
Neural Thermodynamic Laws for Large Language Model Training
Authors
Ziming Liu, Yizhou Liu, Jeff Gore, Max Tegmark
Abstract
Beyond neural scaling laws, little is known about the laws underlying large language models (LLMs). We introduce Neural Thermodynamic Laws (NTL) -- a new framework that offers fresh insights into LLM training dynamics. On the theoretical side, we demonstrate that key thermodynamic quantities (e.g., temperature, entropy, heat capacity, thermal conduction) and classical thermodynamic principles (e.g., the three laws of thermodynamics and the equipartition theorem) naturally emerge under river-valley loss landscape assumptions. On the practical side, this scientific perspective yields intuitive guidelines for designing learning rate schedules.
Concepts
The Big Picture
Imagine a marble rolling through a mountain range. It moves fast across the steep slopes of narrow valleys, but creeps slowly along the flat riverbeds at the bottom. Scale that up to billions of adjustable settings inside a large language model (LLM, the kind of AI that powers chatbots and text generators), and you have a surprisingly accurate picture of how these systems learn. Training isn’t random chaos. It has structure, and that structure looks remarkably like the laws of thermodynamics.
That’s the central insight behind a new paper from MIT researchers Ziming Liu, Yizhou Liu, Jeff Gore, and Max Tegmark. For years, AI researchers have relied on neural scaling laws (rules of thumb about how model performance improves with more data and computing power), but these rules say nothing about how training actually works, moment to moment. This paper proposes the missing theory.
The researchers introduce Neural Thermodynamic Laws (NTL): a formal framework showing that temperature, entropy, heat capacity, thermal conduction, and all three laws of thermodynamics emerge naturally from the mathematics of LLM training, not by analogy, but as precise mathematical correspondences.
Key Insight: The learning rate, how aggressively the model updates itself with each training step, plays the same role as temperature in thermodynamics. It controls the balance between exploring new solutions and settling on a final answer, governing the system’s stability and the forces shaping the loss landscape.
How It Works
The foundation of NTL is a specific model of the loss landscape (the terrain where every point represents how wrong the model’s predictions are) called the river-valley structure, recently identified in real LLM training runs. The loss surface has long, flat “rivers” running through it, flanked by steep “valley” walls. Training does two things simultaneously: it slowly drifts along the river toward lower loss, and bounces rapidly back and forth across the valley.

This separation of timescales (fast valley dynamics and slow river dynamics) is what unlocks the thermodynamic analogy. The researchers introduce a minimal 2D toy model, ℓ(x,y) = c(y) + ½a(y)x², where x is the fast “valley” variable and y is the slow “river” variable. Simple as it looks, this model is exactly solvable, yielding closed-form expressions for training behavior rather than simulations.
The correspondences they uncover are precise:
- First Law — Total loss splits into “slow loss” (work, macroscopic change) and thermal loss (heat, microscopic fluctuations). Just as ΔU = W + Q, the total loss change equals a work-like term along the river and a heat-like term across the valley.
- Temperature and Equipartition — Under a fixed learning rate, the fast variable reaches a steady-state distribution. Average fast loss becomes ½k_B T (exactly as in classical statistical mechanics), with learning rate η playing the role of temperature. A higher learning rate means a “hotter,” more exploratory system.
- Heat Capacity — Thermal energy stored in the fast directions per unit temperature has a well-defined analog: Q = C_v T, where heat capacity depends on valley curvature.
- Second Law / Thermal Conduction — When the learning rate decays through annealing (gradually dialing back how aggressively the model updates itself), the system cools. The fast variable’s distribution contracts toward the valley floor. A hot system cannot cool below its thermostat’s temperature; analogously, the model’s fluctuation level cannot drop below what the learning rate permits.
- Entropic Force and Third Law — Fast fluctuations exert an effective entropic force (invisible pressure from statistics, not explicit gradients) that pushes the system toward regions of wider valleys. Those regions have more accessible microscopic states, exactly mirroring entropic forces in physical polymer systems.
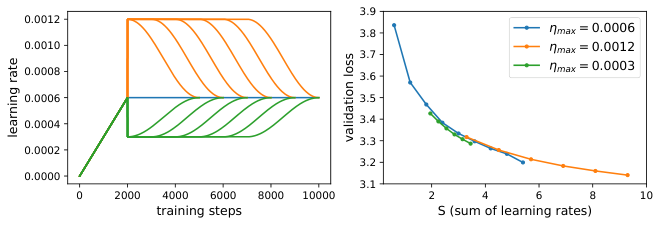
The team validates these predictions against actual LLM training runs, showing the toy model captures qualitative and often quantitative behavior of real models with billions of parameters.
Why It Matters
This work does something rare: it turns an analogy into a theorem. Researchers have long noted that neural networks “look like” thermodynamic systems, but NTL transforms that intuition into rigorous mathematics with predictive power.
The immediate payoff is practical. The framework provides a principled basis for designing learning rate schedules, the programmed plan for how the learning rate changes over training. The standard warmup-stable-decay (WSD) schedule used in modern LLM pretraining now has a physical interpretation: the stable phase corresponds to thermal equilibration along the river, the decay phase to controlled cooling. NTL predicts why these schedules work and suggests how to improve them.
The deeper implications stretch further. If LLM training obeys thermodynamic laws, then tools from statistical mechanics (phase transitions, free energy minimization, fluctuation-dissipation theorems) become available for analyzing AI systems. The third-law analog hints at a “ground state” for trained models determined by loss landscape geometry.
Open questions remain: Do larger models exhibit phase transitions analogous to those in physical materials? Can entropic forces be deliberately engineered to improve generalization? Does the framework extend beyond SGD (stochastic gradient descent, the standard algorithm for nudging model weights toward better predictions) to other optimizers? NTL doesn’t answer these questions, but it provides the language to ask them rigorously.
Bottom Line: Neural Thermodynamic Laws establish that LLM training dynamics follow the same mathematical principles as classical thermodynamics, giving researchers a physical framework for understanding, predicting, and improving how large language models learn.
IAIFI Research Highlights
This work directly instantiates IAIFI's core mission by deriving classical thermodynamic laws (temperature, entropy, heat capacity, and all three laws of thermodynamics) as exact mathematical consequences of LLM training dynamics, connecting statistical physics with modern AI through rigorous mathematics.
NTL provides the first mechanistic, physics-grounded theory for designing learning rate schedules in LLM pretraining, moving the field beyond empirical heuristics toward principled optimization strategies.
The framework demonstrates that thermodynamic universality extends to artificial learning systems, revealing deep structural connections between physical entropy and the geometry of neural loss landscapes.
Future work will explore whether NTL's predictions generalize to other optimizers, larger models, and multimodal architectures; the paper is available at [arXiv:2505.10559](https://arxiv.org/abs/2505.10559).