
Naturalness and Fisher Information
Authors
James Halverson, Thomas R. Harvey, Michael Nee
Abstract
Fine-tuning and naturalness, the sensitivity of low-energy observables to small changes in the fundamental parameters of a theory, are cornerstones of physics beyond the Standard Model. We propose a new measure of fine-tuning based on information theory. To each point in parameter space we associate a probability distribution over observables. Divergence measures encode the sensitivity of observables to model parameters and determine a Riemannian metric on parameter space. By Chentsov's theorem, the physically motivated metric is the Fisher information metric, up to scaling. We propose a rescaled fine-tuning matrix $\mathcal{F}_{ij}$ derived from the Fisher information matrix, whose non-zero eigenvalues serve as our measure of fine-tuning. When the number of observables exceeds the number of parameters, $\mathcal{F}_{ij}$ admits a natural geometric interpretation as the pullback of the Euclidean metric from observable space to the submanifold of admissible predictions, with large eigenvalues corresponding to highly stretched directions and indicative of fine-tuning. Our measure reproduces the familiar Barbieri--Giudice criterion as a special case, while generalising it to multiple correlated parameters. We illustrate its behaviour on dimensional transmutation, the Wilson--Fisher fixed point, a simple model of the hierarchy problem, and the electron Yukawa coupling, finding agreement with physical intuition in each case.
Concepts
The Big Picture
Imagine a cake recipe requiring exactly 1.000000000000000 cups of flour, not a hair more or less. A tiny deviation ruins the whole thing. Physicists face a version of this problem at the deepest level of reality: the fundamental constants of nature appear to require precise, seemingly arbitrary cancellations to reproduce the universe we observe.
This is the naturalness problem, and it has haunted particle physics for decades.
The starkest example is the hierarchy problem. The Higgs boson has a measured mass of 125 GeV, yet quantum corrections from heavier particles push it toward values 15 orders of magnitude larger. Recovering the observed value requires canceling two enormous numbers with extraordinary precision. It feels less like physics than cosmic sleight of hand.
Entire frameworks (supersymmetry, extra dimensions, composite Higgs models) were built to explain away this tuning. But physicists still disagree on what “fine-tuned” means quantitatively.
A new paper from IAIFI researchers James Halverson (Northeastern), Thomas Harvey (MIT), and Michael Nee (Harvard) proposes a rigorous answer drawn from information theory, the mathematics of measuring uncertainty and distinguishability. The key move: associate a probability distribution to each point in parameter space, then measure how those distributions diverge as parameters change. This produces a fine-tuning matrix whose eigenvalues give a physically natural, regulator-independent measure of naturalness. The result generalizes and unifies previous approaches, and it’s forced on you by a deep theorem from statistics.
How It Works
The classical approach traces back to Barbieri and Giudice in the 1980s. Their criterion asks: how sensitively does observable X depend on parameter θ? If a 1% change in θ produces a large fractional change in X, that signals fine-tuning. It’s intuitive and practical, but it handles only one parameter at a time and doesn’t generalize to correlated multi-parameter theories.
Halverson, Harvey, and Nee reframe the problem entirely. Instead of asking “how does the observable change?”, they ask: “how distinguishable are the theory’s predictions when you nudge the parameters?”
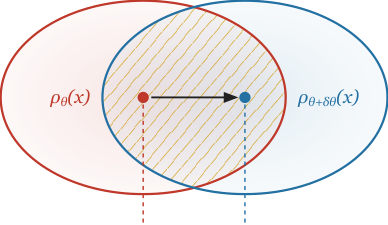
The construction has three steps. First, assign a probability distribution to each point in parameter space. For a theory predicting observables X(θ) deterministically, the natural choice is a Gaussian centered on the prediction, a mathematically convenient way to turn a sharp point prediction into a smooth distribution. Second, measure the divergence between nearby distributions. If shifting θ to θ + δθ makes the two distributions easily distinguishable, the theory is sensitive to those parameters. Third, expand to second order. Taking the small-δθ limit of any reasonable divergence measure yields a Riemannian metric on parameter space, a geometric structure assigning a “distance” to nearby theories.
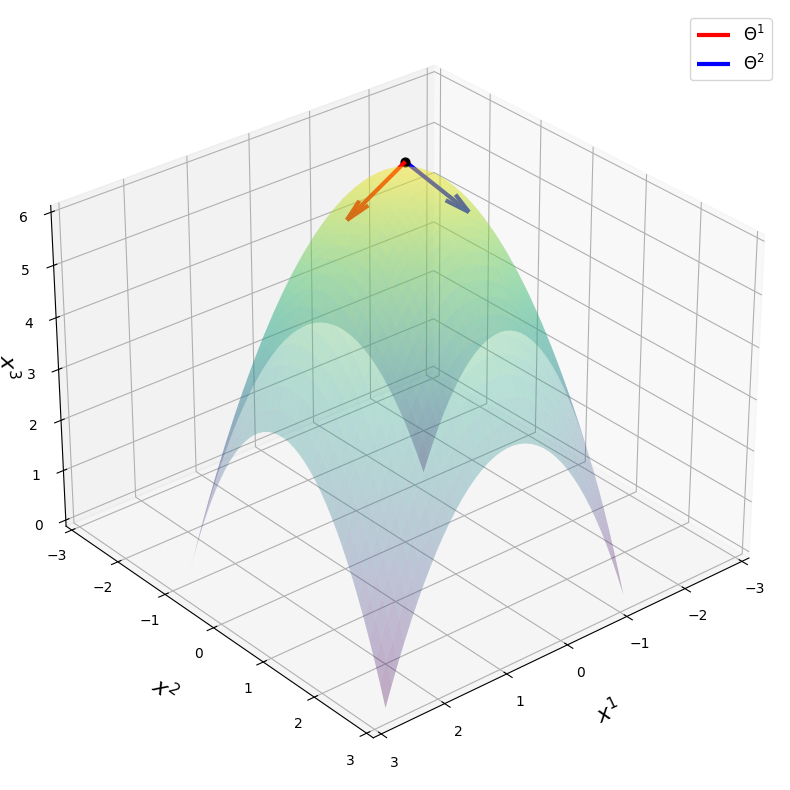
Which divergence measure should you use? Chentsov’s theorem answers this. It’s a deep result in information geometry (the study of probability distributions as geometric objects): the only statistically invariant metric, one unchanged regardless of how you relabel your observables, is the Fisher information metric, up to overall scaling. The choice isn’t arbitrary. It’s mathematically forced.
From the Fisher information matrix, the authors define a rescaled fine-tuning matrix F_ij by stripping away the regulator dependence. Its non-zero eigenvalues, the principal values summarizing the matrix’s overall behavior, become the measure of fine-tuning. Large eigenvalues signal directions in parameter space where predictions stretch rapidly.
When observables outnumber parameters, a clean geometric picture emerges. The predictions X(θ) carve out a curved surface (technically, a submanifold) inside observable space. The fine-tuning matrix is precisely the pullback metric, a tool measuring how that surface gets stretched when embedded in the larger space. A highly stretched surface means small parameter moves produce dramatic swings in predictions. That’s fine-tuning, geometrized.
The framework recovers Barbieri-Giudice in the single-observable, single-parameter limit but produces a full matrix of fine-tuning information for multi-parameter theories.
Why It Matters
The authors test their measure on four classic examples, and the results match established physical intuition.
In dimensional transmutation, where QCD generates the proton mass through quantum mechanics, the measure correctly identifies no fine-tuning. The exponential relationship between the coupling and the mass scale makes predictions robust to small parameter shifts. At the Wilson-Fisher fixed point of the O(N) model, a configuration where a continuous phase transition emerges with matter gradually shifting states rather than changing abruptly, the measure captures the fine-tuning of sitting exactly at criticality.
The hierarchy problem registers as strongly fine-tuned. The electron Yukawa coupling correctly shows none. ‘t Hooft argued this coupling is technically natural: chiral symmetry, a symmetry related to the “handedness” of particles, protects it from large quantum corrections.
The broader reach of this work cuts across physics and AI. The Fisher information metric is already central to machine learning: natural gradient descent uses it to navigate model space more efficiently, following steepest descent in distribution space rather than parameter space. The same mathematical structure, it turns out, governs naturalness in quantum field theories. That these two domains share a core geometric tool isn’t a coincidence anyone at IAIFI would overlook, and the cross-pollination here between ML mathematics and particle physics feels genuinely productive.
Open questions remain. The framework works cleanly for dimensionless couplings but requires care for dimensionful parameters carrying units like mass or length. Extending the measure to discrete model choices, or to theories with strongly correlated high-energy parameters, is the obvious next step.
Bottom line: By grounding fine-tuning in Fisher information geometry, this work gives a mathematically rigorous, uniquely motivated measure of naturalness that generalizes the Barbieri-Giudice criterion to multi-parameter theories and exposes a real connection between information geometry and fundamental physics. The paper is available as arXiv:2603.01411.
IAIFI Research Highlights
This work imports tools from information geometry and statistics (Fisher information and Chentsov's theorem) directly into fundamental particle physics, building a formal connection between machine learning mathematics and the naturalness problem in quantum field theory.
The Fisher information metric is core to natural gradient descent in modern AI training. This paper shows its physical significance in an entirely independent domain, pointing toward a deeper universality in its role as the canonical sensitivity measure for parametric models.
The paper gives the first information-theoretically grounded, regulator-independent measure of fine-tuning for correlated multi-parameter theories, recovering established results (including Barbieri-Giudice and technically natural couplings) as special cases.
Future work can extend this framework to cosmological selection scenarios; the paper ([arXiv:2603.01411](https://arxiv.org/abs/2603.01411)) is part of an ongoing program connecting information theory to physics beyond the Standard Model.