
Non-parametric Lagrangian biasing from the insights of neural nets
Authors
Xiaohan Wu, Julian B. Munoz, Daniel J. Eisenstein
Abstract
We present a Lagrangian model of galaxy clustering bias in which we train a neural net using the local properties of the smoothed initial density field to predict the late-time mass-weighted halo field. By fitting the mass-weighted halo field in the AbacusSummit simulations at z=0.5, we find that including three coarsely spaced smoothing scales gives the best recovery of the halo power spectrum. Adding more smoothing scales may lead to 2-5% underestimation of the large-scale power and can cause the neural net to overfit. We find that the fitted halo-to-mass ratio can be well described by two directions in the original high-dimension feature space. Projecting the original features into these two principal components and re-training the neural net either reproduces the original training result, or outperforms it with a better match of the halo power spectrum. The elements of the principal components are unlikely to be assigned physical meanings, partly owing to the features being highly correlated between different smoothing scales. Our work illustrates a potential need to include multiple smoothing scales when studying galaxy bias, and this can be done easily with machine-learning methods that can take in high dimensional input feature space.
Concepts
The Big Picture
Imagine trying to predict where cities will grow on a continent, knowing only the terrain as it existed millions of years ago. You have mountains, valleys, rivers, but the patterns that emerge depend on subtle interactions between all these features in ways that resist simple rules.
Now scale that up to the entire universe. Where galaxies form depends on the initial density ripples laid down just after the Big Bang: tiny fluctuations in how evenly matter was spread across space. The connection between those primordial bumps and the galaxies we observe today involves billions of years of gravity slowly pulling matter together. Getting that connection right is one of the central challenges of modern cosmology.
Astronomers describe this connection through galaxy bias, a mathematical relationship between the underlying matter distribution and where galaxies actually sit. The traditional approach writes this as a polynomial expansion: galaxy density equals a constant times matter density, plus another constant times density squared, and so on. Clean. Physically motivated.
But as surveys grow more precise, cracks appear. The polynomial can produce nonsensical results, like predicting negative galaxy densities in regions that happen to be emptier than average.
A Harvard-led team has taken a machine-learning approach, using neural networks to learn the bias function directly from simulations without imposing any polynomial form. The network recovers the halo power spectrum (a statistical measure of how clustered dark matter halos are at different scales) to within 1–2% accuracy, and points toward a surprisingly compact description of how halos form. Dark matter halos are the massive invisible scaffolding that anchors galaxies.
Key Insight: By training a neural network on initial cosmic density fields, the researchers discovered that galaxy formation bias can be captured by just two dominant directions in a high-dimensional feature space, recovering the halo power spectrum to within 1–2% at large scales.
How It Works
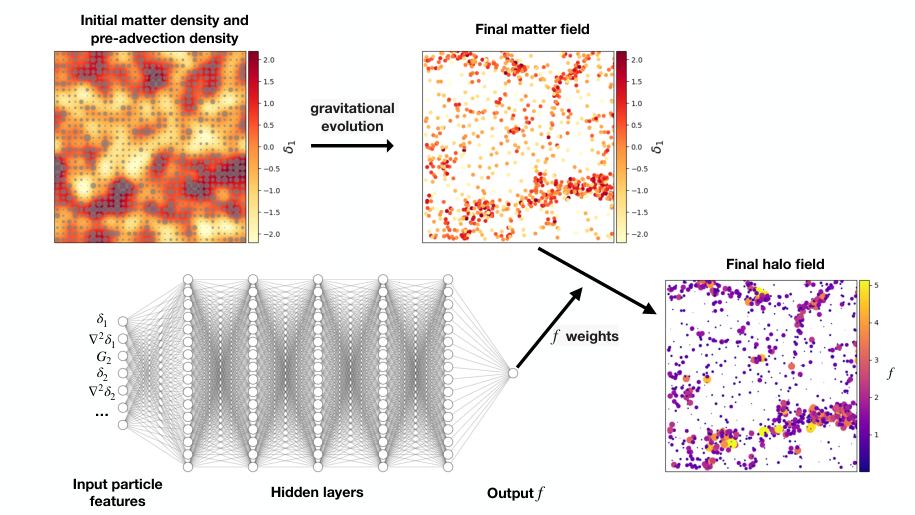
The starting point is the Lagrangian framework, a way of following individual patches of matter through cosmic time rather than watching fixed points in space. Instead of asking “what’s at this location today?”, you ask “where was this clump of matter at the very beginning, and what was its environment like?”
Each point in that initial field carries a set of descriptors:
- Overdensity δ: how much denser this patch is compared to the cosmic average
- Laplacian ∇²δ: how sharply the density peaks or dips, capturing the curvature of the local density profile
- Tidal shear G₂: how much the surrounding gravitational field is trying to stretch or compress that region
These are computed at multiple smoothing scales, meaning the density map is blurred at different resolutions from fine-grained to coarse, so each particle carries a whole vector of features.
The neural network learns a weight function: given these initial conditions, how much halo mass forms here? The architecture is modest (three fully connected layers with 20 neurons each) and trained on particles from the AbacusSummit simulation suite at redshift z=0.5.
Before training, the team applied feature orthogonalization: transforming correlated inputs into independent ones. Density fields at different smoothing scales are highly correlated. The field smoothed over 20 Mpc/h and 30 Mpc/h tell very similar stories. Transforming these into orthogonal components ensures the network isn’t processing the same information twice in disguise.
The team then tested different combinations of smoothing scales:
- One scale: Too limited; misses environmental information at different radii
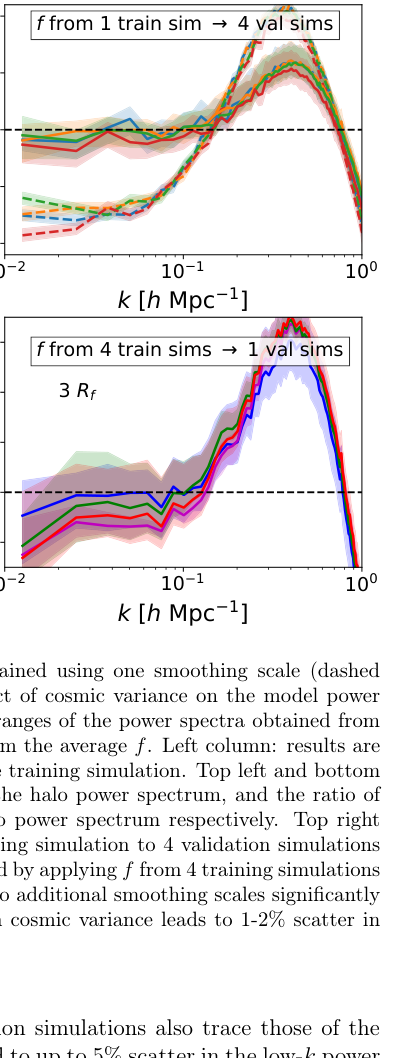
- Three coarsely spaced scales: The sweet spot, recovering the halo power spectrum to within 1–2% at k < 0.1 h/Mpc
- More than three scales: Counterproductive, producing 2–5% underestimation of large-scale power with signs of overfitting
That last result deserves emphasis. More information makes things worse. Finely spaced smoothing scales are nearly redundant; they add correlated noise rather than new physics, and the network gets confused.
The Two-Direction Discovery
After training the full network with nine features (three quantities at three scales), the team examined the gradient of the learned function, asking which directions in feature space the network actually responds to.
They computed principal components of this gradient field, a standard technique for finding the axes of greatest variation. Think of it as identifying the main axes of an elongated cloud of points. The result was unambiguous: two components dominate. Two directions, in a nine-dimensional space, capture nearly all the variation in how halos form.
When they compressed the nine features down to these two principal components and retrained, performance matched or improved over the full nine-dimensional version. Dimensionality reduction made the model more accurate, not less.
What do these two directions represent physically? The team resists assigning clean labels. Because the original features are so strongly correlated across scales, the principal components are complex mixtures that don’t map neatly onto familiar concepts like “density” or “tidal shear.” The network has found something real, but it speaks a different language than traditional bias theory.
Why It Matters
Surveys like DESI, Euclid, and the Rubin Observatory are reaching a precision where percent-level accuracy from traditional bias models no longer cuts it. Understanding galaxy bias at the 1% level has become a practical necessity for extracting cosmological information from these datasets.
There is also a broader point here about methodology. Machine learning can be more than a black-box predictor; in this case it works as a tool for discovering structure in a complex physical system.
The compression to two principal components may turn out to be significant. It suggests that despite the apparent complexity of galaxy formation, the relevant information in the initial conditions lives in a low-dimensional subspace. If those two directions can eventually be connected to specific physical processes (halo mass, assembly history, or something not yet named), it would sharpen theoretical understanding of structure formation.
The multi-scale approach has practical value too. Traditional bias expansions typically operate at a single smoothing scale. Spanning multiple scales simultaneously, even coarsely, captures physics that single-scale approaches miss. Neural networks handle this naturally, without the memory constraints that limited earlier non-parametric methods to two features at a time.
Bottom Line: A neural network trained on initial cosmic density fields learns galaxy bias in a way that requires just two dominant directions to describe. This compression recovers the halo power spectrum to 1–2% and points to a low-dimensional structure underlying halo formation, one that traditional polynomial bias models cannot easily express.
IAIFI Research Highlights
This work sits at the intersection of machine learning and large-scale structure cosmology, using neural networks not just as predictors but as scientific instruments that reveal the intrinsic dimensionality of galaxy bias physics.
Principal component analysis of learned gradients both improves neural network performance and exposes interpretable structure in high-dimensional astrophysical feature spaces.
Achieving 1–2% recovery of the halo power spectrum in a non-parametric framework advances the precision modeling needed to constrain inflation physics and dark energy from upcoming galaxy surveys.
Future work will extend this framework to observable galaxies and test whether the two dominant principal components correspond to known physical quantities. The paper is available as [arXiv:2212.08095](https://arxiv.org/abs/2212.08095), part of the AbacusSummit simulation analysis series.