
Multi-filter UV to NIR Data-driven Light Curve Templates for Stripped Envelope Supernovae
Authors
Somayeh Khakpash, Federica B. Bianco, Maryam Modjaz, Willow F. Fortino, Alexander Gagliano, Conor Larison, Tyler A. Pritchard
Abstract
While the spectroscopic classification scheme for Stripped envelope supernovae (SESNe) is clear, and we know that they originate from massive stars that lost some or all their envelopes of Hydrogen and Helium, the photometric evolution of classes within this family is not fully characterized. Photometric surveys, like the Vera C. Rubin Legacy Survey of Space and Time, will discover tens of thousands of transients each night and spectroscopic follow-up will be limited, prompting the need for photometric classification and inference based solely on photometry. We have generated 54 data-driven photometric templates for SESNe of subtypes IIb, Ib, Ic, Ic-bl, and Ibn in U/u, B, g, V, R/r, I/i, J, H, Ks, and Swift w2, m2, w1 bands using Gaussian Processes and a multi-survey dataset composed of all well-sampled open-access light curves (165 SESNe, 29531 data points) from the Open Supernova Catalog. We use our new templates to assess the photometric diversity of SESNe by comparing final per-band subtype templates with each other and with individual, unusual and prototypical SESNe. We find that SNe Ibns and Ic-bl exhibit a distinctly faster rise and decline compared to other subtypes. We also evaluate the behavior of SESNe in the PLAsTiCC and ELAsTiCC simulations of LSST light curves highlighting differences that can bias photometric classification models trained on the simulated light curves. Finally, we investigate in detail the behavior of fast-evolving SESNe (including SNe Ibn) and the implications of the frequently observed presence of two peaks in their light curves.
Concepts
The Big Picture
Imagine trying to identify a person in a crowd from a single blurry photograph. No name tag, no voice, just a smudged image of their face. That’s roughly the challenge astronomers face every time a star explodes somewhere in the universe. Supernovae flash and fade over weeks, leaving behind only a record of how their brightness changed over time. Without a spectrum (essentially a chemical fingerprint requiring expensive telescope time) the best tool astronomers have is that brightness record, called a light curve.
This problem is about to get exponentially harder. The Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST) will scan the entire southern sky every few nights, flagging tens of thousands of new cosmic events per night when it comes online. Spectroscopic follow-up will cover only a tiny fraction of those events.
For the rest, astronomers need reliable reference templates: a mugshot database that matches brightness patterns to explosion types, to classify what exploded from brightness alone.
A team led by Somayeh Khakpash has built exactly that. Their paper delivers 54 data-driven light curve templates covering five subtypes of stripped envelope supernovae across 13 wavelength bands, from ultraviolet to near-infrared. No such atlas of these stellar deaths has existed before.
Key finding: By applying Gaussian Process machine learning to the largest open-access dataset of stripped envelope supernovae ever compiled, the researchers uncovered systematic biases in the simulated data that current AI classifiers train on. Those classifiers may be learning the wrong lessons.
How It Works
Stripped envelope supernovae (SESNe) are what you get when a massive star (eight or more times the mass of our Sun) detonates after shedding its outer hydrogen, or hydrogen and helium, before the explosion. They come in five flavors: Type IIb (a little hydrogen remains), Type Ib (no hydrogen, but helium present), Type Ic (neither hydrogen nor helium), Type Ic-bl (extreme explosion velocities visible in the spectrum, often linked to gamma-ray bursts), and Type Ibn (interacting with a shell of helium-rich gas the star expelled before dying).
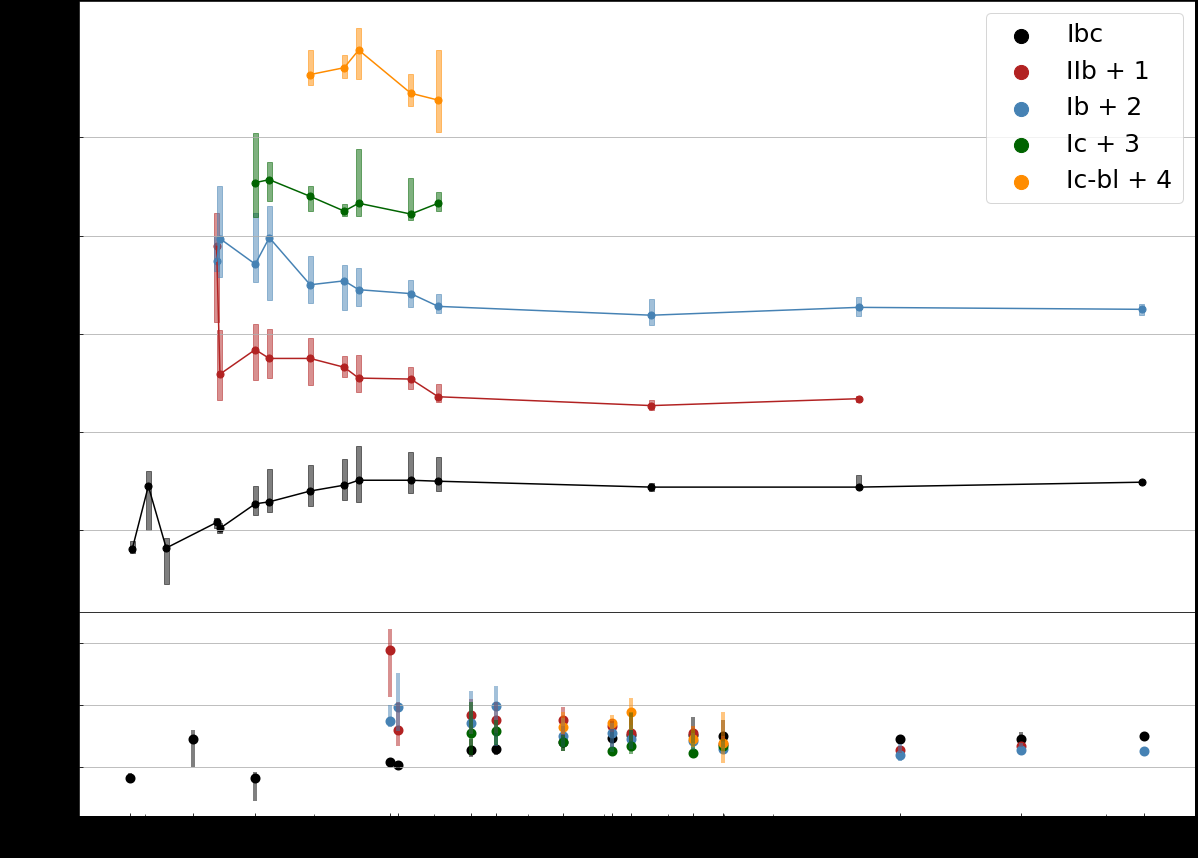
The team assembled light curves for 165 SESNe totaling 29,531 data points, drawn entirely from the Open Supernova Catalog, a publicly accessible archive rather than proprietary observatory data. That open-science commitment meant wrestling with heterogeneous data quality, but it also produced a dataset anyone can reproduce and build on.
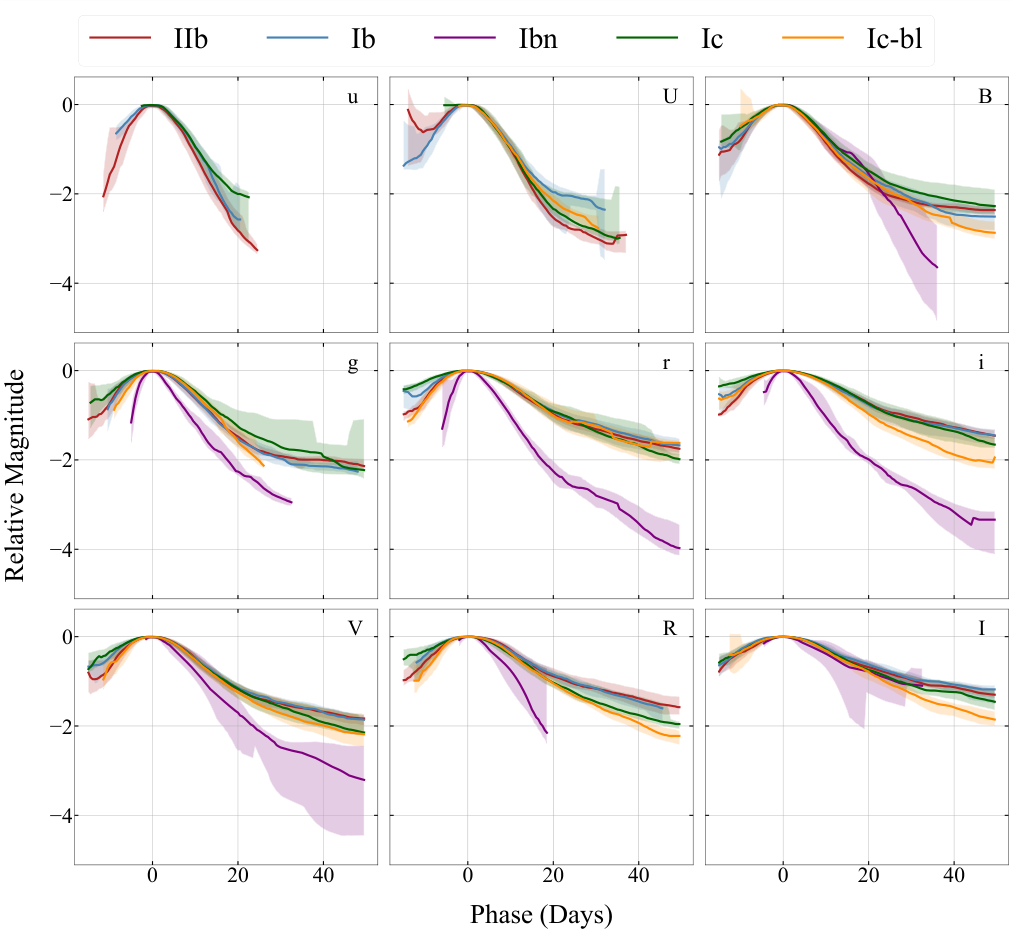
To convert that noisy, unevenly sampled scatter of measurements into smooth templates, the researchers used Gaussian Processes (GPs), a machine learning technique that fits a flexible curve through data while estimating uncertainty at every point. Unlike simple interpolation, GPs propagate uncertainty honestly: where data is sparse, the template widens; where data is dense, it tightens. The process unfolded in four stages:
- Preprocessing: Each light curve was aligned to the moment of explosion, corrected for dust dimming in the supernova’s host galaxy, and converted to a common brightness scale.
- Individual GP fits: Each supernova received its own GP fit in each observed band, filling gaps and smoothing noise.
- Template construction: Per-subtype GP fits averaged across all individual events in a band, weighted by data quality, to produce one representative template per subtype per filter.
- Validation: Templates were compared against prototypical and unusual SESNe to test how well the average captures the population.
The result: 54 templates (one per subtype-band combination) spanning Swift’s ultraviolet filters (w2, m2, w1) through optical (U, B, g, V, R, I) to near-infrared (J, H, Ks).
Why It Matters
The templates immediately revealed something striking: SNe Ibn and Ic-bl rise faster and fade faster than their cousins. They are sprinters in a field of marathon runners. This speed difference has physical meaning; it constrains the mass of radioactive nickel-56 powering the explosion and the geometry of ejected material. The Ibn subtype, which shows signs of crashing into dense gas shed before the star’s death, often displays two distinct brightness peaks, a feature the templates now characterize systematically for the first time.
The more urgent finding concerns the simulated datasets the machine learning community uses to train automated brightness classifiers. The team compared their observational templates against PLAsTiCC and ELAsTiCC (synthetic light curve datasets developed specifically to train and benchmark LSST classification algorithms). The simulated supernovae don’t match the real ones: peak brightnesses differ, how colors shift over time diverges, and fast-evolving subtypes are underrepresented.
A classifier trained on these simulations is learning a distorted picture of the real supernova population. As LSST approaches first observations, fixing these biases in the training data could meaningfully improve automated classification accuracy for millions of events.
Bottom line: These 54 templates give the astronomical community an honest, data-driven baseline for classifying stellar explosions from photometry alone, and expose systematic errors in the simulated training data that current AI classifiers depend on.
IAIFI Research Highlights
This work directly bridges machine learning and observational astrophysics. Gaussian Process regression turns thousands of noisy photometric measurements into physically interpretable templates that will anchor AI-driven classification of LSST's flood of transient detections.
The study identifies concrete biases in PLAsTiCC and ELAsTiCC, the canonical simulated datasets used to develop and benchmark supernova photometric classifiers. The templates give the community a data-driven benchmark for retraining and validating future models.
The templates quantify the photometric diversity of stripped envelope supernovae across UV to near-infrared wavelengths, constraining progenitor and explosion physics for five distinct subtypes and characterizing the double-peaked light curves of fast-evolving Ibn events.
As Rubin/LSST begins operations, these templates will serve as essential reference standards for photometric inference at scale. The full dataset and templates are publicly available, with the paper accessible at [arXiv:2405.01672](https://arxiv.org/abs/2405.01672).