
Maven: A Multimodal Foundation Model for Supernova Science
Authors
Gemma Zhang, Thomas Helfer, Alexander T. Gagliano, Siddharth Mishra-Sharma, V. Ashley Villar
Abstract
A common setting in astronomy is the availability of a small number of high-quality observations, and larger amounts of either lower-quality observations or synthetic data from simplified models. Time-domain astrophysics is a canonical example of this imbalance, with the number of supernovae observed photometrically outpacing the number observed spectroscopically by multiple orders of magnitude. At the same time, no data-driven models exist to understand these photometric and spectroscopic observables in a common context. Contrastive learning objectives, which have grown in popularity for aligning distinct data modalities in a shared embedding space, provide a potential solution to extract information from these modalities. We present Maven, the first foundation model for supernova science. To construct Maven, we first pre-train our model to align photometry and spectroscopy from 0.5M synthetic supernovae using a constrastive objective. We then fine-tune the model on 4,702 observed supernovae from the Zwicky Transient Facility. Maven reaches state-of-the-art performance on both classification and redshift estimation, despite the embeddings not being explicitly optimized for these tasks. Through ablation studies, we show that pre-training with synthetic data improves overall performance. In the upcoming era of the Vera C. Rubin Observatory, Maven serves as a Rosetta Stone for leveraging large, unlabeled and multimodal time-domain datasets.
Concepts
The Big Picture
Imagine trying to identify a bird species from its shadow alone. You can make educated guesses based on the silhouette and wingbeat, but you’re missing the colors, the markings, the call. Now imagine that for every detailed photograph in a field guide, there are ten thousand shadows. That’s the situation astronomers face with supernovae.
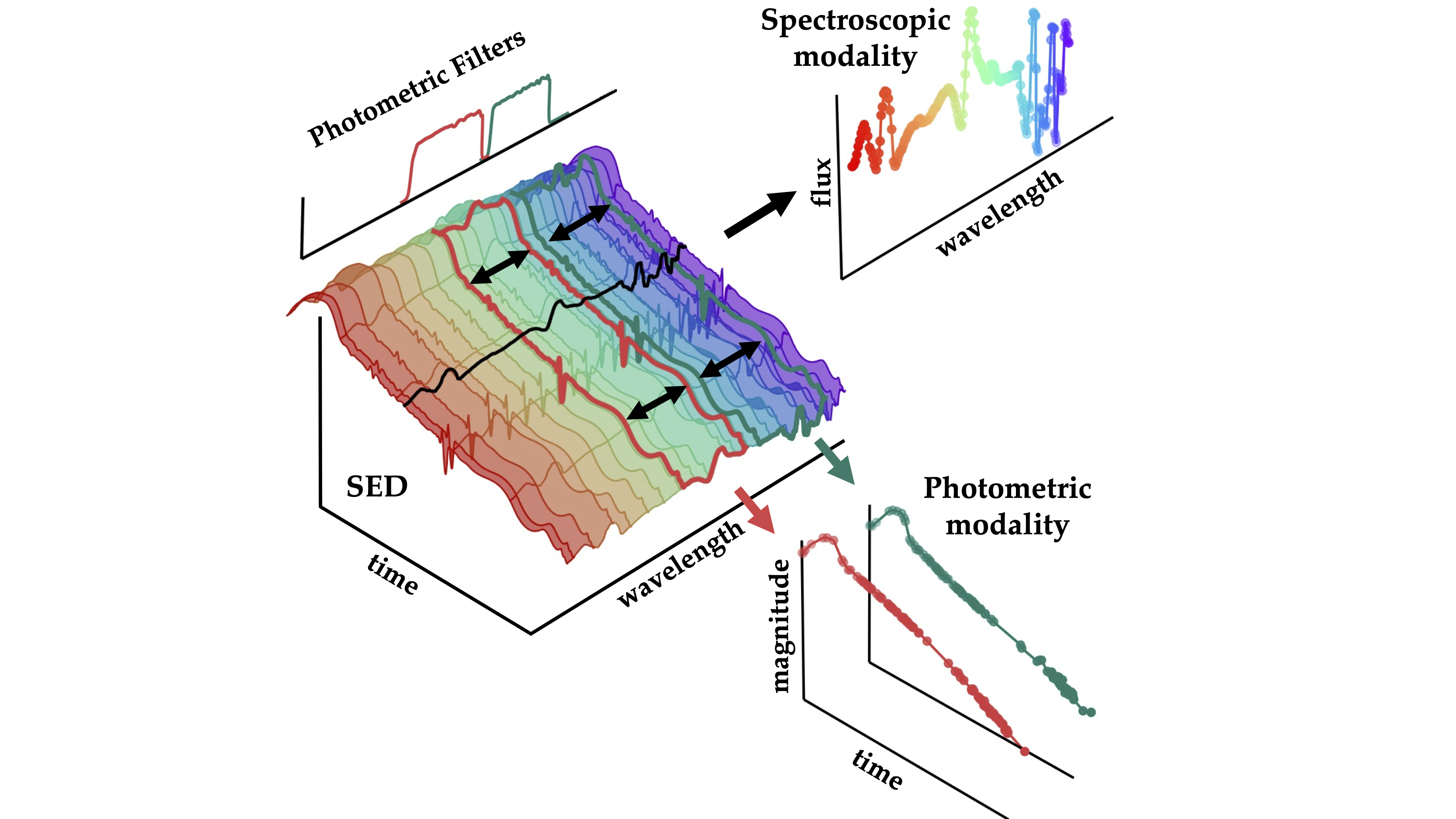
When a massive star explodes, it broadcasts information in two complementary ways. Photometry measures brightness through different color filters over time. It’s like watching a shadow: relatively easy to collect, but limited in detail. Spectroscopy spreads light into its individual wavelengths to read chemical fingerprints. It’s vastly more informative, but capturing it requires precious telescope time and sophisticated instruments.
Photometric observations outnumber spectroscopic ones by factors of hundreds or thousands. The Vera C. Rubin Observatory, now beginning its Legacy Survey of Space and Time (LSST), will discover over one million supernovae per year. Fewer than 1% will get spectroscopic follow-up.
A team from IAIFI, Harvard, MIT, and Stony Brook University has built Maven, the first foundation model for supernova science. It’s a large AI system trained broadly enough to be adapted to many different problems. Maven learns to speak both observational languages simultaneously and translate between them.
Key Insight: By training an AI to understand photometry and spectroscopy as two views of the same underlying explosion, Maven extracts far more information from either data type alone than previous single-modality models could achieve.
How It Works
Maven’s architecture draws on contrastive learning, the same family of techniques behind OpenAI’s CLIP model, which learned to match images with text by training on millions of image-caption pairs. The core idea: show a model many paired examples of two different representations of the same thing, and it learns a shared language for describing both.
For Maven, the “things” are supernovae, and the two representations are light curves and spectra. The team built two separate encoder networks (specialized neural networks that compress complex observations into compact numerical summaries) and trained them together. Embeddings from the same supernova should end up close together in a shared mathematical space, while embeddings from different supernovae drift apart. This joint embedding space becomes a conceptual map of the supernova population.
Training runs in two stages:
- Synthetic pre-training: Maven first learns from 500,000 simulated light curve-spectrum pairs generated from simplified physical models. Real paired observations are rare; synthetic ones are cheap to produce.
- Fine-tuning on real data: The pre-trained model is then refined on 4,702 observed supernovae from the Zwicky Transient Facility (ZTF), a wide-field survey that captures both photometry and spectroscopy for a subset of its detections.
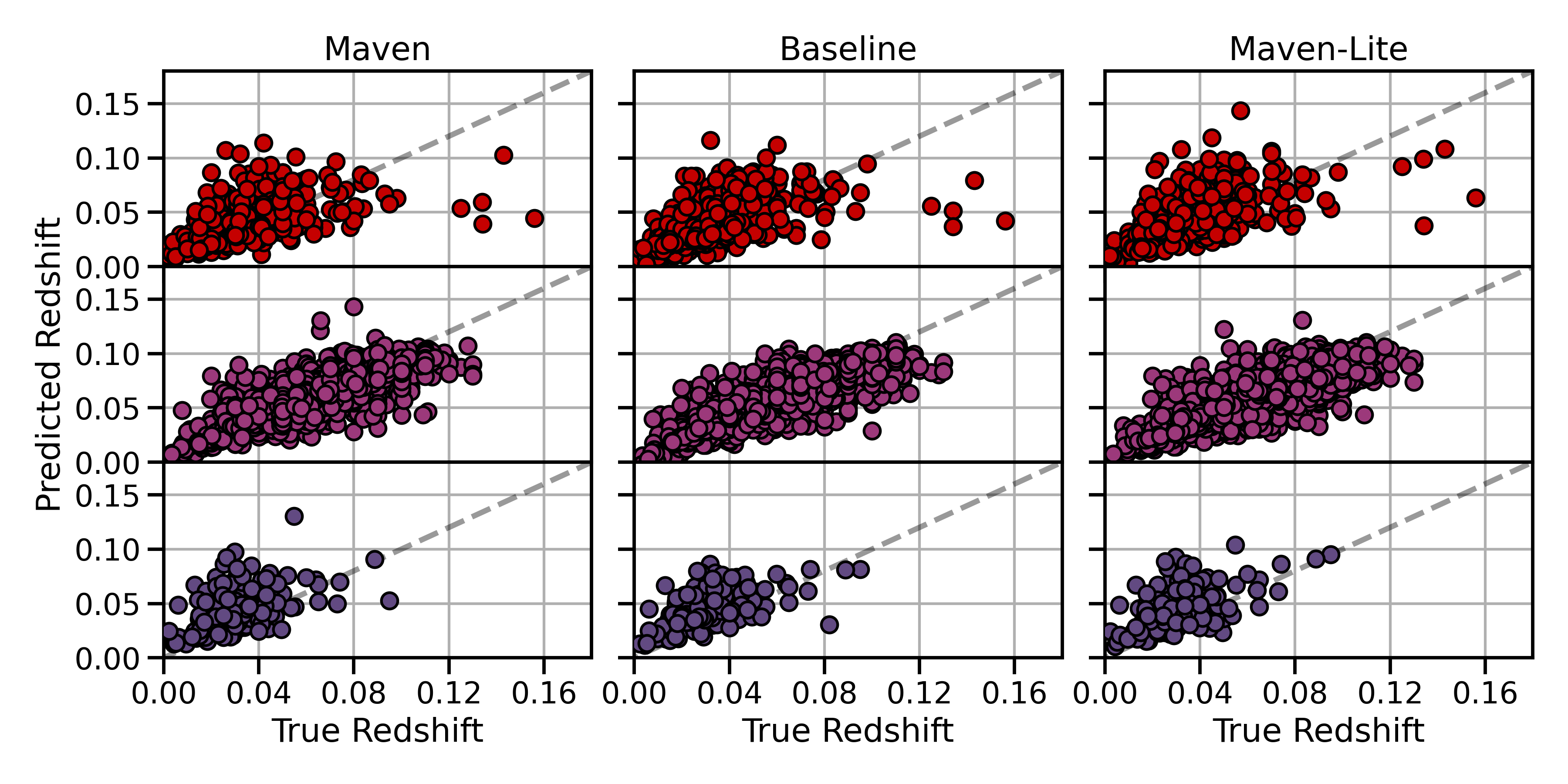
The researchers also trained Maven-lite, which skips synthetic pre-training and trains only on real ZTF data. This ablation study (a controlled experiment where one component is deliberately removed to measure its contribution) quantifies exactly how much value the synthetic stage adds. Maven consistently outperforms Maven-lite, showing that even imperfect simulations teach the model something real about the physics.
Once trained, Maven’s embeddings encode physically meaningful information without ever being told to optimize for any particular task. On two standard benchmarks, supernova type classification (distinguishing thermonuclear Type Ia explosions from core-collapse events) and photometric redshift estimation (inferring how far away a supernova is from photometry alone), Maven reaches state-of-the-art performance. Neither task was directly optimized during training. The embeddings just naturally capture the relevant physics.
Why It Matters
LSST will transform time-domain astronomy with sheer, overwhelming scale. But you can’t hand-classify a million supernovae per year, and you can’t schedule spectroscopic follow-up for more than a tiny fraction. The field needs automated tools that extract science from photometry alone, ideally informed by whatever spectroscopic knowledge already exists.
Maven is a prototype for exactly that kind of tool. Because the model’s embeddings are general-purpose, not locked to a single task, the same trained model can in principle be adapted to redshift estimation, classification, anomaly detection, or physics inference problems that haven’t been invented yet. The authors describe Maven as a “Rosetta Stone” for the LSST era: a shared representational framework that allows the small reservoir of spectroscopic knowledge to inform analysis of the vast photometric flood.
The approach also extends well beyond supernovae. Any astronomical domain facing a similar imbalance between data-rich and data-scarce observation types could benefit from the same contrastive pre-training strategy.
Bottom Line: Contrastive learning between photometry and spectroscopy produces embeddings that encode supernova physics without task-specific training. As the Vera C. Rubin Observatory floods the field with millions of photometric detections per year, this kind of scalable, multimodal approach will be essential.
IAIFI Research Highlights
Maven applies contrastive representation learning, a technique developed for natural language and image alignment, directly to time-domain astrophysics.
Pre-training on large synthetic datasets meaningfully improves downstream performance on real scientific data, even when the simulations rely on simplified physical models. This is a broadly applicable strategy for data-scarce scientific domains.
Maven enables more accurate classification and redshift estimation of supernovae from photometry alone, improving our ability to use Type Ia supernovae as cosmological distance indicators and to characterize the diversity of core-collapse explosions.
With the Vera C. Rubin Observatory producing over a million supernova detections annually, Maven establishes the foundation for scalable, multimodal analysis of the coming data deluge; the full paper is available at [arXiv:2408.16829](https://arxiv.org/abs/2408.16829).
Original Paper Details
Maven: A Multimodal Foundation Model for Supernova Science
2408.16829
["Gemma Zhang", "Thomas Helfer", "Alexander T. Gagliano", "Siddharth Mishra-Sharma", "V. Ashley Villar"]
A common setting in astronomy is the availability of a small number of high-quality observations, and larger amounts of either lower-quality observations or synthetic data from simplified models. Time-domain astrophysics is a canonical example of this imbalance, with the number of supernovae observed photometrically outpacing the number observed spectroscopically by multiple orders of magnitude. At the same time, no data-driven models exist to understand these photometric and spectroscopic observables in a common context. Contrastive learning objectives, which have grown in popularity for aligning distinct data modalities in a shared embedding space, provide a potential solution to extract information from these modalities. We present Maven, the first foundation model for supernova science. To construct Maven, we first pre-train our model to align photometry and spectroscopy from 0.5M synthetic supernovae using a constrastive objective. We then fine-tune the model on 4,702 observed supernovae from the Zwicky Transient Facility. Maven reaches state-of-the-art performance on both classification and redshift estimation, despite the embeddings not being explicitly optimized for these tasks. Through ablation studies, we show that pre-training with synthetic data improves overall performance. In the upcoming era of the Vera C. Rubin Observatory, Maven serves as a Rosetta Stone for leveraging large, unlabeled and multimodal time-domain datasets.