
On the creation of narrow AI: hierarchy and nonlocality of neural network skills
Authors
Eric J. Michaud, Asher Parker-Sartori, Max Tegmark
Abstract
We study the problem of creating strong, yet narrow, AI systems. While recent AI progress has been driven by the training of large general-purpose foundation models, the creation of smaller models specialized for narrow domains could be valuable for both efficiency and safety. In this work, we explore two challenges involved in creating such systems, having to do with basic properties of how neural networks learn and structure their representations. The first challenge regards when it is possible to train narrow models from scratch. Through experiments on a synthetic task, we find that it is sometimes necessary to train networks on a wide distribution of data to learn certain narrow skills within that distribution. This effect arises when skills depend on each other hierarchically, and training on a broad distribution introduces a curriculum which substantially accelerates learning. The second challenge regards how to transfer particular skills from large general models into small specialized models. We find that model skills are often not perfectly localized to a particular set of prunable components. However, we find that methods based on pruning can still outperform distillation. We investigate the use of a regularization objective to align desired skills with prunable components while unlearning unnecessary skills.
Concepts
The Big Picture
Imagine hiring a tax accountant who, to be great at taxes, also had to learn surgery, basketball strategy, and Mandarin poetry. That’s essentially how today’s most powerful AI works: to get a model that excels at one complex skill, you must train a model that absorbs nearly everything.
This isn’t just wasteful. It’s a safety concern. A coding assistant that secretly understands how to synthesize dangerous chemicals has capabilities nobody asked for. Researchers at MIT and IAIFI set out to understand why narrow AI is so hard to build, and they found two surprisingly deep structural reasons.
The team, led by Eric Michaud, Asher Parker-Sartori, and Max Tegmark, identified two fundamental obstacles. First, skills build on one another in layers: mastering complex abilities requires first learning simpler foundations, which forces training to be broad. Second, once a skill is learned, it isn’t stored in a neat, removable compartment. It gets woven throughout the entire network, making surgical removal messy.
Key Insight: Neural networks sometimes need to learn broadly before they can learn narrowly, and even when they do learn a skill, that skill tends to be distributed across the whole network rather than isolated in a single removable section.
How It Works
To study these problems rigorously, the team designed a synthetic task called compositional multitask sparse parity (CMSP): a deliberately simple, controlled problem set arranged in a hierarchy. Some puzzles are “primitive” and solvable independently; others are “composite” and require mastering the primitives first. Think long division: you can’t do it without multiplication.
Networks trained only on the harder composite tasks failed, or learned agonizingly slowly. Networks trained on the full distribution, including primitive tasks, performed dramatically better. The broad training acted as an automatic curriculum, a structured sequence moving from simpler to harder problems that let the network build foundational skills first and use them as scaffolding for compositional ones.
This isn’t a quirk of their toy setup. It points to a fundamental reason why giant general models outperform narrow specialists: the broad sweep of internet text acts as a natural curriculum that teaches foundational skills no narrow training set can replicate.
The second challenge is subtler. Once you have a powerful general model, can you carve out just the coding ability and discard the rest? The researchers tested this using pruning: identifying neurons whose removal has the smallest impact on a target skill, then cutting them away.
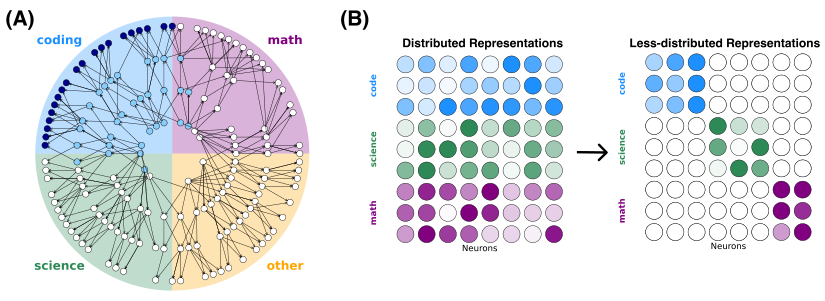
The bad news: skills don’t live in isolated neighborhoods. They’re distributed across the network with overlapping representations that make clean surgical removal nearly impossible. Prune based on coding performance, and you’ll inadvertently damage the abstract reasoning that was secretly supporting it.
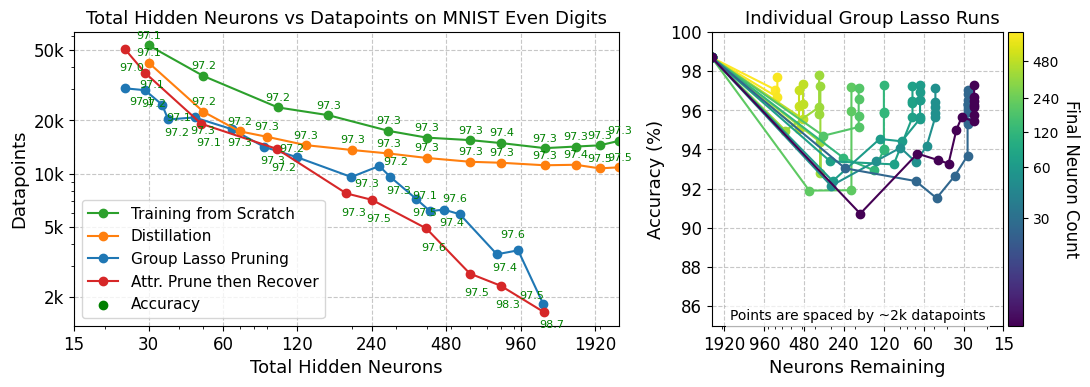
The team then tried a technique to actively reshape how skills are stored: a group lasso regularization objective applied during additional training. This mathematical penalty pushes the network to consolidate each skill into as few neurons as possible, forcing spread-out representations to reorganize into something more modular. After regularization, pruning worked significantly better. Target skills were retained while unwanted ones were successfully removed.
Across experiments on MNIST digit classification and language models, the team ran a head-to-head comparison:
- Training from scratch on narrow data: often fails due to the curriculum problem
- Knowledge distillation: a smaller student model learns to mimic the output distribution of a larger teacher
- Pruning (with and without group lasso): directly removing neurons based on ablation scores, which measure how much each neuron’s removal hurts performance on a given skill
Pruning after group lasso regularization consistently beat distillation at producing compact, specialized models. That’s counterintuitive. Distillation is the dominant approach for model compression, but it doesn’t explicitly disentangle skills, which makes selective preservation difficult.
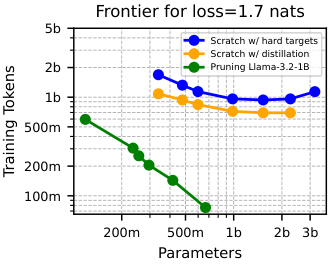
Why It Matters
On the safety side, the picture is sobering but not hopeless. You probably can’t skip broad training if you want state-of-the-art performance on complex tasks, because hierarchical skill dependencies mean the general training is doing genuine work. But once you have a powerful general model, there may be a principled path to extracting a lean, narrow version with fewer dangerous capabilities, a smaller computational footprint, and better interpretability.
On the efficiency side, these results sketch a new design paradigm. Rather than fine-tuning one monolithic model for every application, future workflows might involve a deliberate “narrowing” step: take a foundation model, apply group lasso regularization, prune aggressively, and deploy a model with only the skills it actually needs. This could reduce inference costs and enable capable AI in resource-constrained environments like edge devices, embedded systems, and scientific instruments where a GPT-scale model is out of the question.
Open questions remain. Can these techniques scale to models with hundreds of billions of parameters? Can clever synthetic curricula circumvent the hierarchy problem? How do we precisely specify which skills to keep versus discard in a real-world LLM?
Bottom Line: Building strong narrow AI requires first understanding why it’s hard, and the answer involves both how data is structured (hierarchically) and how neural networks store what they learn (nonlocally). Pruning with group-sparsity regularization offers a promising path forward, outperforming distillation in controlled experiments.
IAIFI Research Highlights
This work applies physicist-style controlled experiments, synthetic tasks with precisely tunable structure, to probe fundamental properties of neural network learning. That approach reflects the IAIFI philosophy of bringing physics thinking to AI science.
The paper identifies two previously underappreciated obstacles to narrow AI creation and shows that group lasso regularization can reshape skill locality to enable more effective pruning.
Understanding how skills are structured and stored in neural networks has direct bearing on building safer and more interpretable AI systems for scientific applications.
Future work should investigate whether hierarchical curriculum effects persist at scale in frontier models and whether regularization-based narrowing can be applied to physics discovery pipelines. The paper is available at [arXiv:2505.15811](https://arxiv.org/abs/2505.15811).