
Machine-Learning media bias
Authors
Samantha D'Alonzo, Max Tegmark
Abstract
We present an automated method for measuring media bias. Inferring which newspaper published a given article, based only on the frequencies with which it uses different phrases, leads to a conditional probability distribution whose analysis lets us automatically map newspapers and phrases into a bias space. By analyzing roughly a million articles from roughly a hundred newspapers for bias in dozens of news topics, our method maps newspapers into a two-dimensional bias landscape that agrees well with previous bias classifications based on human judgement. One dimension can be interpreted as traditional left-right bias, the other as establishment bias. This means that although news bias is inherently political, its measurement need not be.
Concepts
The Big Picture
Imagine you’re handed a random newspaper clipping with no masthead, no byline, no date. Could you tell just from the words whether it came from Fox News or MSNBC? From a scrappy independent outlet or an establishment broadsheet? Most people could take a reasonable guess, and it turns out a machine can too, with surprising accuracy.
Political polarization is accelerating across the United States and internationally, and a growing body of research points to media as a key driver. Yet measuring media bias objectively has long been a thorny problem: any person or organization tasked with judging bias is themselves subject to accusations of the same. Fact-checkers get called partisan. Bias-raters get dismissed.
Researchers Samantha D’Alonzo and Max Tegmark at MIT’s Department of Physics and IAIFI offer a simple idea: let the language itself reveal the bias. They use machine learning (software that learns patterns in data without explicit programming) to discover structure that no human pre-labeled.
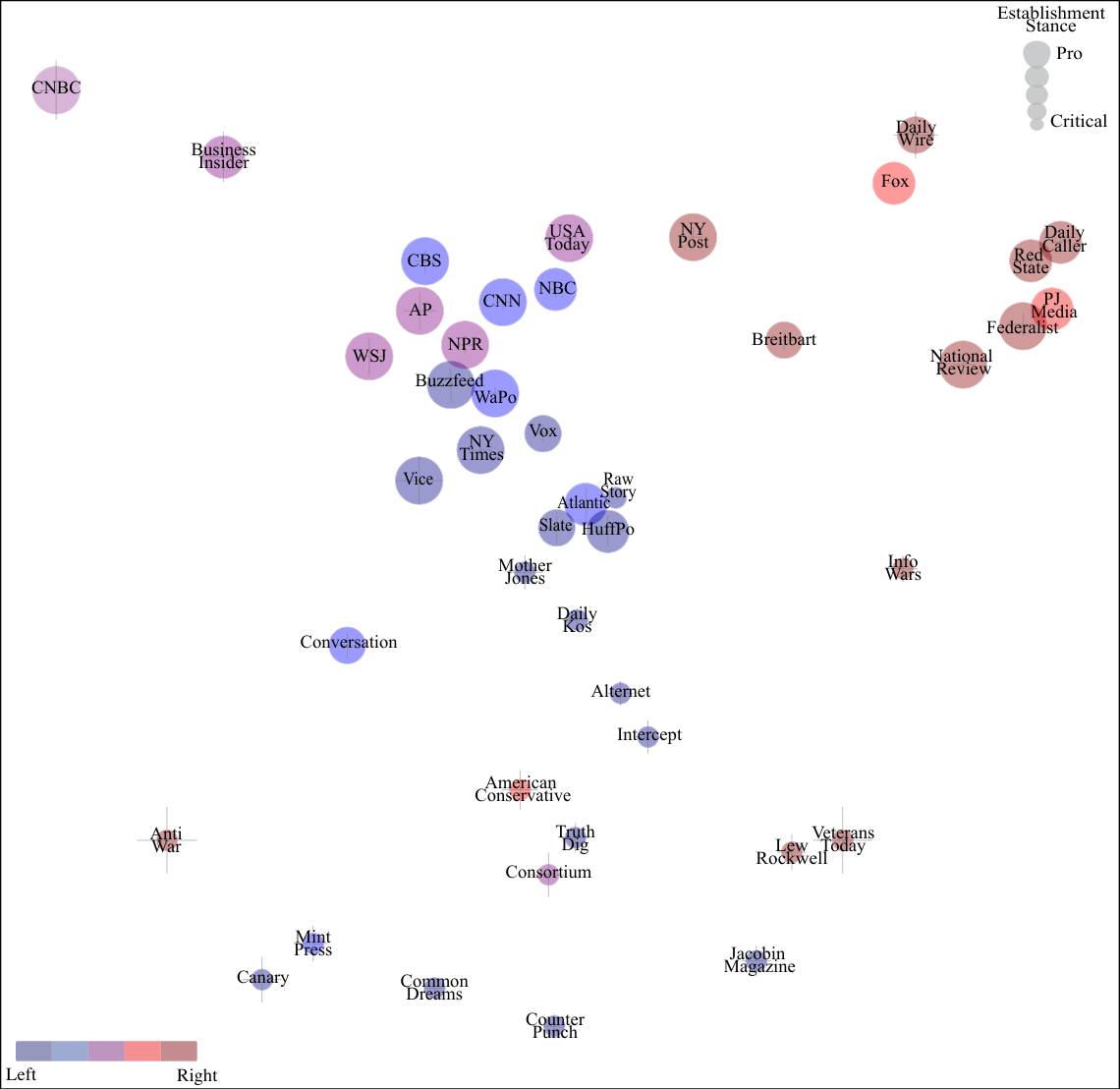
Key Insight: By training a model to predict which newspaper published an article based purely on phrase frequencies, the researchers automatically uncovered a two-dimensional bias map, capturing both left-right and establishment dimensions, that matches human expert classifications without ever asking for human opinion.
How It Works
The core method is elegant. Take roughly a million articles from about a hundred newspapers. For each article, don’t analyze topic, sentiment, or meaning in any deep sense. Just count phrases.
Consider how newspapers diverge on politically charged word choices:
- “Undocumented immigrant” vs. “illegal immigrant”
- “Demonstrators” vs. “rioters”
- “Estate tax” vs. “death tax”
These phrase frequency signatures, numerical fingerprints of which words appear and how often, become the raw material the algorithm learns from.
The team frames the problem as a classification task: given an article’s phrase counts, predict which of the ~100 newspapers published it. But they don’t actually care about getting the classification right. What matters is the conditional probability distribution, the underlying statistical patterns the model builds to distinguish one newspaper from another. Those learned patterns are themselves the signal about bias.
Technically, the method centers on a generalized Singular Value Decomposition (SVD), a mathematical technique that compresses thousands of phrase-count columns down to just two or three key dimensions. Standard SVD fails here for two reasons: it can produce nonsensical negative phrase counts, and it treats all observations equally even when some phrase counts are measured far more precisely than others.
D’Alonzo and Tegmark instead maximize a Poisson likelihood, a statistically principled choice since word counts are discrete events, exactly what the Poisson distribution was designed to model. The method tests two parameterizations (a ReLU, which floors negative values to zero, and an exponential form) and selects whichever fits the data better.
The algorithm then maps both newspapers and phrases into a low-dimensional bias space, a compact coordinate system where publications with similar language habits cluster together. No human tells it what the axes mean; it discovers structure from the data alone. When the researchers examine those axes, one maps cleanly onto the traditional left-right political spectrum. The other captures what they call establishment bias: how much a publication aligns with or challenges mainstream institutional narratives, independent of left-right positioning.
Why It Matters
Here’s what’s striking: this purely data-driven method recovers the same two-dimensional structure that human experts have identified through years of careful qualitative analysis. Left-right bias and establishment bias emerge not because the researchers encoded those categories, but because those are genuinely the dominant axes along which newspapers differ in their word choices. The machine didn’t need to be told about politics. Politics showed up anyway, baked into the language.
This result points toward real-time, scalable, transparent bias monitoring. Because the method is fully automated and relies only on publicly available text, it can be applied to new outlets, new topics, and new time periods without any additional human labeling. The team analyzes dozens of distinct news topics and finds that biases are correlated across them in consistent ways, which is precisely what allows the two-dimensional structure to emerge at all.
Natural extensions include other languages, tracking how newspaper bias shifts over time, and applying similar techniques to social media, political speeches, or corporate press releases.
Bottom Line: Machine learning can measure media bias from phrase statistics alone, no human labels required. The resulting bias map matches expert classifications while being far more scalable and transparent than any human-driven alternative.
IAIFI Research Highlights
This work applies physics-inspired mathematical tools (Poisson likelihood maximization and generalized SVD) to a social science problem, bringing quantitative rigor from physics to bear on the study of media institutions.
The paper introduces a scalable, unsupervised NLP method that discovers interpretable bias dimensions directly from a million-article corpus, with no hand-crafted features or human-labeled training data.
Political polarization structures (left-right and establishment axes) emerge automatically from language statistics, contributing to a quantitative understanding of how information ecosystems shape society.
Future extensions could track bias evolution over time or across languages; the paper is available at [arXiv:2109.00024](https://arxiv.org/abs/2109.00024) with open-source tools for reproducible bias measurement.