
Neural Thermodynamics: Entropic Forces in Deep and Universal Representation Learning
Authors
Liu Ziyin, Yizhou Xu, Isaac Chuang
Abstract
With the rapid discovery of emergent phenomena in deep learning and large language models, understanding their cause has become an urgent need. Here, we propose a rigorous entropic-force theory for understanding the learning dynamics of neural networks trained with stochastic gradient descent (SGD) and its variants. Building on the theory of parameter symmetries and an entropic loss landscape, we show that representation learning is crucially governed by emergent entropic forces arising from stochasticity and discrete-time updates. These forces systematically break continuous parameter symmetries and preserve discrete ones, leading to a series of gradient balance phenomena that resemble the equipartition property of thermal systems. These phenomena, in turn, (a) explain the universal alignment of neural representations between AI models and lead to a proof of the Platonic Representation Hypothesis, and (b) reconcile the seemingly contradictory observations of sharpness- and flatness-seeking behavior of deep learning optimization. Our theory and experiments demonstrate that a combination of entropic forces and symmetry breaking is key to understanding emergent phenomena in deep learning.
Concepts
The Big Picture
Why do two completely different AI systems — one trained on images, another on text — end up building eerily similar internal maps of the world? It’s as if they independently arrived at the same language for describing reality. And why does training a neural network sometimes sharpen its internal geometry, then flatten it, in what looks less like deliberate optimization and more like a sudden phase change — the kind of abrupt shift you see when water freezes?
These mysteries have haunted machine learning researchers for years. The usual answer — “the network minimizes its loss function” — simply doesn’t cut it. Loss minimization alone can’t explain why models trained on different tasks with different architectures converge on shared representations. Something else is at work.
A team from MIT, EPFL, and NTT Research has proposed a unifying answer borrowed from thermodynamics — the branch of physics governing heat, energy, and disorder. Neural networks, they argue, aren’t just minimizing energy; they’re also subject to entropic forces — the same statistical pressures that cause gas molecules to spread through a room or polymers to coil into compact shapes. These forces, the researchers argue, are the hidden engine behind some of deep learning’s most striking emergent phenomena.
Key Insight: The algorithm that trains most AI systems doesn’t just minimize a loss — it implicitly minimizes an entropic loss that includes thermodynamic-style forces. These forces systematically reshape neural representations in ways that explain why different AI models converge on the same internal world model.
How It Works
The starting point is a deceptively simple observation. When you train a neural network with stochastic gradient descent (SGD) — an algorithm that repeatedly adjusts a network’s weights by measuring how wrong it is on small random samples of data — you’re not following the true gradient of your loss function. You’re sampling random mini-batches (small, randomly chosen slices of the full dataset) and updating parameters in discrete steps rather than infinitesimally small ones. These two features — randomness and discretization — introduce subtle but systematic biases.
The researchers formalize this by deriving the entropic loss — the modified objective that SGD is actually minimizing, to leading order in the learning rate. The entropic loss equals the original loss plus a correction term proportional to the squared gradient magnitude:
$$\phi_\eta \approx \ell_\gamma + \frac{\eta}{4} |\nabla \ell_\gamma|^2 + O(\eta^2)$$
That extra term penalizes regions of parameter space where gradients are large, pushing the optimizer toward flatter regions. But the story gets richer when you bring in symmetry.
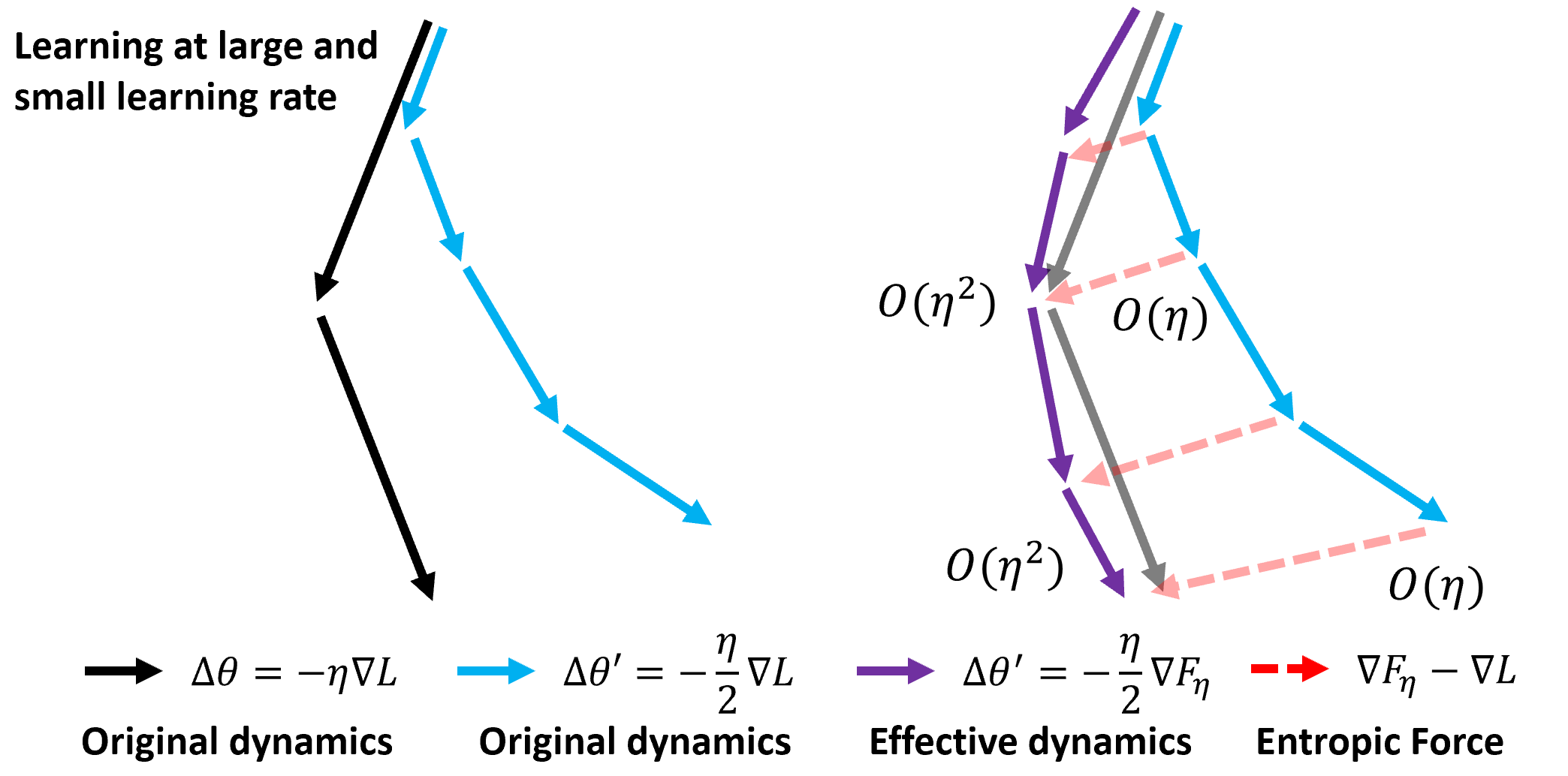
Neural networks are riddled with parameter symmetries — transformations of the internal weights that leave the network’s outputs completely unchanged. Rescaling one layer’s weights while inversely scaling the next produces an identical function. These symmetries create entire families of equivalent solutions.
The key insight: entropic forces systematically break continuous symmetries (those applied by any degree, like smoothly rescaling weights) while leaving discrete symmetries (those working only in specific jumps, like swapping two neurons) intact. The mechanism unfolds in three steps:
- Symmetry identification: Network symmetries are classified as continuous (rescaling) or discrete (permuting neurons).
- Entropic symmetry breaking: The entropic loss has no flat directions along continuous symmetry orbits — it selects preferred points in weight space regardless of initialization.
- Equipartition: This symmetry breaking produces gradient balance phenomena — gradients become approximately equal across components, analogous to the equipartition theorem in statistical mechanics, where thermal energy distributes equally across degrees of freedom.
Why It Matters
One of the paper’s most striking results is a formal proof of the Platonic Representation Hypothesis — the empirical observation that different neural networks, trained on different data with different architectures, develop statistically similar internal representations of the world.
The proof follows from the entropic equipartition structure. When entropic forces drive a network toward gradient balance, the resulting representations reflect the statistical geometry of the training data rather than any arbitrary initialization or architectural choice. Two networks trained on sufficiently rich data are both pushed toward the same statistical fixed point — a kind of thermodynamic equilibrium of representations.
The same framework resolves a long-standing puzzle: the apparent contradiction between progressive sharpening (early in training, the loss landscape grows sharper as gradient descent amplifies certain directions) and edge-of-stability flattening (later, the landscape flattens as the optimizer seeks flatter minima). These aren’t contradictory — they’re sequential consequences of the same entropic dynamics playing out at different timescales.
The theory extends beyond vanilla SGD. The entropic loss formalism applies to any algorithm with a matrix learning rate — a generalized step-size where different parameters can be scaled by different amounts — including Adam, natural gradient descent, and a wide class of biologically-plausible learning rules. The entropic force simply takes a different shape depending on the algorithm’s effective geometry.
This work does something rare in machine learning theory: rather than analyzing one phenomenon in isolation, it unifies several under a single principled framework. The connection to thermodynamics isn’t metaphorical — the mathematical structures are genuinely analogous, meaning tools from statistical physics (free energy, phase diagrams, fluctuation theorems) may become directly applicable to deep learning analysis.
For AI interpretability research — efforts to understand what neural networks are actually doing internally — the entropic loss perspective offers a concrete explanation for why different models learn similar representations. If we understand what convergence pressures shape representations, we can potentially design training procedures that steer toward more interpretable or more robust internal geometries.
The result also opens new questions: Can we engineer specific symmetry-breaking patterns? Can entropic forces be amplified or suppressed to control emergent behaviors?
Bottom Line: Neural networks are thermodynamic machines — their emergent behaviors arise not just from optimizing a loss, but from entropic forces that systematically break symmetries and drive representations toward universal fixed points. This framework proves the Platonic Representation Hypothesis and reconciles the sharpness paradox in a single unified theory.
IAIFI Research Highlights
This paper builds a rigorous bridge between statistical physics and deep learning, showing that SGD dynamics are governed by entropic forces familiar from thermodynamics — providing a physics-native framework for understanding AI emergence.
The work delivers the first formal proof of the Platonic Representation Hypothesis, explaining why diverse neural networks converge on universal representations, with direct implications for interpretability, generalization, and model alignment.
By casting neural network training as a symmetry-breaking thermodynamic process with equipartition laws, the research imports foundational physics concepts — effective energy landscapes, phase transitions, symmetry breaking — into the mathematical study of AI systems.
Future work may leverage the entropic loss framework to engineer training algorithms with targeted symmetry-breaking properties; the paper appears as a NeurIPS 2025 contribution from MIT's Isaac Chuang and collaborators (full derivations and experimental validations available on arXiv).