
Multiple testing for signal-agnostic searches of new physics with machine learning
Authors
Gaia Grosso, Marco Letizia
Abstract
In this work, we address the question of how to enhance signal-agnostic searches by leveraging multiple testing strategies. Specifically, we consider hypothesis tests relying on machine learning, where model selection can introduce a bias towards specific families of new physics signals. We show that it is beneficial to combine different tests, characterised by distinct choices of hyperparameters, and that performances comparable to the best available test are generally achieved while providing a more uniform response to various types of anomalies. Focusing on the New Physics Learning Machine, a methodology to perform a signal-agnostic likelihood-ratio test, we explore a number of approaches to multiple testing, such as combining p-values and aggregating test statistics.
Concepts
The Big Picture
Imagine searching for a counterfeit coin hidden in a massive vault. You could deploy one detector tuned to catch gold fakes, but what if the forger used platinum? You’d walk right past it. The smarter strategy: deploy multiple detectors, each calibrated differently, and combine their reports. If any of them flags an anomaly, you investigate.
That’s the challenge facing physicists hunting for new physics at the Large Hadron Collider. The Standard Model has withstood decades of experimental scrutiny, yet theorists are increasingly without a roadmap for what comes next. No dark matter signal. No supersymmetric mirror particles. No obvious pointer.
Experimentalists must therefore search without a predetermined target, scanning collision data for any deviation from Standard Model expectations.
Machine learning has become a go-to tool in this hunt, but it carries a hidden trap: the design of any machine learning model quietly bakes in assumptions about what kind of anomaly you’re looking for. Gaia Grosso and Marco Letizia now show that deploying multiple machine learning tests simultaneously and combining their outputs sidesteps this problem, producing a more uniformly powerful search.
Key Insight: No single machine learning model is equally sensitive to all possible new physics signals. Running several tests with different hyperparameters and combining their results achieves performance close to the best individual test, without having to know in advance which test that is.
How It Works
The core framework is the New Physics Learning Machine (NPLM), a signal-agnostic hypothesis testing methodology. The setup: you have two datasets, a reference sample (simulating Standard Model collisions) and a data sample (actual experimental measurements). NPLM asks one statistical question: are these two populations drawn from the same underlying distribution?
To answer it, NPLM trains a model based on kernel methods, a technique that builds a flexible mathematical picture of the data by comparing each measurement to its neighbors, weighting contributions by distance. The model estimates the likelihood ratio between the data and the reference. This ratio measures how much more probable the observed data would be under a new-physics scenario than under the Standard Model alone.
If the Standard Model is correct, the likelihood ratio should be flat. If new physics is lurking, the model learns a nontrivial deformation, producing a large test statistic (a number summarizing how different the two datasets look) that translates into a small p-value: the probability of seeing a discrepancy this large purely by chance. A small enough p-value becomes a potential discovery claim.
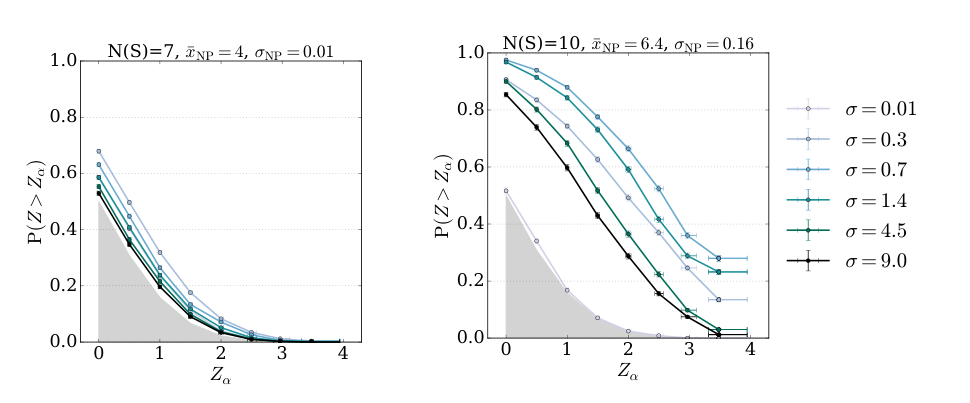
The problem arises during model selection, when you choose the kernel’s bandwidth (how broadly the model peers at each data point), regularization strength (a penalty against overfitting), and other settings. Different choices make the model sensitive to different signals. A narrow kernel catches sharp localized resonances but misses broad spectral distortions. A wide kernel does the opposite. In a real search, you don’t know which setting is best, because you don’t know what new physics looks like.
Grosso and Letizia’s solution: don’t pick. Run many versions of the test, each with a different combination of settings, and combine their outputs. They explore several strategies:
- Combining p-values using classical methods (Fisher’s, Stouffer’s, minimum p-value) to merge significance levels from each test into one global p-value
- Aggregating test statistics by directly averaging or taking the maximum across all runs before computing a single p-value
- Correcting for the look-elsewhere effect by calibrating the combined statistic against its null distribution, preventing multiple tests from inflating the false positive rate
That last correction matters most. Running 20 tests instead of 1 naively makes you 20 times more likely to flag noise as a discovery. The combined test statistic is compared against its distribution under the null hypothesis, assuming the Standard Model is exactly right, with thresholds computed empirically. The false positive rate stays properly controlled. You get the sensitivity benefits of multiple probes without sacrificing statistical rigor.
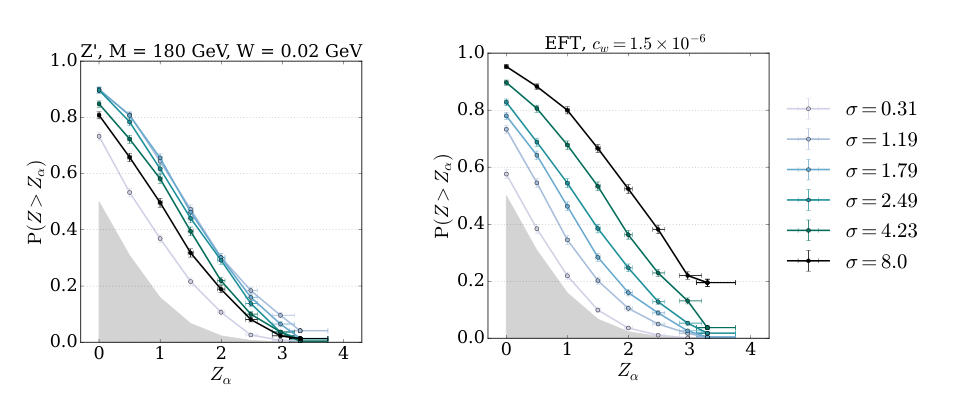
In numerical experiments, the authors tested their framework against a range of synthetic anomalies: sharp resonances, broad excesses, rate deviations. They compared the combined tests to individual ones. The combined approach reliably matches or approaches the performance of the best individual test for each signal type, while no single test dominates across all signal types. The combination is a generalist; each individual test is a specialist. And since you don’t know which specialist to call, the generalist wins.
Why It Matters
Particle physics is entering an era of increasingly ambitious model-independent searches, driven by the absence of clear theoretical targets and the growing toolkit of machine learning methods. But “model-independent” has always been a slight misnomer. Every algorithm carries implicit assumptions, and kernel methods are no exception.
The multiple testing framework offers a statistically controlled way to soften those assumptions. The authors connect their approach to recent work on Maximum Mean Discrepancy tests, a technique for comparing two distributions by measuring the average gap between them. Multiple testing strategies like these could become standard items in the toolkit for signal-agnostic searches across high-energy physics.
The combination methods explored here, particularly aggregating test statistics with proper null calibration, are simple enough to slot into existing analysis pipelines.
Open questions remain. How should tests with different expected sensitivities be weighted? Would adaptive methods that focus on promising hyperparameter regions outperform uniform grids? How does the approach scale to the high-dimensional feature spaces of modern LHC analyses? The framework is already practical, though, and the authors provide code to reproduce their results.
Bottom Line: By running many versions of a machine learning anomaly detector with different hyperparameters and combining their outputs, physicists can achieve near-optimal sensitivity to new physics signals without guessing what those signals look like in advance. This is a practical, statistically sound step toward genuinely model-independent searches at the LHC and beyond.
IAIFI Research Highlights
This work connects statistical machine learning and experimental particle physics, applying multiple testing theory (a classical statistics tool) to signal-agnostic new physics searches powered by kernel-based ML models.
Combining outputs from multiple ML models with different hyperparameters, rather than selecting a single model, produces more uniformly sensitive anomaly detection, a lesson applicable broadly to ML-driven scientific discovery.
By reducing the implicit model-dependence introduced by hyperparameter choices, the framework makes signal-agnostic searches for Beyond the Standard Model physics at collider experiments like the LHC more reliable.
Future work will explore adaptive hyperparameter weighting and extension to higher-dimensional collider observables. The paper is available at [arXiv:2408.12296](https://arxiv.org/abs/2408.12296).
Original Paper Details
Multiple testing for signal-agnostic searches of new physics with machine learning
[2408.12296](https://arxiv.org/abs/2408.12296)
["Gaia Grosso", "Marco Letizia"]
In this work, we address the question of how to enhance signal-agnostic searches by leveraging multiple testing strategies. Specifically, we consider hypothesis tests relying on machine learning, where model selection can introduce a bias towards specific families of new physics signals. We show that it is beneficial to combine different tests, characterised by distinct choices of hyperparameters, and that performances comparable to the best available test are generally achieved while providing a more uniform response to various types of anomalies. Focusing on the New Physics Learning Machine, a methodology to perform a signal-agnostic likelihood-ratio test, we explore a number of approaches to multiple testing, such as combining p-values and aggregating test statistics.