
Metric Flows with Neural Networks
Authors
James Halverson, Fabian Ruehle
Abstract
We develop a general theory of flows in the space of Riemannian metrics induced by neural network gradient descent. This is motivated in part by recent advances in approximating Calabi-Yau metrics with neural networks and is enabled by recent advances in understanding flows in the space of neural networks. We derive the corresponding metric flow equations, which are governed by a metric neural tangent kernel, a complicated, non-local object that evolves in time. However, many architectures admit an infinite-width limit in which the kernel becomes fixed and the dynamics simplify. Additional assumptions can induce locality in the flow, which allows for the realization of Perelman's formulation of Ricci flow that was used to resolve the 3d Poincaré conjecture. We demonstrate that such fixed kernel regimes lead to poor learning of numerical Calabi-Yau metrics, as is expected since the associated neural networks do not learn features. Conversely, we demonstrate that well-learned numerical metrics at finite-width exhibit an evolving metric-NTK, associated with feature learning. Our theory of neural network metric flows therefore explains why neural networks are better at learning Calabi-Yau metrics than fixed kernel methods, such as the Ricci flow.
Concepts
The Big Picture
Imagine trying to find the perfect shape of a multidimensional space. Not a sphere or a donut, but a complex geometric object called a Calabi-Yau manifold, which string theorists believe describes the hidden extra dimensions of our universe. Mathematicians proved these objects exist, but nobody has ever written down an explicit formula for one. It’s like knowing a perfect sculpture exists inside a block of marble, with no chisel and no instructions.
For decades, physicists and mathematicians have tried to approximate these elusive Riemannian metrics, the mathematical rulers that measure distances and angles on curved spaces. Classical methods like Donaldson’s algorithm can get close, but they’re painfully slow. Neural networks cracked that barrier: a modern laptop running the right network can match results that used to require far more computation. But why neural networks work so much better has remained mysterious.
James Halverson and Fabian Ruehle at Northeastern University and IAIFI have now developed a complete mathematical theory explaining how neural networks flow through the space of geometric metrics. Their framework unifies deep learning theory with the mathematics of curved spaces, and it reveals why neural networks beat classical approaches like Ricci flow, a technique that smooths out geometric irregularities the way heat spreads through a material.
Key Insight: Neural networks learn Calabi-Yau metrics better than fixed-kernel methods like Ricci flow precisely because they learn features. Their internal representation evolves during training in a way that fixed-kernel methods fundamentally cannot.
How It Works
To approximate a Calabi-Yau metric with a neural network, you encode the metric as the network’s output, then train it to satisfy Ricci-flatness, the requirement that the space has no net curvature anywhere. But what’s actually happening mathematically as gradient descent nudges the network’s weights toward a solution?
Halverson and Ruehle answered this by extending a powerful tool from machine learning theory: the Neural Tangent Kernel (NTK). The NTK describes how a network’s output changes in response to small parameter adjustments during training. In the metric learning setting, the authors derive a metric-NTK, a kernel governing how the metric at one point in space is linked to the metric at other points through the network’s shared parameters. This kernel behaves differently depending on the network’s width:
- Infinite-width limit: The metric-NTK freezes at initialization and never changes. The flow is mathematically clean but rigid, essentially a linear kernel method.
- Finite-width networks: The metric-NTK evolves during training, coupling different regions of the manifold in a complex, time-dependent way.
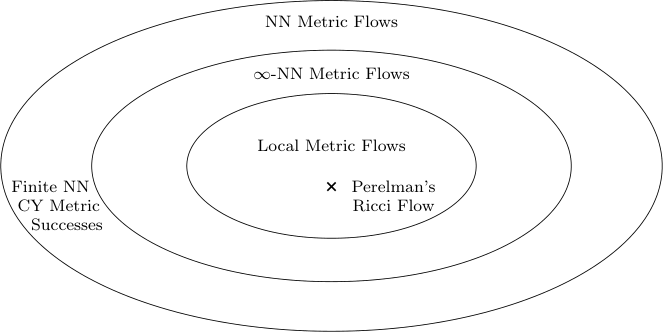
With careful architectural choices (networks that couple metric values only to nearby points) and a specific loss function, the authors show that the infinite-width, fixed-kernel flow reproduces Perelman’s formulation of Ricci flow. This is the same geometric evolution equation Grigori Perelman used in his 2003 proof of the Poincaré conjecture. Perelman reformulated Ricci flow as minimizing a single geometric quantity called the F-functional, and Halverson and Ruehle show this corresponds exactly to a specific neural network architecture in the infinite-width limit. Ricci flow, one of the greatest tools in modern geometry, turns out to be a special case of neural network metric flow.
But those special conditions (infinite width, fixed kernel, local couplings) look highly restrictive from a machine learning perspective. The experiments confirm it.
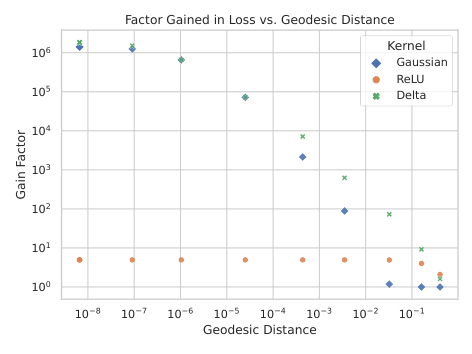
The team tested fixed-kernel versus evolving-kernel networks on the quintic threefold, a classic Calabi-Yau manifold. Fixed-kernel networks, mimicking infinite-width Ricci-flow dynamics, learned the metric poorly; errors stayed high. Finite-width networks with an evolving metric-NTK converged to accurate metrics. Measuring the kernel at different training stages confirmed the picture: for well-trained finite-width networks, the kernel changed substantially from initialization to convergence. For fixed-kernel networks, it stayed frozen, and the results suffered.
Why It Matters
Accurate numerical Calabi-Yau metrics are essential for extracting predictions from string theory compactifications, from particle masses to coupling constants to the structure of the Standard Model. Every advance in numerical methods is a step toward connecting string theory to observable physics.
From a mathematical perspective, the work shows that Ricci flow is embedded inside a much richer family of flows parameterized by neural network architectures. This points toward a whole zoo of geometric flows with no classical names yet, generated by different network designs and loss functions. Some might converge faster, handle more complex geometries, or have properties that mathematicians would find genuinely useful.
For machine learning theory, the results provide a concrete geometric case where the NTK framework makes falsifiable, experimentally verified predictions. Feature learning (the ability of finite-width networks to evolve their internal representations) gives a quantifiable advantage over kernel methods, measured here in geometric error rather than classification accuracy. As neural networks take on more problems in fundamental science, this kind of theoretical grounding matters.
So what comes next? Can different neural architectures realize other classical geometric flows? What are the fixed points for neural network metric flows in general? And can these methods scale to higher-dimensional Calabi-Yau manifolds with more complex topology?
Bottom Line: By building a mathematical theory of how neural networks flow through the space of geometric metrics, Halverson and Ruehle explain why neural networks outperform classical approaches like Ricci flow, and show that feature learning, not just optimization power, is the decisive advantage.
IAIFI Research Highlights
This work builds a unified theory connecting neural network gradient descent with Riemannian geometry and differential topology, showing that Perelman's Ricci flow is a special case of neural network metric flow.
The paper extends the neural tangent kernel framework to geometric function spaces, providing the first theoretical explanation for why finite-width, feature-learning networks outperform infinite-width kernel methods in a geometric learning task.
The theory advances numerical computation of Calabi-Yau metrics critical for deriving physical predictions from string theory compactifications, connecting machine learning to tools central to modern mathematical physics.
Future work could explore whether tailored neural architectures can realize other classical geometric flows or discover entirely new ones; the paper is available at [arXiv:2310.19870](https://arxiv.org/abs/2310.19870).