
Low-Rank Adapting Models for Sparse Autoencoders
Authors
Matthew Chen, Joshua Engels, Max Tegmark
Abstract
Sparse autoencoders (SAEs) decompose language model representations into a sparse set of linear latent vectors. Recent works have improved SAEs using language model gradients, but these techniques require many expensive backward passes during training and still cause a significant increase in cross entropy loss when SAE reconstructions are inserted into the model. In this work, we improve on these limitations by taking a fundamentally different approach: we use low-rank adaptation (LoRA) to finetune the \textit{language model itself} around a previously trained SAE. We analyze our method across SAE sparsity, SAE width, language model size, LoRA rank, and model layer on the Gemma Scope family of SAEs. In these settings, our method reduces the cross entropy loss gap by 30\% to 55\% when SAEs are inserted during the forward pass. We also find that compared to end-to-end (e2e) SAEs, our approach achieves the same downstream cross entropy loss 3$\times$ to 20$\times$ faster on \gemma and 2$\times$ to 10$\times$ faster on \llama. We further show that our technique improves downstream metrics and can adapt multiple SAEs at once without harming general language model capabilities. Our results demonstrate that improving model interpretability is not limited to post-hoc SAE training; Pareto improvements can also be achieved by directly optimizing the model itself.
Concepts
The Big Picture
Imagine building a perfect translation dictionary: one that converts the inner monologue of a genius into plain English. The only problem: every time you open it mid-conversation, the genius suddenly sounds 10% less intelligent. The dictionary works beautifully in isolation, but the act of using it degrades the very thing you’re trying to understand.
This is roughly the situation with sparse autoencoders (SAEs), a core tool in AI interpretability research. SAEs are trained to take the messy, entangled patterns inside a language model and translate them into a sparse set of human-readable “features”: small, labelable concepts that researchers can inspect and reason about. Think of them as a Rosetta Stone for decoding what a neural network is “thinking.”
There’s a catch: when researchers insert these translated signals back into the model’s processing pipeline, performance drops noticeably. Prior work has documented meaningful capability loss when SAEs are inserted mid-forward-pass, a cost that compounds when studying multiple layers simultaneously.
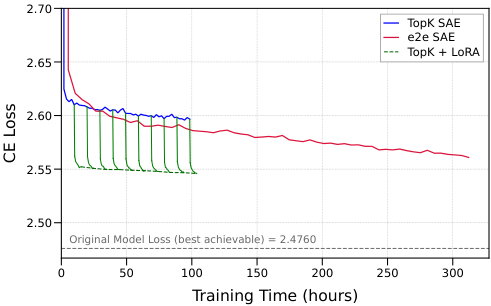
MIT researchers Matthew Chen, Joshua Engels, and Max Tegmark asked a different question: instead of making the SAE better at fitting the model, why not make the model better at working with the SAE? Their approach fine-tunes the language model itself around a frozen SAE using low-rank adaptation, achieving a 30–55% reduction in performance loss and reaching equivalent performance up to 20× faster than competing methods.
Key Insight: Rather than retraining the SAE to fit the model, this work adapts the model to fit the SAE. The reversal is subtle, but the efficiency gains are substantial, and interpretability is preserved.
How It Works
The standard interpretability pipeline trains a language model, trains an SAE on its activations, then analyzes what the SAE learned. The model is treated as fixed; all optimization pressure falls on the SAE. End-to-end (e2e) SAEs broke this mold by using the model’s gradients (feedback signals that flow backward through the network to guide learning) during SAE training. Better, but expensive: it demands many costly backward passes (full trips through the model to compute those feedback signals) and still leaves a meaningful performance gap.
Chen, Engels, and Tegmark flip the script. Their method, LoRA SAE training, keeps the SAE frozen after training and instead applies Low-Rank Adaptation (LoRA) to the language model itself. Rather than modifying all billions of parameters, LoRA adds small, targeted corrections (mathematically compact “low-rank” matrices) to specific layers. The training objective is simple: minimize the KL divergence (a measure of how different two probability distributions are) between the model’s original output and its output when the SAE reconstruction is inserted mid-forward-pass.
The training recipe is lean:
- Only 15 million tokens for fine-tuning, versus the trillions used for pretraining
- LoRA touches at most 3% of parameters, preserving the model’s general capabilities
- 130× fewer language model backward passes than e2e SAEs to reach equivalent performance
- Works on pre-existing SAEs, no retraining required
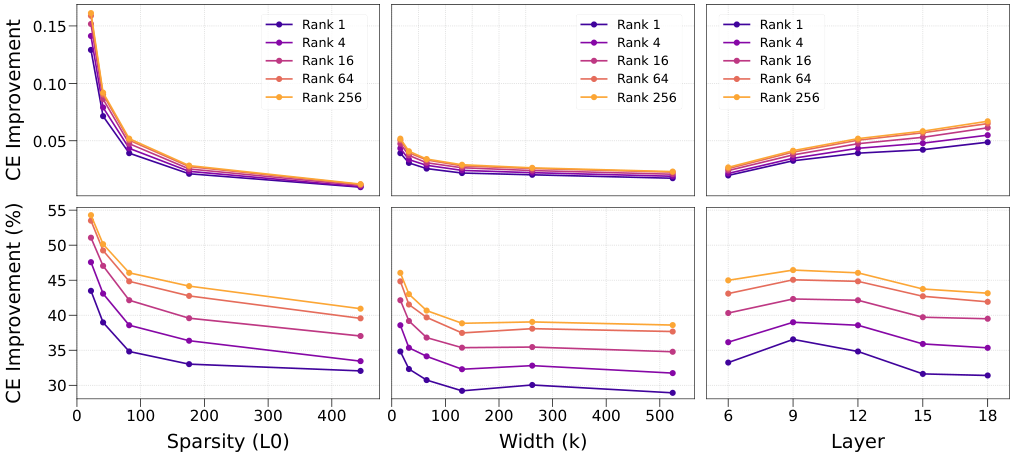
Experiments spanned the Gemma Scope family of SAEs across varying SAE width, sparsity level, model size (up to 27B parameters), LoRA rank, and insertion layer. Results were consistent: LoRA-adapted models degrade far less from SAE insertion than unmodified ones. The gains are largest in low-sparsity regimes, precisely the settings where SAEs activate the fewest features per token. These tend to be the most scientifically interesting for studying rare or nuanced concepts.
Why It Matters
Mechanistic interpretability researchers often insert multiple SAEs into different layers simultaneously to trace how information flows through a network, a technique called circuit analysis. Every insertion compounds the performance penalty, making multi-SAE studies increasingly unreliable.
The LoRA approach addresses this directly. Experiments on Llama-3.1-8B show that adapting the model around multiple simultaneously-inserted SAEs produces large drops in cross-entropy loss (a standard measure of how accurately a model predicts the next word), opening the door to more ambitious interpretability experiments without sacrificing model fidelity.
The prevailing assumption in interpretability has been that the language model is a fixed object to be studied, and all improvements must come from better measurement tools. That assumption doesn’t quite hold.
Model and interpretability tools can be co-optimized through lightweight post-hoc adaptation, without training from scratch or running expensive concurrent training. Better interpretability doesn’t require accepting worse performance.
There are also direct implications for AI safety. SAEs are increasingly used to detect and understand dangerous or deceptive model behaviors. If SAE insertion significantly degrades a model’s capabilities, it compromises the fidelity of those safety analyses. A model that runs well with its SAEs in place is a more honest subject of study.
Bottom Line: Adapting the model to its own interpretability tools achieves a 30–55% reduction in the performance cost of SAE-based analysis, up to 20× faster than the best competing method. Model optimization and interpretability are not in tension; they can be jointly improved.
IAIFI Research Highlights
This work advances mechanistic interpretability using techniques from efficient fine-tuning, showing how ML engineering insights can directly accelerate scientific understanding of AI systems.
The LoRA SAE training method reduces the performance cost of sparse autoencoder insertion by 30–55% and achieves results comparable to end-to-end SAEs up to 20× faster, making large-scale interpretability studies substantially more tractable.
By enabling reliable multi-layer SAE insertion, this technique opens new pathways for tracing information flow through transformer circuits, a key step toward understanding how language models encode structured knowledge, with parallels to how physicists trace causal pathways in complex systems.
Future directions include extending LoRA SAE training to larger model families and exploring whether adapted models reveal qualitatively different features than unmodified ones; the paper appears at ICML 2025 (Proceedings of the 42nd International Conference on Machine Learning). [[arXiv:2501.19406](https://arxiv.org/abs/2501.19406)]