
On the convergence of group-sparse autoencoders
Authors
Emmanouil Theodosis, Bahareh Tolooshams, Pranay Tankala, Abiy Tasissa, Demba Ba
Abstract
Recent approaches in the theoretical analysis of model-based deep learning architectures have studied the convergence of gradient descent in shallow ReLU networks that arise from generative models whose hidden layers are sparse. Motivated by the success of architectures that impose structured forms of sparsity, we introduce and study a group-sparse autoencoder that accounts for a variety of generative models, and utilizes a group-sparse ReLU activation function to force the non-zero units at a given layer to occur in blocks. For clustering models, inputs that result in the same group of active units belong to the same cluster. We proceed to analyze the gradient dynamics of a shallow instance of the proposed autoencoder, trained with data adhering to a group-sparse generative model. In this setting, we theoretically prove the convergence of the network parameters to a neighborhood of the generating matrix. We validate our model through numerical analysis and highlight the superior performance of networks with a group-sparse ReLU compared to networks that utilize traditional ReLUs, both in sparse coding and in parameter recovery tasks. We also provide real data experiments to corroborate the simulated results, and emphasize the clustering capabilities of structured sparsity models.
Concepts
The Big Picture
Imagine trying to understand a symphony by tracking every instrument at once. It’s overwhelming. But orchestras naturally break into sections: strings here, brass there, woodwinds in their own corner. Each musical phrase involves whole sections playing together, never random instruments scattered across the room. Once you see that structure, analysis and reconstruction become tractable.
Neural networks face a similar challenge when learning to represent data. Standard approaches allow any combination of thousands of hidden units to activate at once, creating a tangled jumble of signals. But many real-world signals, from neuroscience recordings to particle physics data, naturally organize into groups.
Researchers at Harvard and Tufts have built a group-sparse autoencoder that exploits this structure: a neural network that compresses and reconstructs data while forcing its internal responses into tightly coordinated blocks. More than just proposing the architecture, they prove mathematically that gradient descent training actually recovers the true underlying patterns.
Key Insight: Enforcing block-structured sparsity in neural network activations lets gradient descent reliably recover the true data-generating patterns, outperforming traditional sparse methods in both theory and practice.
How It Works
An autoencoder is a neural network with two halves. An encoder compresses input data into a compact hidden representation; a decoder reconstructs the original from that compressed form. When trained well, the network learns meaningful structure rather than just memorizing inputs.
Traditional autoencoders impose sparsity: they push most hidden neurons toward zero, forcing the network to represent data using only a handful of active units. This works, but it misses something. In many natural datasets, the nonzero activations don’t scatter randomly. They cluster in blocks. Think of a light panel where you can only turn on entire rows at a time, never individual bulbs from different rows.
The paper introduces a group-sparse ReLU (GReLU) activation function that enforces exactly this block structure. Where a standard ReLU zeroes out negative values one at a time, GReLU zeroes out entire groups of units if the group’s total activation falls below a threshold. Active neurons appear in coherent blocks rather than arbitrary patterns.
The architecture works in two phases:
- Encoding: The input passes through a weight matrix and the GReLU activation, producing a group-sparse hidden representation. The active group directly identifies which cluster the input belongs to.
- Decoding: A second weight matrix reconstructs the original input from the sparse code. Training minimizes reconstruction error across many examples.
The hard part is proving this actually converges. The team analyzes the gradient dynamics (how the weight matrices shift during training) under the assumption that data come from a group-sparse generative model. They show that the gradient of the loss function behaves predictably near the true solution, and that gradient descent steers network parameters toward the generating matrix: the true dictionary that produced the data.
This is a non-trivial result. The loss surface that autoencoders navigate during training is full of flat regions and deceptive local minima where learning can stall. Showing that gradient descent reliably finds the right answer, rather than getting stuck, required careful analysis of how the error signal behaves near the target.
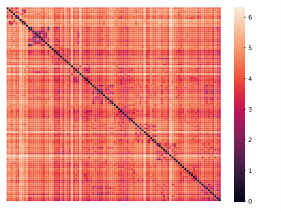
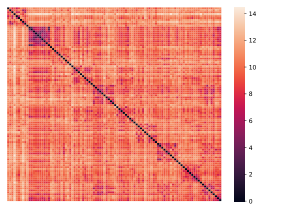
Why It Matters
In both simulated experiments and real data tests, networks using GReLU consistently outperformed those using standard ReLU, recovering the generating dictionary more accurately and learning more interpretable representations. The margin isn’t marginal: group-sparse structure gives the optimizer meaningful guidance that pure sparsity cannot.
There’s also a direct connection to clustering. When a group-sparse network encodes an input, the particular group of units that activates acts as a label: all inputs activating the same group belong to the same cluster. The convergence results therefore imply that, under mild conditions, the network automatically discovers cluster membership in union-of-subspaces data models. Abstract optimization theory translates into a concrete capability: unsupervised classification without labels.

For physics and astrophysics, group-sparse structure is a natural fit. Particle collision events, gravitational wave signals, and galaxy morphologies all exhibit natural grouping, and similar events share similar activation patterns in their latent representations. A network architecture with provable recovery guarantees is more trustworthy than a black-box approach, especially for scientific inference where interpretability matters.
The current theory handles shallow (single-layer) autoencoders. Extending convergence guarantees to deep networks is a clear next step. The framework also assumes data that strictly follow the group-sparse model; relaxing this to handle approximate or mixed models would bring the theory closer to real-world messiness. Connecting GReLU networks to established clustering algorithms like k-means or spectral methods could yield useful hybrid approaches.
Bottom Line: Group-sparse autoencoders don’t just work better empirically. They come with a mathematical certificate that gradient descent finds the right answer, putting structured-sparsity networks on rigorous theoretical footing for the first time.
IAIFI Research Highlights
This work connects signal processing, optimization theory, and deep learning, building neural architectures on sparse coding, dictionary learning, and union-of-subspaces models — mathematical structures that appear throughout physics data analysis.
The paper provides the first convergence guarantees for group-sparse autoencoders, establishing that gradient descent reliably recovers underlying generative models when data exhibit block-structured sparsity. This is a significant step toward interpretable, model-based deep learning.
Group-sparse representations offer a mathematically grounded approach to unsupervised clustering in structured scientific datasets, with applications to physics signals that naturally cluster by event type, particle species, or morphological class.
Future directions include extending convergence theory to deep multi-layer group-sparse networks and relaxing strict generative model assumptions; the full paper is available at [arXiv:2102.07003](https://arxiv.org/abs/2102.07003).