
OccamLLM: Fast and Exact Language Model Arithmetic in a Single Step
Authors
Owen Dugan, Donato Manuel Jimenez Beneto, Charlotte Loh, Zhuo Chen, Rumen Dangovski, Marin Soljačić
Abstract
Despite significant advancements in text generation and reasoning, Large Language Models (LLMs) still face challenges in accurately performing complex arithmetic operations. Language model systems often enable LLMs to generate code for arithmetic operations to achieve accurate calculations. However, this approach compromises speed and security, and fine-tuning risks the language model losing prior capabilities. We propose a framework that enables exact arithmetic in a single autoregressive step, providing faster, more secure, and more interpretable LLM systems with arithmetic capabilities. We use the hidden states of a LLM to control a symbolic architecture that performs arithmetic. Our implementation using Llama 3 with OccamNet as a symbolic model (OccamLlama) achieves 100\% accuracy on single arithmetic operations ($+,-,\times,÷,\sin{},\cos{},\log{},\exp{},\sqrt{}$), outperforming GPT 4o with and without a code interpreter. Furthermore, OccamLlama outperforms GPT 4o with and without a code interpreter on average across a range of mathematical problem solving benchmarks, demonstrating that OccamLLMs can excel in arithmetic tasks, even surpassing much larger models. We will make our code public shortly.
Concepts
The Big Picture
Ask a brilliant professor to explain quantum entanglement, and they’ll dazzle you. Ask them to quickly multiply 7,341 by 8,829 in their head, and watch them fumble. That same mismatch plagues today’s most powerful AI systems. GPT-4 can write legal briefs and debug complex software, but it still stumbles on basic math with surprising regularity.
The standard workaround is to let the AI write code to do the calculation. A language model, asked to multiply two numbers, generates a Python snippet, runs it, and returns the result. It works, but it’s slow, it’s a security headache, and it requires several back-and-forth processing passes just to add two numbers. For applications where speed matters (systems where multiple AI components coordinate in real time) this overhead compounds into something genuinely painful.
Researchers at MIT have built a smarter fix: a framework called OccamLLM that gives language models exact arithmetic ability in a single step, with no code execution, no retraining of the underlying AI model, and complete transparency into how every answer was reached.
Key Insight: OccamLLM connects a language model’s internal “understanding” of a problem to a symbolic calculator, not by writing code, but by using the model’s hidden states to directly configure the math engine. The result is 100% accuracy on arithmetic operations while answering in over 50 times fewer tokens than code-based approaches.
How It Works
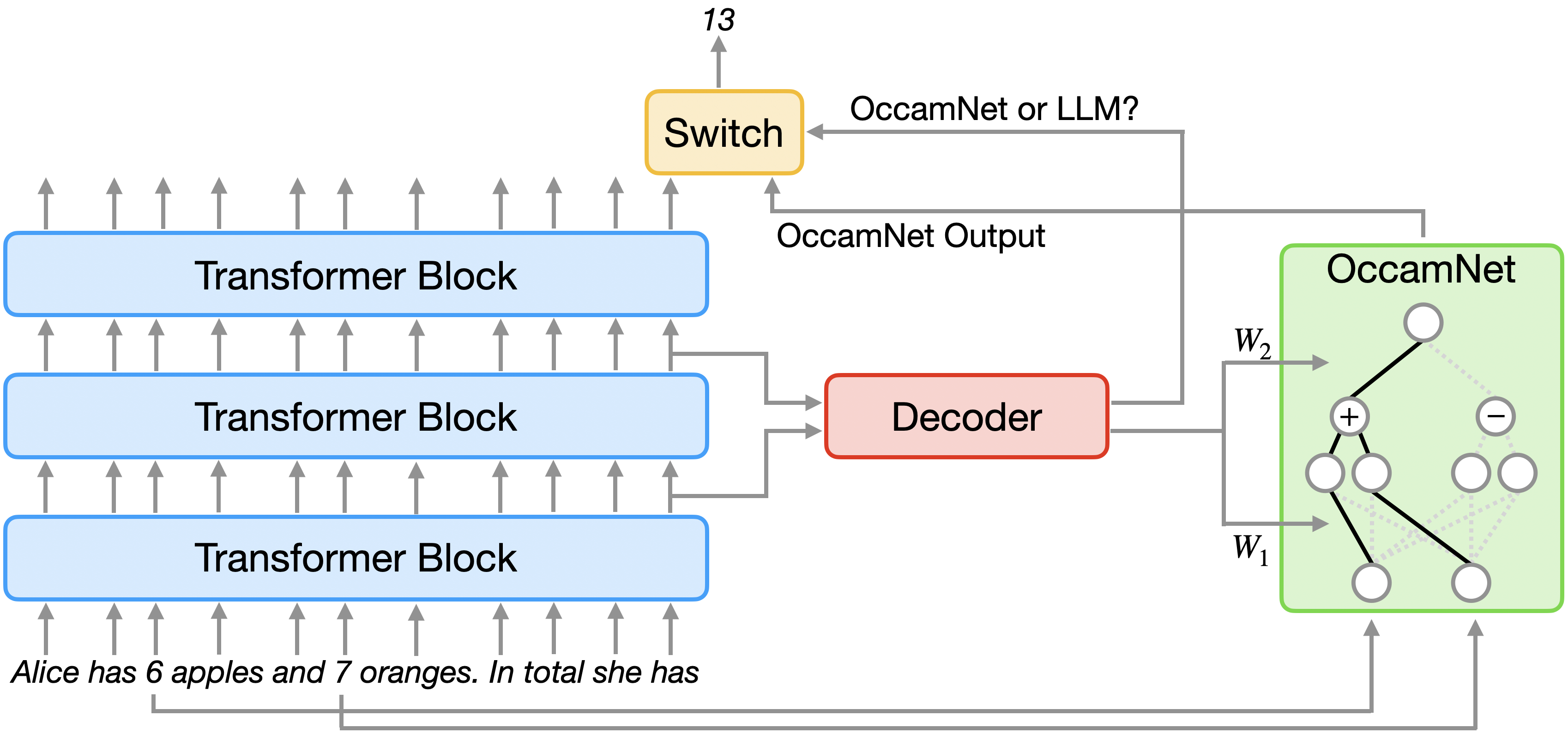
When a language model processes text, it builds up rich internal representations called hidden states that encode what the model “understands” about the context so far. OccamLLM intercepts those hidden states and uses them as a control signal for a separate symbolic computation engine.
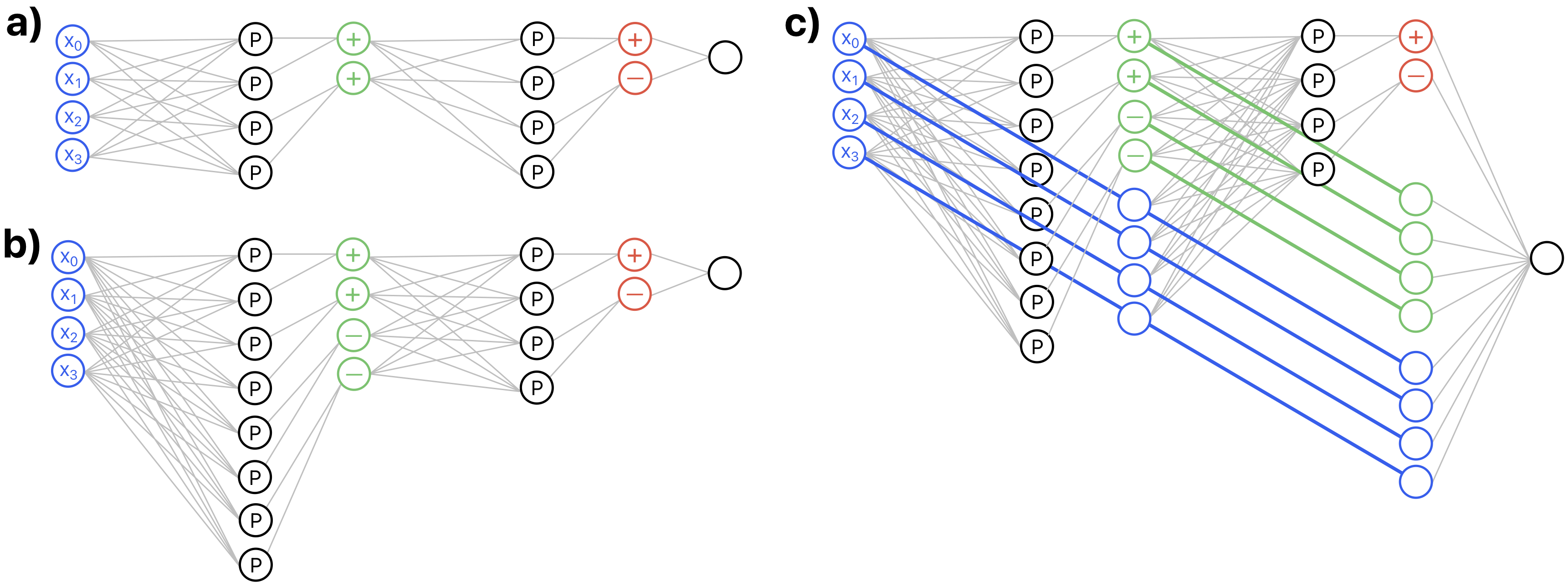
That engine is OccamNet, a hybrid architecture combining neural-network pattern-matching with traditional rule-based symbolic reasoning. It represents mathematical functions as small, selective combinations of primitive operations (addition, subtraction, multiplication, division, sine, cosine, logarithm, exponential, square root) using only a few at a time to keep computation readable and traceable. Think of OccamNet as a reconfigurable calculator: its internal settings determine which operation it performs. OccamLLM’s job is to dial in those settings correctly based on what the language model understands the problem to be.
Here’s the pipeline in action:
- The user poses a math problem in natural language.
- The language model processes the text and produces hidden states at each token.
- A lightweight decoder block (a small neural network component) reads those hidden states and outputs settings that configure OccamNet for the correct operation.
- A string parser extracts the relevant numbers from the input text and feeds them into OccamNet.
- OccamNet evaluates the expression exactly, symbolically, and returns the result.
- A final decision module determines whether to use the language model’s output or OccamNet’s output for that token.
The base language model (Llama 3, in the paper’s implementation) is never fine-tuned. Only the decoder block gets trained, on a modest dataset of labeled examples: tens per task, not thousands. This sidesteps catastrophic forgetting, where fine-tuning a model on one task degrades its performance on everything else it previously knew.
The architecture reflects Occam’s Razor in practice: find the simplest explanation. OccamNet’s selective function representations produce interpretable outputs. You can see exactly which operation was selected and why, rather than trusting a black-box neural network’s numerical answer.
Why It Matters
The benchmark results speak for themselves. OccamLlama (the Llama 3 implementation) achieves 100% accuracy on individual arithmetic operations: addition, subtraction, multiplication, division, and five transcendental functions. GPT-4o without tools hits roughly half that.
GPT-4o with a code interpreter comes close, but OccamLlama matches or beats it while using more than 50 times fewer generation tokens. On broader mathematical problem-solving benchmarks, OccamLlama outperforms GPT-4o on average, with and without the code interpreter, despite being a substantially smaller model.
That point deserves a second look: a smaller model, augmented with a principled symbolic tool, beats a larger model trying to do arithmetic through brute-force language generation. This is a direct empirical argument for hybrid AI architectures.
Arithmetic is a job for symbolic systems. Language is a job for neural networks. OccamLLM lets each component do what it does best.
The security angle also matters more than it might first appear. When a language model generates and executes code, that code can be manipulated through carefully crafted inputs to do things the user never intended. Replacing code execution with a constrained symbolic architecture closes that attack surface entirely. The system can only perform the mathematical operations it was built for, nothing more.
The framework isn’t limited to arithmetic, either. The authors point out that OccamLLM can work with any symbolic architecture, which opens a path to language models that control physics simulators, equation solvers, or domain-specific scientific tools, all from a single generation step, all with full interpretability.
Bottom Line: OccamLLM proves that giving language models exact arithmetic doesn’t require writing code or retraining the model, just a smarter connection between neural understanding and symbolic computation. It achieves perfect accuracy while running dramatically faster than today’s code-interpreter approaches.
IAIFI Research Highlights
This work brings ideas from symbolic AI and neurosymbolic computing, fields with deep roots in mathematical physics, into practical LLM engineering. The result: principled hybrid architectures outperform purely neural approaches even at much larger scale.
OccamLLM introduces a new approach for augmenting pretrained language models with exact computational tools. No fine-tuning, no code execution, single-step inference, and full interpretability of every computation performed.
Reliable, interpretable arithmetic in language models removes a real bottleneck for LLM-powered scientific tools, from physics tutors to automated research assistants, that need quantitative reasoning without sacrificing safety or speed.
The OccamLLM framework generalizes beyond arithmetic to any symbolic architecture, pointing toward language models that natively control scientific simulators and solvers. The paper is available as a preprint at [arXiv:2406.06576](https://arxiv.org/abs/2406.06576), from the MIT groups of Marin Soljačić and collaborators.