
MARVEL: A Multi Agent-based Research Validator and Enabler using Large Language Models
Authors
Nikhil Mukund, Yifang Luo, Fan Zhang, Lisa Barsotti, Erik Katsavounidis
Abstract
We present MARVEL (https://ligogpt.mit.edu/marvel), a locally deployable, open-source framework for domain-aware question answering and assisted scientific research. It is designed to address the increasing demands of a digital assistant for scientific groups that can read highly technical data, cite precisely, and operate within authenticated networks. MARVEL combines a fast path for straightforward queries with a more deliberate DeepSearch mode that integrates retrieval-augmented generation and Monte Carlo Tree Search. It explores complementary subqueries, allocates more compute to promising branches, and maintains a global evidence ledger that preserves sources during drafting. We applied this framework in the context of gravitational-wave research related to the Laser Interferometer Gravitational-wave Observatory. Answers are grounded in a curated semantic index of research literature, doctoral theses, LIGO documents, and long-running detector electronic logbooks, with targeted web searches when appropriate. Because direct benchmarking against commercial LLMs cannot be performed on private data, we evaluated MARVEL on two publicly available surrogate datasets that capture comparable semantic and technical characteristics. On these benchmarks, MARVEL matches a GPT-4o mini baseline on literature-centric queries and substantially outperforms it on detector-operations content, where domain retrieval and guided reasoning are decisive. By making the complete framework and evaluation datasets openly available, we aim to provide a reproducible foundation for developing domain-specific scientific assistants.
Concepts
The Big Picture
Imagine joining one of the most complex scientific collaborations on Earth: the LIGO gravitational-wave observatory. Your job spans a thousand interlocking systems. Laser optics, vibration isolation, digital control systems, decades of detector logs. The institutional knowledge you need is scattered across hundreds of thousands of documents: technical reports, PhD theses, electronic logbooks from two detector sites, a mountain of published literature. Where do you even start?
This is the daily reality for LIGO researchers. The collaboration has detected more than 300 gravitational-wave events (ripples in spacetime from colliding black holes and neutron stars) since its landmark first detection in 2015. People rotate between roles, expertise walks out the door, and the knowledge base keeps growing. A new researcher asking “why did the detector glitch last Tuesday?” might need to trace years of logbook entries written by engineers who’ve long since moved on.
The bottleneck isn’t intelligence. It’s finding the right information at all.
Researchers at MIT’s Kavli Institute and IAIFI have built MARVEL, a locally deployable AI assistant that doesn’t just search this knowledge base but reasons through it, citing sources precisely, handling technical jargon fluently, and allocating its own computational effort to the hardest questions.
Key Insight: MARVEL combines retrieval-augmented generation with Monte Carlo Tree Search to give scientific collaborations a domain-expert AI assistant that operates on private, institutional knowledge, not just publicly available data.
How It Works
MARVEL routes every incoming query along one of two tracks based on complexity. Straightforward factual questions take a fast path: rapid retrieval and synthesis. Harder queries (multi-step reasoning, conflicting sources, deeply technical detector operations) trigger a DeepSearch mode.
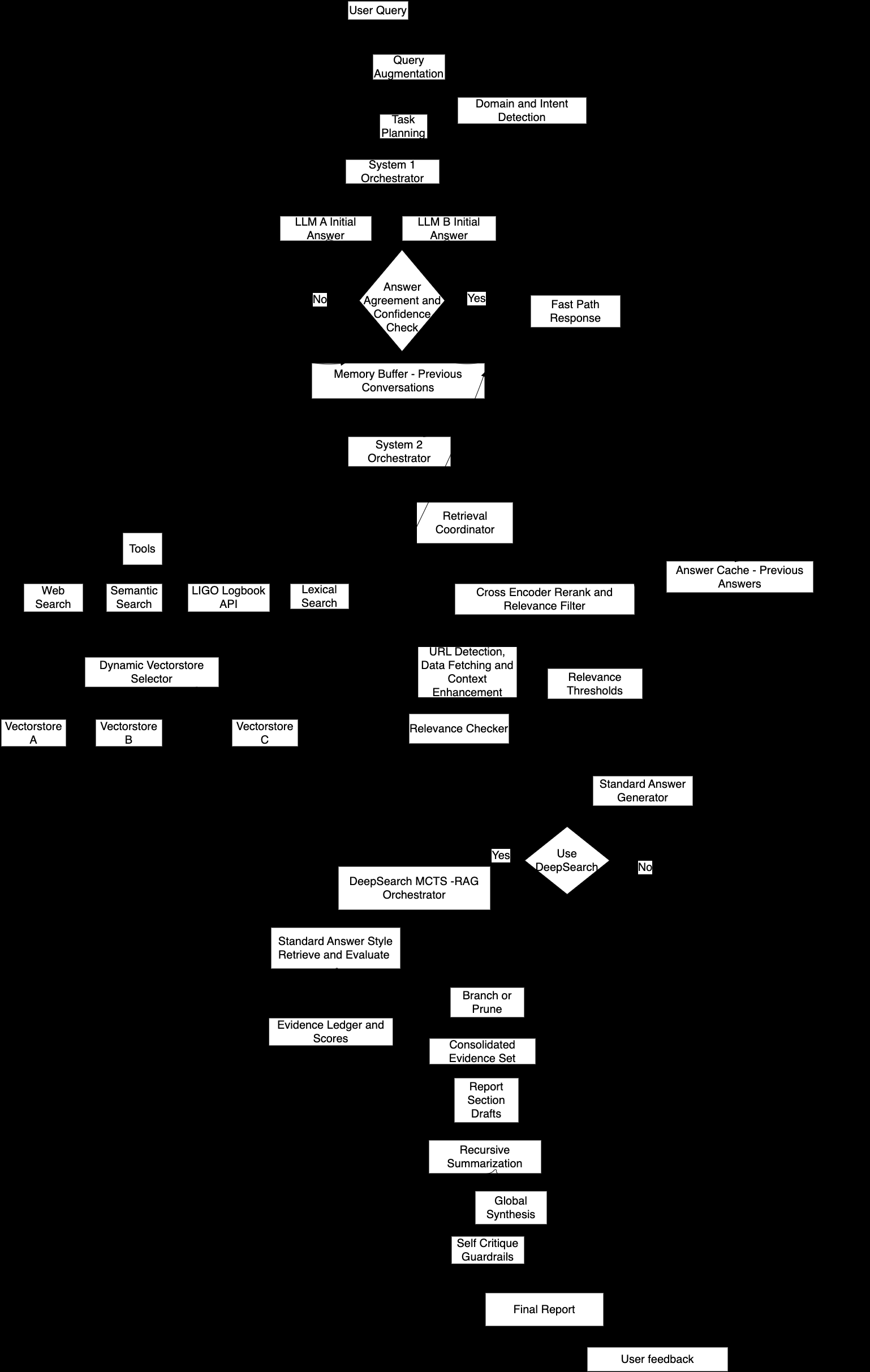
DeepSearch is where things get interesting. It uses Monte Carlo Tree Search (MCTS), an algorithm best known from game-playing AI like AlphaGo, repurposed here for scientific reasoning. Rather than exhaustively exploring every line of investigation, MCTS lets MARVEL probe multiple sub-questions simultaneously, then concentrate effort on the branches turning up real evidence. Think of it as a detective who pursues several leads at once, then doubles down on the ones that pay off.
The retrieval layer draws from a curated semantic index (a database organized by meaning, not just keywords) built from four source types:
- Published arXiv papers and preprints
- Doctoral theses from LIGO-affiliated researchers
- Internal LIGO technical documents
- Detector electronic logbooks
When those sources fall short, MARVEL triggers targeted web searches to fill gaps. It maintains a running evidence ledger throughout, recording every source consulted and every claim grounded, so the final answer arrives with full citation provenance.
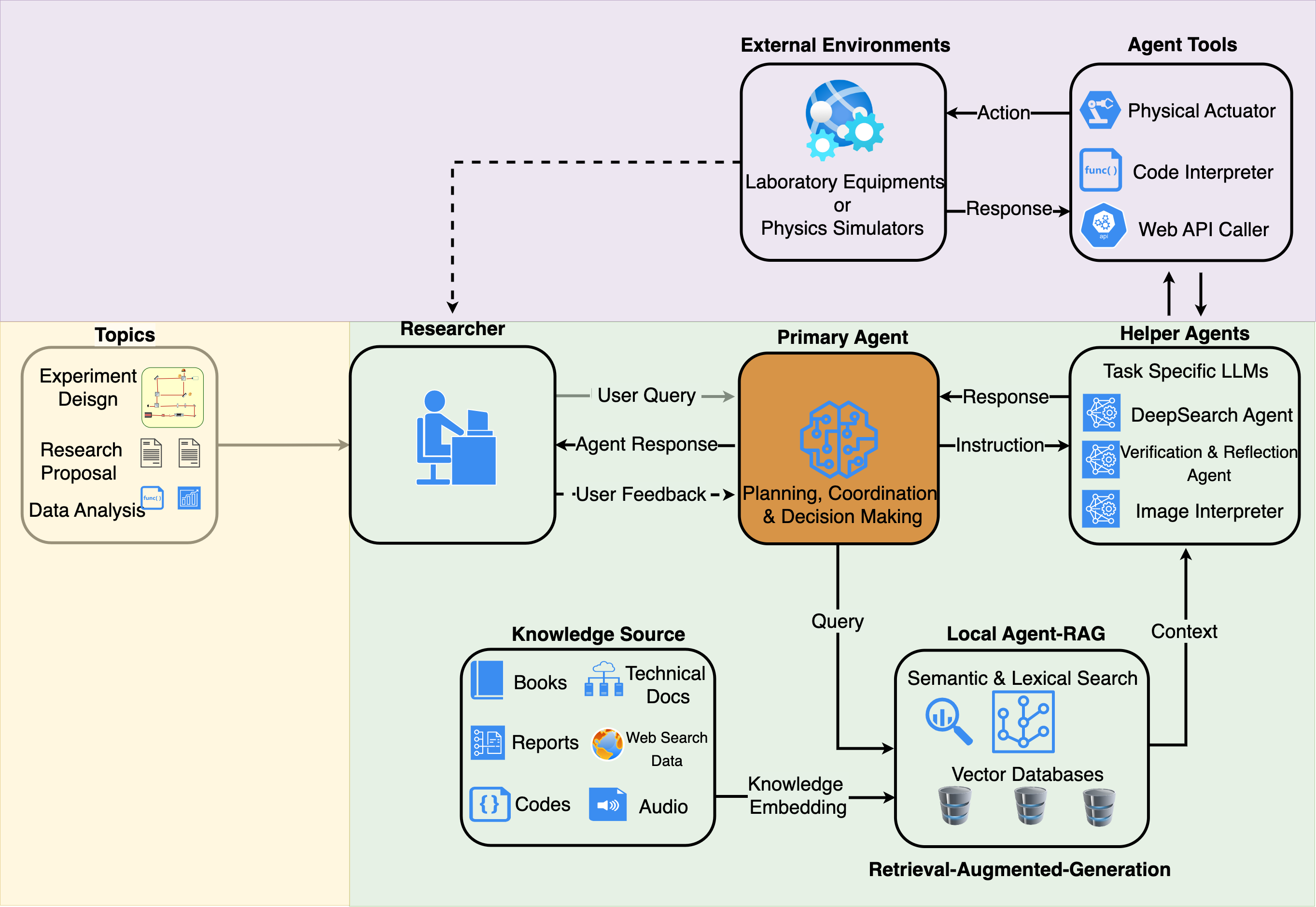
The whole system runs on open-weight language models (AI systems whose parameters are publicly available, unlike proprietary services like GPT-4) rather than commercial APIs. That means it operates entirely within an institution’s private network. For collaborations handling sensitive engineering data or proprietary experimental results, this is a big deal.
Why It Matters
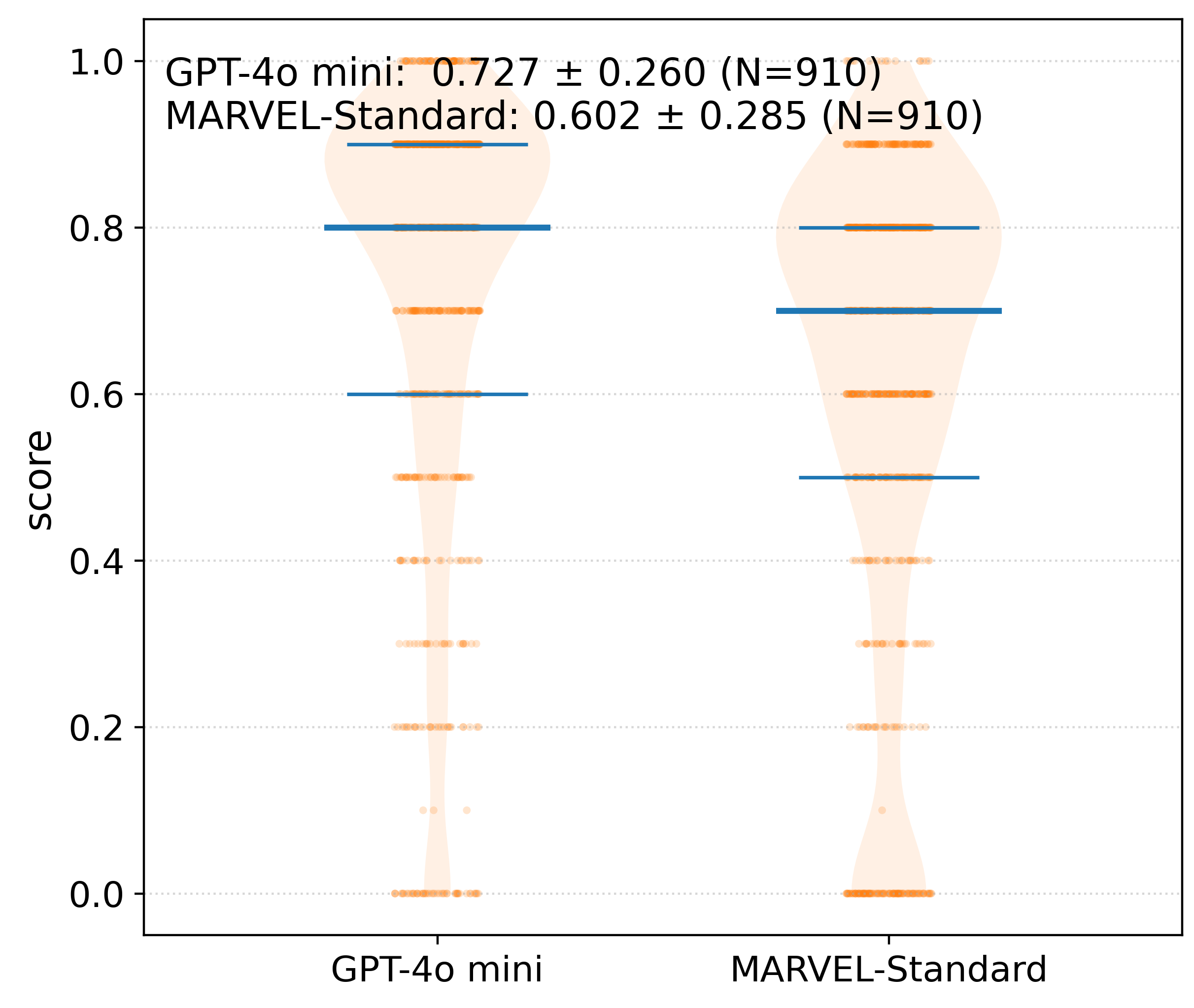
Benchmarking a system trained on private institutional data is tricky: there’s no shared test set to compare against public models. The team’s solution was to construct two surrogate datasets with comparable semantic and technical characteristics to LIGO’s internal documents. One was drawn from published scientific literature, the other mirrored the operational, log-style content of detector logbooks.
On literature-centric queries, MARVEL matches a GPT-4o mini baseline. On detector-operations content, the messy, domain-specific material that constitutes the real working knowledge of a gravitational-wave observatory, it substantially outperforms it. This is exactly where domain-specific retrieval and guided reasoning pay off: when the answer lives in a logbook entry from three years ago, written in engineering shorthand, that no general-purpose model has ever seen.
The implications reach beyond LIGO. Every large scientific collaboration, whether in particle physics, astronomy, or genomics, generates vast institutional knowledge that gradually becomes inaccessible as people and projects move on. The default response has been to reach for commercial AI tools, which are powerful but operate on public data, can’t be customized to specific document collections, and require sending sensitive information off-site.
MARVEL offers something different: a reproducible, open-source framework where scientific groups control their own knowledge base, their own models, and their own reasoning pipeline. Adapting it to a new domain requires swapping datasets and adjusting prompts, not rebuilding from scratch. The full framework and evaluation datasets are publicly available.
Open questions remain. How does MCTS-guided reasoning scale as knowledge bases grow to millions of documents? How should the system handle contradictory information from different time periods in a logbook? How do you maintain benchmark validity as private institutional data evolves? These are hard problems, and they’ll shape the next generation of scientific AI assistants.
Bottom Line: MARVEL shows that domain-specific AI assistants, built on private institutional knowledge and guided by tree-search reasoning, can outperform general-purpose commercial LLMs on the queries that matter most for working scientists. Its open-source release gives every major collaboration the tools to build their own.
IAIFI Research Highlights
MARVEL applies Monte Carlo Tree Search, a technique from game-playing AI, to scientific question answering over LIGO's decades of detector engineering knowledge, connecting AI systems research directly with gravitational-wave physics.
The work introduces a compute-aware DeepSearch mode that strategically allocates LLM inference across promising reasoning branches, outperforming GPT-4o mini on technical operational content.
By making LIGO's dispersed institutional knowledge (logbooks, theses, technical documents) accessible through intelligent retrieval, MARVEL supports the operation of instruments studying the universe's most extreme events.
Future extensions could apply the framework to other large physics collaborations and improve handling of temporally evolving knowledge bases. The paper is available at [arXiv:2601.03436](https://arxiv.org/abs/2601.03436), and the live system at [ligogpt.mit.edu/marvel](https://ligogpt.mit.edu/marvel).
Original Paper Details
MARVEL: A Multi Agent-based Research Validator and Enabler using Large Language Models
[2601.03436](https://arxiv.org/abs/2601.03436)
Nikhil Mukund, Yifang Luo, Fan Zhang, Lisa Barsotti, Erik Katsavounidis
We present MARVEL (https://ligogpt.mit.edu/marvel), a locally deployable, open-source framework for domain-aware question answering and assisted scientific research. It is designed to address the increasing demands of a digital assistant for scientific groups that can read highly technical data, cite precisely, and operate within authenticated networks. MARVEL combines a fast path for straightforward queries with a more deliberate DeepSearch mode that integrates retrieval-augmented generation and Monte Carlo Tree Search. It explores complementary subqueries, allocates more compute to promising branches, and maintains a global evidence ledger that preserves sources during drafting. We applied this framework in the context of gravitational-wave research related to the Laser Interferometer Gravitational-wave Observatory. Answers are grounded in a curated semantic index of research literature, doctoral theses, LIGO documents, and long-running detector electronic logbooks, with targeted web searches when appropriate. Because direct benchmarking against commercial LLMs cannot be performed on private data, we evaluated MARVEL on two publicly available surrogate datasets that capture comparable semantic and technical characteristics. On these benchmarks, MARVEL matches a GPT-4o mini baseline on literature-centric queries and substantially outperforms it on detector-operations content, where domain retrieval and guided reasoning are decisive. By making the complete framework and evaluation datasets openly available, we aim to provide a reproducible foundation for developing domain-specific scientific assistants.