
Learning to Validate Generative Models: a Goodness-of-Fit Approach
Authors
Pietro Cappelli, Gaia Grosso, Marco Letizia, Humberto Reyes-González, Marco Zanetti
Abstract
Generative models are increasingly central to scientific workflows, yet their systematic use and interpretation require a proper understanding of their limitations through rigorous validation. Classic approaches struggle with scalability, statistical power, or interpretability when applied to high-dimensional data, making it difficult to certify the reliability of these models in realistic, high-dimensional scientific settings. Here, we propose the use of the New Physics Learning Machine (NPLM), a learning-based approach to goodness-of-fit testing inspired by the Neyman--Pearson construction, to test generative networks trained on high-dimensional scientific data. We demonstrate the performance of NPLM for validation in two benchmark cases: generative models trained on mixtures of Gaussian models with increasing dimensionality, and a public end-to-end model, known as FlowSim, developed to generate high-energy physics collision events. We demonstrate that the NPLM can serve as a powerful validation method while also providing a means to diagnose sub-optimally modeled regions of the data.
Concepts
The Big Picture
Imagine a flight simulator so realistic that pilots train on it instead of real planes. Before trusting lives to it, you’d want to verify it faithfully recreates true flight dynamics, not just in clear skies, but in turbulence, edge cases, and unexpected conditions. Scientists face the same challenge with AI generative models: these tools increasingly stand in for expensive physical simulations, but verifying that they’re trustworthy is hard.
In high-energy physics, generative AI models are being deployed to simulate particle collision data from the Large Hadron Collider’s upcoming high-luminosity upgrade, a planned boost in collision rates that will produce far more data than any previous run. The stakes are high. A simulation that subtly misrepresents some corner of the data could cause a discovery to be missed, or a false one declared.
Standard statistical tests struggle with data spanning dozens of interacting variables, losing sensitivity or becoming practically impossible to run. Simpler metrics exist, but they often miss subtle mismatches buried among correlated measurements.
A team from MIT, Harvard, Padova, Genova, and RWTH Aachen has repurposed an existing physics discovery tool as a generative model validator, one that remains effective even as the number of variables climbs into the dozens.
Key Insight: The New Physics Learning Machine, originally built to hunt for signs of undiscovered physics, turns out to work well as a goodness-of-fit test for AI generative models. It gives researchers a statistically principled, interpretable validation framework that holds up in high dimensions.
How It Works
The core idea borrows from classical statistics. A two-sample test (2ST) asks a deceptively simple question: do these two collections of data look like they came from the same distribution? For validation, one sample comes from real data and the other from the generative model. The challenge is constructing a test statistic (some single number capturing whether the two samples are compatible) without requiring an explicit formula for the underlying distribution, and without losing sensitivity as the number of variables grows.
This is where the New Physics Learning Machine (NPLM) comes in. Inspired by the Neyman-Pearson lemma, which defines the theoretically optimal way to distinguish two competing hypotheses, NPLM trains a machine learning classifier to estimate the likelihood ratio: for any data point, how much more probable is it under one distribution than the other? Rather than asking “are these samples identical?”, it learns where and how they differ.
The key steps:
- Draw a reference sample R from the generative model and a data sample D from the true distribution.
- Train a kernel-based classifier to distinguish the two, optimizing a loss function derived from the Neyman-Pearson framework (not raw accuracy).
- The classifier’s output becomes the test statistic t, whose null distribution is estimated by repeatedly testing the reference against itself.
- Compute a p-value (the probability of observing a discrepancy as large as t by chance), expressed as a Z-score: how many standard deviations the result falls from what you’d expect if the model were perfect.
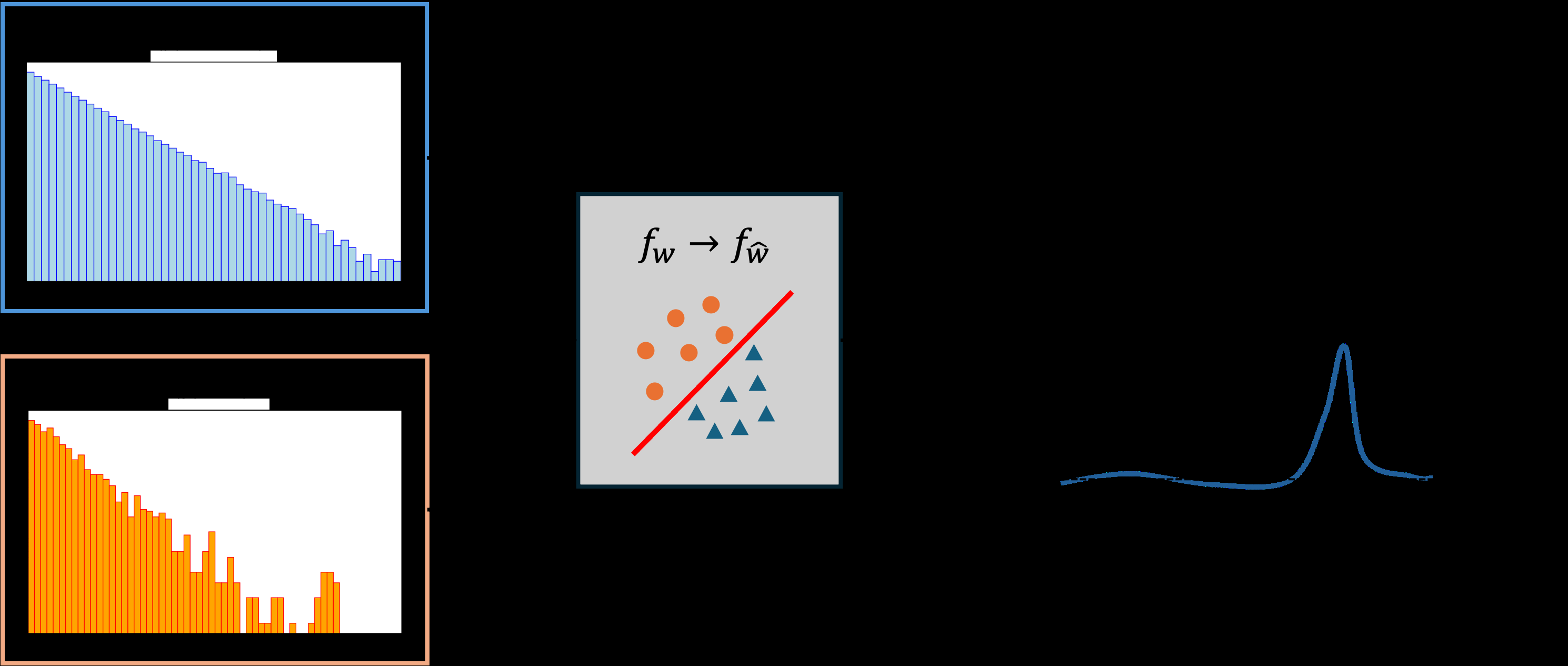
The trained classifier doesn’t just deliver a pass/fail verdict. It encodes where in the data space the generative model struggles, which means you get detailed diagnostics for free.
The team tested this on two benchmarks. First, they trained normalizing flows (generative models that learn to transform simple distributions into complex ones) on mixtures of Gaussians with dimensions ranging from 4 to 64, tracking NPLM’s ability to detect model imperfections as dimensionality increased. Second, they validated FlowSim, a real-world normalizing-flow-based simulator of particle jets at the LHC trained on simulated collision events.
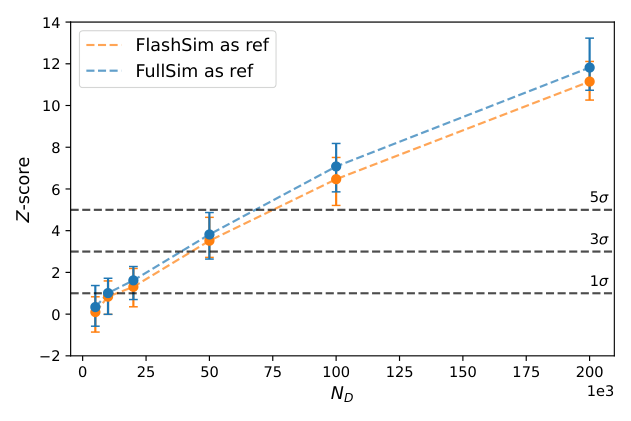
Across both benchmarks, NPLM detected deviations with high statistical power, flagging failures that simpler one-dimensional comparisons missed. The method held up as dimensionality scaled upward, a regime where many classical tests go blind.
Why It Matters
Generative AI is changing how scientists work in protein design, drug discovery, materials science, and climate modeling. In each field, a model that produces plausible-looking but subtly wrong samples could silently corrupt downstream analyses, whether that means skewed parameter estimates, false discovery claims, or bad design decisions.
What’s been missing is a statistically principled validation framework that scales to the complexity of real data. NPLM fills that role.
There’s also a satisfying methodological loop here. NPLM was originally developed to search for anomalies in LHC data that might signal physics beyond the Standard Model (the current best theory of fundamental particles and forces). The same algorithmic instinct, train a classifier to find what doesn’t fit the known distribution, turns out to be exactly what you need to audit generative models. Physics inspired the AI method; now the AI method validates physics simulations. This is the kind of exchange IAIFI was built around.
Open questions remain. How does NPLM scale to hundreds of output dimensions? How does it perform when the reference sample is finite and noisy? And can its diagnostic outputs automatically feed back into model retraining?
Bottom Line: NPLM brings the statistical rigor of hypothesis testing to generative model validation at scale. It provides not just a pass/fail verdict, but a map of where AI simulators go wrong, which is what high-stakes scientific applications need.
IAIFI Research Highlights
This work adapts a hypothesis-testing tool developed for LHC new-physics searches into a general-purpose generative model validator, a clear example of the bidirectional value in combining AI and physics research.
NPLM provides a scalable, statistically principled goodness-of-fit framework for high-dimensional generative models, addressing a regime where classical metrics lose both power and interpretability.
By validating FlowSim and similar fast simulators used in high-energy physics analyses, this method tackles a real bottleneck in LHC data analysis pipelines ahead of the high-luminosity era.
Future work will extend NPLM to higher-dimensional settings and explore automated diagnostic feedback loops for model retraining; the paper is available at [arXiv:2511.09118](https://arxiv.org/abs/2511.09118).