
Mixture-of-Expert Variational Autoencoders for Cross-Modality Embedding of Type Ia Supernova Data
Authors
Yunyi Shen, Alexander T. Gagliano
Abstract
Time-domain astrophysics relies on heterogeneous and multi-modal data. Specialized models are often constructed to extract information from a single modality, but this approach ignores the wealth of cross-modality information that may be relevant for the tasks to which the model is applied. In this work, we propose a multi-modal, mixture-of-expert variational autoencoder to learn a joint embedding for supernova light curves and spectra. Our method, which is inspired by the Perceiver architecture, natively accommodates variable-length inputs and the irregular temporal sampling inherent to supernova light curves. We train our model on radiative transfer simulations and validate its performance on cross-modality reconstruction of supernova spectra and physical parameters from the simulation. Our model achieves superior performance in cross-modality generation to nearest-neighbor searches in a contrastively-trained latent space, showing its promise for constructing informative latent representations of multi-modal astronomical datasets.
Concepts
The Big Picture
Imagine trying to understand a symphony by hearing only the bass line. You know the melody exists, clues in the rhythm and tempo, but you’re missing crucial information. That’s the challenge astronomers will soon face with Type Ia supernovae.
Type Ia supernovae are the universe’s most reliable distance markers. These thermonuclear explosions of white dwarf stars (the dense, burned-out remnants of Sun-like stars) follow predictable brightness patterns, making them “standard candles” for measuring cosmic distances. This is the same tool that revealed the universe is accelerating in its expansion.
But these explosions aren’t perfectly uniform. Understanding why requires two complementary observations: light curves (brightness over time through colored filters) and spectra (wavelength-by-wavelength snapshots of the explosion’s chemical fingerprint). These data types are deeply connected, but combining them has been a persistent technical headache.
The Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST) will soon photograph the entire Southern Sky every three to four days, generating light curves for roughly a million supernovae per year. The catch: specialized spectrographs can only follow up on 0.1–1% of those events. Yunyi Shen and Alexander Gagliano at MIT and the Center for Astrophysics built a model to close this gap, learning to infer spectral information directly from light curves alone while building a shared representation that captures the physics of both data types.
Key Insight: By training a mixture-of-expert variational autoencoder on supernova simulations, the model can reconstruct spectroscopic data from light curves alone, opening the door to spectral science for the vast majority of supernovae we’ll never directly observe.
How It Works
The core challenge isn’t just combining two data types. It’s that both are structurally messy in different ways. Light curves have irregular timestamps: observations come whenever the telescope points in the right direction. Spectra are taken at varying times relative to peak brightness, at varying wavelength resolutions.
A single supernova might have one spectrum or twenty. Traditional deep learning architectures choke on this variability.
Shen and Gagliano solve this with a two-part architecture. First, they build a transceiver, a “transient perceiver” inspired by DeepMind’s Perceiver-IO. Unlike standard networks, where input size directly determines compute cost, the Perceiver uses cross-attention (a selective filtering mechanism) to compress any-length input into a fixed-size internal summary called a latent representation. Fifty observations or five hundred: the bottleneck stays the same size.
The encoding works like this:
- Photometry: Each observation gets a time encoding (a mathematical tag for when it was taken), a filter-identity tag, and a projected magnitude. These three components sum into a single per-observation representation.
- Spectroscopy: Wavelengths and flux values are embedded separately and summed. The phase (timing relative to peak brightness) is appended as a special token, letting the model route phase information through cross-attention rather than baking it into every element.
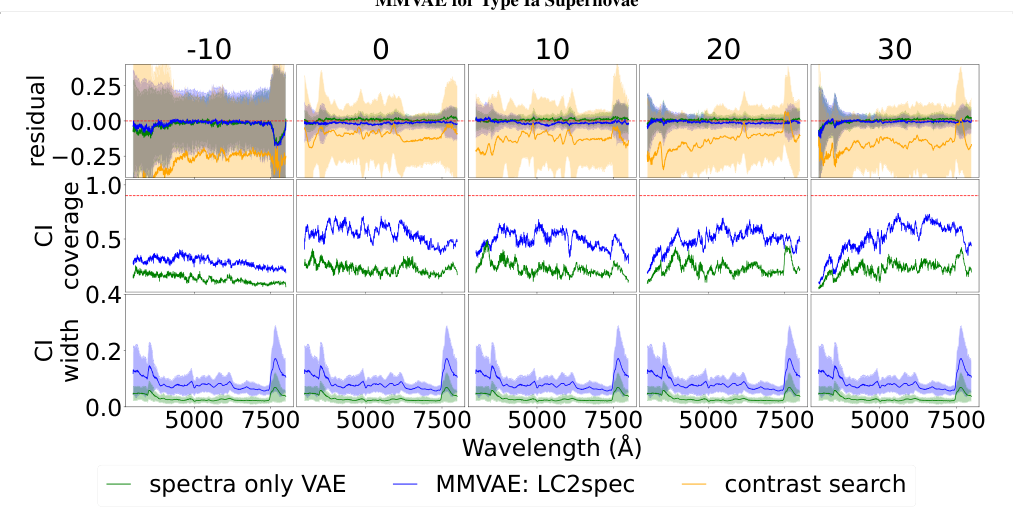
Then comes the MMVAE, a mixture-of-expert variational autoencoder that learns a compact internal space shared across data types and uses it to reconstruct or generate outputs. Standard VAEs compress data into a smooth latent space and reconstruct it. MMVAEs extend this to multiple modalities by modeling the shared space as a mixture of distributions, one from photometry, one from spectroscopy.
During training, both data types are available. At inference, you feed in only a light curve and sample from a latent representation that predicts what the spectrum should look like.
The model trains on SEDONA radiative transfer simulations, physically grounded models of supernova explosions that generate paired light curves and spectra. These let the model learn the correlations between how a supernova evolves photometrically and how its chemical composition changes over time.
Why It Matters
The benchmark comparison is telling. The researchers pitted their MMVAE against a contrastive learning baseline, a technique inspired by CLIP that trains a shared embedding by pulling paired data types together in latent space and pushing unpaired ones apart.
Contrastive embeddings are good for retrieval but not for generation: they can find the closest matching spectrum in a database, but can’t synthesize a new one. The MMVAE outperforms this nearest-neighbor approach on cross-modality reconstruction, suggesting the generative model captures richer structure in the physics linking photometry to spectra.
This matters beyond supernovae. Astronomy is increasingly multi-modal, spanning radio, optical, infrared, and X-ray observations of the same objects, yet only a subset of data types exists for most targets. The MMVAE framework, with its Perceiver backbone for handling irregular inputs, offers a template for multi-modal representation learning across heterogeneous astronomical datasets.
How well does this scale to real observations, with all their noise, calibration quirks, and measurement artifacts? That’s the next frontier.
Bottom Line: Shen and Gagliano’s MMVAE reconstructs supernova spectra from photometry alone, outperforming contrastive baselines and offering a principled framework for multi-modal learning in the era of LSST’s photometric flood.
IAIFI Research Highlights
This work applies recent machine learning architectures (Perceiver-IO, MMVAEs) to a fundamental problem in observational cosmology, connecting photometric abundance to spectroscopic scarcity for Type Ia supernovae.
The transceiver architecture shows how cross-attention mechanisms can handle irregularly sampled, variable-length scientific time series, an approach that generalizes well beyond astronomy.
By enabling spectral inference from light curves alone, this model could make physical parameter estimation (temperatures, velocities, chemical compositions) possible for millions of supernovae LSST will discover but never spectroscopically observe.
Future work will focus on validation against real observed supernova data and scaling to the full LSST photometric stream. See the full paper: [arXiv:2507.16817](https://arxiv.org/abs/2507.16817).