
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
Authors
Matthew Ho, Deaglan J. Bartlett, Nicolas Chartier, Carolina Cuesta-Lazaro, Simon Ding, Axel Lapel, Pablo Lemos, Christopher C. Lovell, T. Lucas Makinen, Chirag Modi, Viraj Pandya, Shivam Pandey, Lucia A. Perez, Benjamin Wandelt, Greg L. Bryan
Abstract
This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schemata, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable and is designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterizing progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
Concepts
The Big Picture
Imagine you’re a detective, but instead of a crime scene, your evidence is a blurry X-ray image of a galaxy cluster, or a faint ripple in spacetime. The “crime” you’re solving is the underlying physics: the mass of that cluster, or the masses of the black holes that collided billions of years ago. Traditional science approaches this by writing down an exact formula for how the evidence should look if a particular theory is true. But what if the universe is too complicated for that formula to exist?
That’s the wall modern astrophysics keeps hitting. Telescopes like the Rubin Observatory and space missions like Euclid are about to flood researchers with petabytes of data, and the old approach of hand-crafting exact prediction formulas can’t keep up. Some physical processes are just too messy. The turbulent collapse of dark matter halos, the tangled magnetic fields inside galaxy clusters: no clean mathematical description exists for any of it. The gap between what we can simulate on a computer and what we can write down as an equation has never been wider.
A team of fifteen researchers from institutions in Paris, New York, Cambridge, and elsewhere built a tool to close that gap: the Learning the Universe Implicit Likelihood Inference pipeline, or LtU-ILI. It’s a unified, open-source software framework that lets scientists train machine learning models to draw statistical conclusions directly from simulations, no prediction formula required.
Key Insight: LtU-ILI packages state-of-the-art simulation-based inference into a single, accessible pipeline, making it possible for any researcher to extract Bayesian posteriors from complex astronomical data without writing down a single analytic likelihood.
How It Works
The core idea behind LtU-ILI is Implicit Likelihood Inference (ILI), also called simulation-based inference or likelihood-free inference. Instead of deriving a formula for how likely your observations are given a model, you train a neural network to learn that relationship from thousands of simulated examples. Feed it enough pairs of (simulation inputs, simulation outputs), and the network learns to invert the process: given new observations, it produces a full probability distribution over the underlying parameters. This distribution, called the posterior, is the central goal of Bayesian statistical inference. It’s a map of which parameter values are plausible and how plausible each one is.
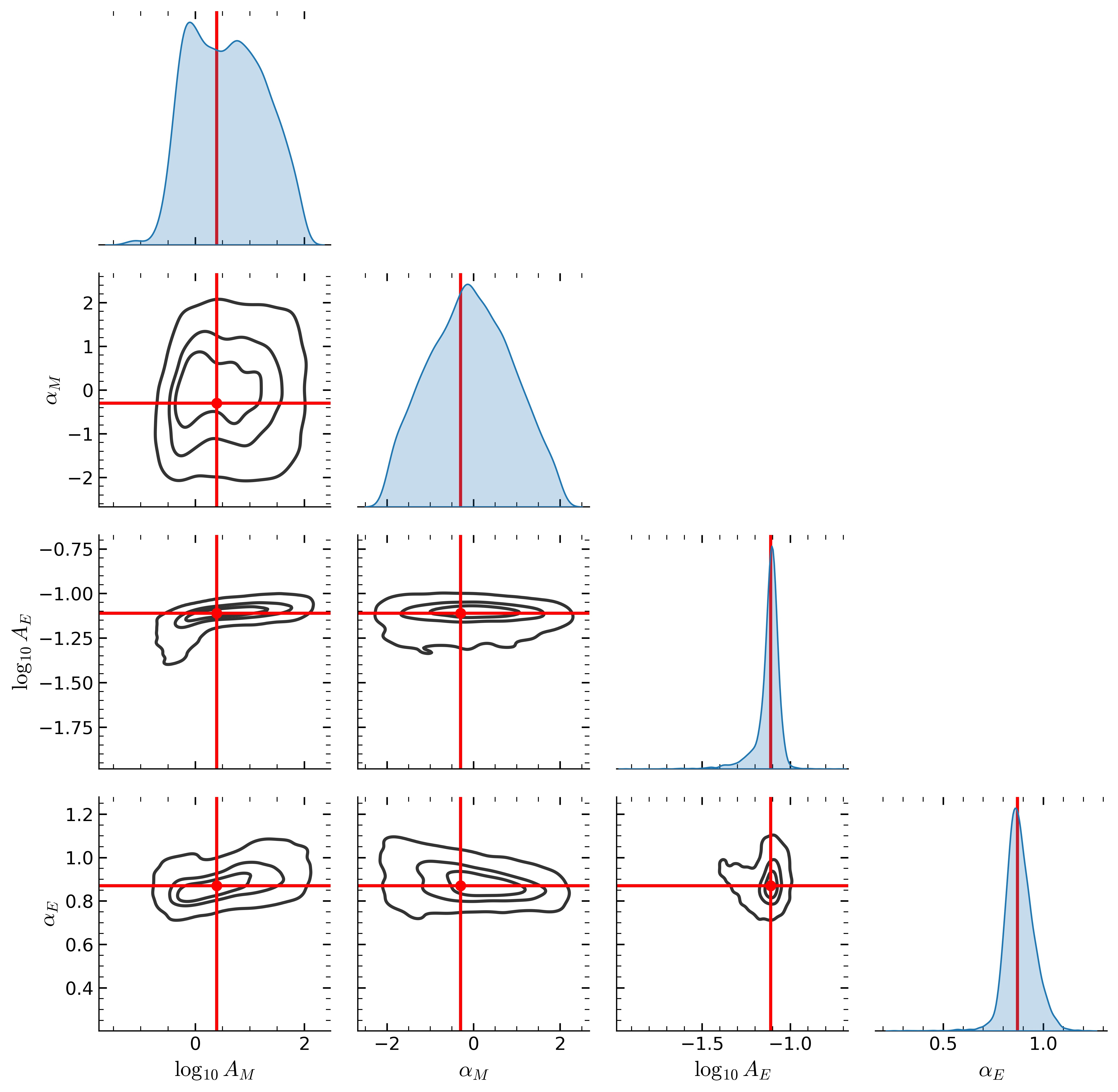
The pipeline is modular. Researchers can swap in different neural architectures, different density estimators (the mathematical machinery representing probability distributions), and different training strategies. The three main approaches are:
- Neural Posterior Estimation (NPE): Train a network to directly output the posterior distribution.
- Neural Likelihood Estimation (NLE): Train a network to learn the likelihood, then sample the posterior using MCMC, a standard algorithm that explores a probability distribution by taking many small random steps.
- Neural Ratio Estimation (NRE): Train a classifier to distinguish real parameter-data pairs from fake ones, using its output as a proxy for the likelihood ratio.
Each method has different strengths. NPE is fast at inference time. NLE handles complex posteriors well. NRE works even when simulations are expensive. LtU-ILI lets you run all three and compare.
Raw inference isn’t enough, though. A posterior that looks confident can still be wrong. LtU-ILI bakes in validation metrics, including simulation-based calibration (SBC) tests that check whether the pipeline’s credible intervals actually deliver on their promise. If your 90% credible interval only captures the truth 60% of the time, you’ve got a problem, and LtU-ILI will flag it.
The team tested the pipeline on five real astrophysics problems: galaxy cluster masses from X-ray photometry, cosmological parameters from matter power spectra and dark matter halo point clouds, gravitational wave signals from merging black holes and neutron stars, dust physics from galaxy colors, and semi-analytic models of galaxy formation. In each case, they benchmarked multiple ILI methods head-to-head, which is uncommon in a field where methods are usually tested in isolation.
Why It Matters
Next-generation surveys like Rubin and Euclid need inference pipelines that are fast, scalable, and scientifically reliable. Traditional MCMC methods can take days or weeks to converge on a single posterior. A trained ILI network produces posteriors in seconds. The catch has always been trust: how do you know the network learned the right distribution? LtU-ILI’s validation suite tackles this head-on, making it possible to certify a neural posterior estimator before deploying it on real data.
The challenges the authors document (model misspecification, hyperparameter sensitivity, epistemic uncertainty) aren’t unique to astrophysics. They’re universal problems for anyone deploying ML models where ground truth is scarce and stakes are high. The pipeline’s modular design, with its emphasis on systematic testing and built-in validation, could serve as a blueprint for trustworthy inference tools in other fields too. The code is publicly available, and the authors designed it so that a researcher unfamiliar with neural networks can get a working pipeline running with minimal friction.
Bottom Line: LtU-ILI gives astrophysicists a plug-and-play toolkit for machine-learning-powered Bayesian inference, and its open design means the next generation of cosmic surveys won’t have to start from scratch every time they face a new inference problem.
IAIFI Research Highlights
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
2402.05137
["Matthew Ho", "Deaglan J. Bartlett", "Nicolas Chartier", "Carolina Cuesta-Lazaro", "Simon Ding", "Axel Lapel", "Pablo Lemos", "Christopher C. Lovell", "T. Lucas Makinen", "Chirag Modi", "Viraj Pandya", "Shivam Pandey", "Lucia A. Perez", "Benjamin Wandelt", "Greg L. Bryan"]
This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schemata, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable and is designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterizing progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.