous. Most modern optimizers, like Adam, are more like hikers with fixed stride lengths, oblivious to the curvature beneath them.
The gold standard for terrain-aware stepping is the Newton method, which uses the Hessian (a mathematical map of how steeply the loss curves in every direction at once) to take near-perfect steps. The catch: computing and inverting this map for a network with millions of parameters is astronomically expensive. Quasi-Newton methods sidestep this by approximating the curvature map from a history of past gradients, and they work well. But these approximations follow fixed formulas, baked in by human designers who can’t anticipate every loss surface.
A team of MIT and Oxford researchers has flipped the script. Their optimizer, LODO (Learning to Optimize During Optimization), doesn’t approximate the curvature map with a hardcoded recipe. It learns one, in real time, as it optimizes.
Key Insight: LODO merges machine learning with classical optimization theory, using a small neural network to represent the inverse Hessian and updating it on the fly, with no pre-training on example tasks.
How It Works
In a standard quasi-Newton update, you multiply the gradient g by an approximate inverse Hessian matrix G (your curvature map, inverted to point toward the valley floor) to get your step: x → x − G · g.
The question is always: what should G look like? L-BFGS, the most famous quasi-Newton method, constructs G from a rolling window of past gradient differences using a specific algebraic formula. LODO instead represents G as a neural network preconditioner, a small learned function that takes the gradient as input and transforms it into a smarter, curvature-aware step.
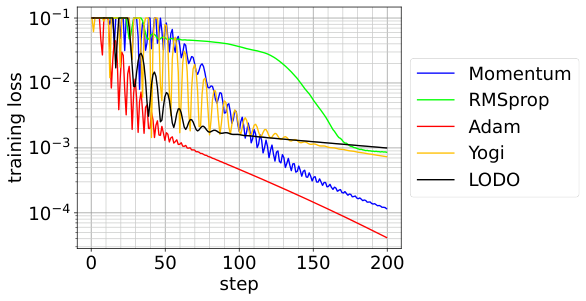
Here’s where it gets interesting. LODO updates this preconditioner using hypergradient descent: backpropagating through the optimization step itself to measure how well the preconditioner helped, then adjusting it accordingly. Think of it as a meta-optimizer riding alongside the main optimizer, tuning the step-computation machinery in real time. This all happens during the actual optimization run. There’s no separate training phase where LODO learns on curated example problems.
The preconditioner architecture matters a lot. The authors use a structure they call a generalized Kronecker factorization, representing large matrices implicitly by breaking them into smaller, composable pieces to keep memory costs manageable. This gives LODO a few concrete advantages:
- More expressive than diagonal preconditioners like those used by Adam and RMSprop, or low-rank methods
- Cheaper than full Kronecker-factored methods like K-FAC, which require expensive matrix inversions
- Flexible enough to approximate a wide family of inverse Hessians (the authors prove this theoretically)
The theory section delivers a solid guarantee. In noisy, stochastic settings (the bread and butter of deep learning) LODO provably converges toward the true inverse Hessian. If the loss surface is convex and gradients are noisy, LODO’s learned preconditioner tracks the inverse Hessian as closely as the noise allows. This isn’t empirical hand-waving; it’s a formal result.
Why It Matters
LODO isn’t just a new optimizer. It’s a proof of concept that the design of optimization algorithms can itself be automated and adapted, that the rigid, human-engineered formulas of classical quasi-Newton methods can be replaced with flexible, learned representations without sacrificing theoretical guarantees.
This has practical implications as AI models scale. Today’s frontier models consume staggering compute budgets, and even modest improvements in optimizer efficiency translate to real savings in dollars and wall-clock time. LODO runs at competitive speeds against standard optimizers on a 95,000-parameter network while offering richer adaptivity. The approach looks especially promising for architectures with heavy parameter sharing, like convolutional networks, where inference cost during training dominates optimization overhead.
The work also opens up real theoretical questions. What is the optimal preconditioner for a given loss surface? Can a learned optimizer discover structure in the Hessian that hand-designed methods systematically miss? These questions sit at the intersection of optimization theory, meta-learning, and practical AI engineering.
Bottom Line: LODO shows that the inverse Hessian, the holy grail of second-order optimization, can be learned from scratch, online, without any preparation, challenging decades of fixed-formula quasi-Newton design.
IAIFI Research Highlights
LODO connects classical mathematical optimization theory with modern machine learning by embedding neural network representations inside quasi-Newton methods, grounding learned optimization in rigorous Hessian approximation theory.
By eliminating the need for meta-training while still achieving adaptive, curvature-aware optimization, LODO pushes forward the development of "training-free" learned optimizers that can generalize across arbitrary tasks.
The framework's ability to handle noisy loss surfaces and adapt to local curvature makes it a strong candidate for optimization problems in physics simulations, where loss surfaces can be highly non-convex and stochastic.
Future work could scale LODO to larger architectures and explore hybrid designs combining it with momentum-based methods; the paper appears in TMLR (September 2023) and is available at [arXiv:2210.06171](https://arxiv.org/abs/2210.06171) and via OpenReview (forum id: Ns2X7Azudy).
Original Paper Details
Learning to Optimize Quasi-Newton Methods
[2210.06171](https://arxiv.org/abs/2210.06171)
Isaac Liao, Rumen R. Dangovski, Jakob N. Foerster, Marin Soljačić
Fast gradient-based optimization algorithms have become increasingly essential for the computationally efficient training of machine learning models. One technique is to multiply the gradient by a preconditioner matrix to produce a step, but it is unclear what the best preconditioner matrix is. This paper introduces a novel machine learning optimizer called LODO, which tries to online meta-learn the best preconditioner during optimization. Specifically, our optimizer merges Learning to Optimize (L2O) techniques with quasi-Newton methods to learn preconditioners parameterized as neural networks; they are more flexible than preconditioners in other quasi-Newton methods. Unlike other L2O methods, LODO does not require any meta-training on a training task distribution, and instead learns to optimize on the fly while optimizing on the test task, adapting to the local characteristics of the loss landscape while traversing it. Theoretically, we show that our optimizer approximates the inverse Hessian in noisy loss landscapes and is capable of representing a wide range of inverse Hessians. We experimentally verify that our algorithm can optimize in noisy settings, and show that simpler alternatives for representing the inverse Hessians worsen performance. Lastly, we use our optimizer to train a semi-realistic deep neural network with 95k parameters at speeds comparable to those of standard neural network optimizers.