
On the Learnability of Knot Invariants: Representation, Predictability, and Neural Similarity
Authors
Audrey Lindsay, Fabian Ruehle
Abstract
We analyze different aspects of neural network predictions of knot invariants. First, we investigate the impact of different knot representations on the prediction of invariants and find that braid representations work in general the best. Second, we study which knot invariants are easy to learn, with invariants derived from hyperbolic geometry and knot diagrams being very easy to learn, while invariants derived from topological or homological data are harder. Predicting the Arf invariant could not be learned for any representation. Third, we propose a cosine similarity score based on gradient saliency vectors, and a joint misclassification score to uncover similarities in neural networks trained to predict related topological invariants.
Concepts
The Big Picture
Imagine trying to tell two tangled pieces of rope apart without touching them. You can look from any angle, count crossings, trace how loops pass over and under each other, but you cannot physically manipulate them. Now imagine doing this at the scale of quantum computing or theoretical physics, where the “knots” are abstract mathematical objects. This is the world of knot theory, and AI is becoming one of its most powerful new tools.
Knots in mathematics are deceptively simple to define (a closed loop embedded in three-dimensional space) but fiendishly complex to analyze. Mathematicians have developed dozens of knot invariants: numbers or formulas that act like fingerprints, staying constant no matter how you twist or deform a knot, as long as you don’t cut it.
The catch is that computing many of these invariants is extraordinarily hard. The Jones polynomial (one such formula encoding deep structural information) is almost certainly impossible to calculate efficiently in general, placing it in a difficulty category called #P-hard. That makes it a natural target for machine learning.
Researchers Audrey Lindsay and Fabian Ruehle at Northeastern University’s IAIFI set out to systematically survey knot invariant learnability. They asked not just can neural networks predict these quantities, but which representation of a knot is best, which invariants are easiest to learn, and when two networks learn related tasks, can we detect that similarity?
Key Insight: Braid representations of knots are the best input format for neural networks, and some knot invariants (especially those from hyperbolic geometry) are dramatically easier for machines to learn than others, with the mysterious Arf invariant resisting learning entirely.
How It Works
The study begins with a fundamental choice: how do you show a knot to a neural network? The authors tested five representations drawn from the KnotInfo database of nearly 13,000 knots with up to 13 crossings:
- Dowker–Thistlethwaite (DT) codes — a compact integer sequence encoding crossing information
- Planar Diagram (PD) codes — four-tuples of integers per crossing, geometrically intuitive
- Gauss codes — sequences that trace the knot’s path and record each crossing encountered
- 3D coordinates — spatial positions of points along the embedded curve
- Braid words — algebraic sequences from the braid group, a framework that treats knots as braided strands closing into loops
Each representation carries different structural information. Braid words encode knots compactly and algebraically, though they can grow long; the minimal braid word for some 13-crossing knots runs 73 symbols. 3D coordinates aid visualization but lack algebraic structure. The question is which format best equips a network to detect underlying mathematical patterns.
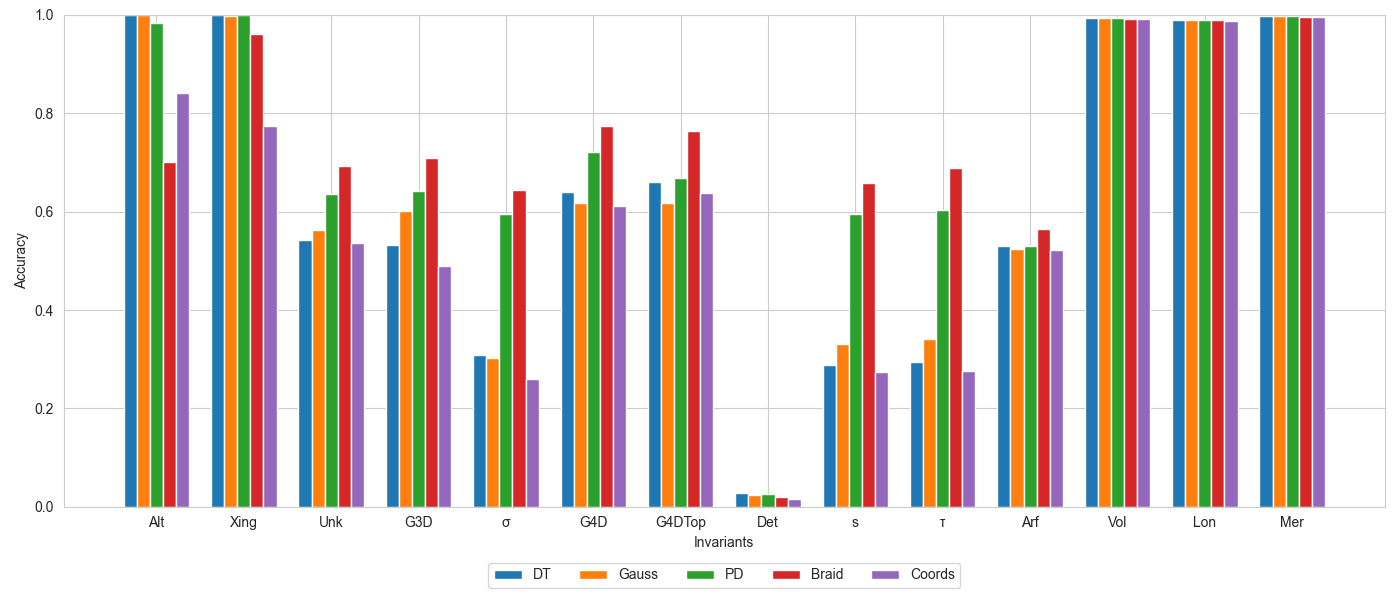
Across most of the 18 invariants tested, the answer is braid words, which consistently produced the highest classification accuracies, sometimes by a wide margin. This makes some intuitive sense: topological properties that are hard to extract from a projected 2D diagram may be more naturally accessible from an algebraic representation.
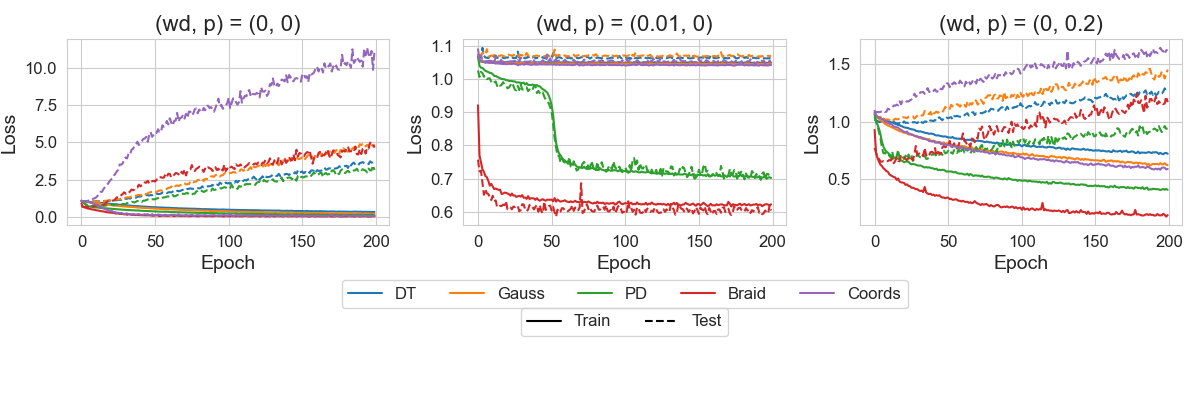
The researchers trained standard fully-connected networks (typically 4–6 layers, 256–512 neurons per layer) on each combination of representation and invariant. The results revealed a clear hierarchy:
- Easy to learn: Invariants from hyperbolic geometry (such as the hyperbolic volume of the space surrounding a knot) achieved near-perfect accuracy, sometimes above 99%.
- Moderately hard: Invariants tied to algebraic or topological data required more effort, with lower accuracies and slower training.
- Nearly impossible: Invariants from homological data (mathematical tools for classifying the “holes” in a shape, including those related to Khovanov homology) proved stubbornly resistant.
- Completely unlearnable: The Arf invariant, a binary (0 or 1) quantity characterizing knot behavior under certain algebraic operations, could not be predicted above chance for any representation tested.
The Arf invariant’s failure is striking. As a simple binary label, it should be solvable in principle. The fact that it defeats every representation suggests it encodes something structurally orthogonal to whatever features all five formats expose — a genuine puzzle.
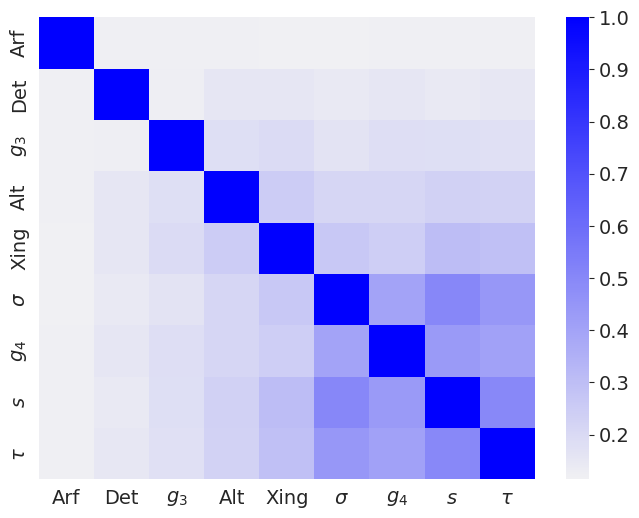
The third contribution is methodological. To probe whether two networks trained on different invariants have learned similar internal representations, the authors devised two new measures. The first is a cosine similarity score based on gradient saliency vectors: when you perturb the input, how aligned are the two networks’ attention patterns? The second is a joint misclassification score: when both networks fail on the same knot, they likely share a common blind spot rooted in a shared underlying computation.
Using these tools, networks trained on geometrically-related invariants cluster together, while networks trained on homology-linked invariants form a separate cluster, even though training was entirely independent. The mathematical structure that topologists know to exist between these invariants turns out to be recoverable from the learned neural representations.
Why It Matters
No prior study has benchmarked this range of knot invariants against this range of representations. For researchers in topology, that’s immediately useful: neural approximators can substitute for classically expensive computations where they work well, and this study tells you exactly where to trust them.
The results also address a deeper question: does neural network learnability reflect mathematical structure? The answer here is yes. Invariants that mathematicians know to be related (through polynomials, homology theories, or geometric constructions) cluster together in neural similarity space.
The Arf invariant’s resistance hints that some mathematical properties may require qualitatively different reasoning than pattern matching over sequences. That raises real questions about what structure neural networks can implicitly discover, with implications well beyond knot theory and into the broader project of using AI to explore pure mathematics.
Bottom Line: Neural networks can predict many knot invariants with high accuracy (especially given braid word inputs), and the pattern of what they can and cannot learn mirrors the deep mathematical structure of knot theory itself. The Arf invariant remains an open challenge.
IAIFI Research Highlights
Applying modern deep learning to classical problems in low-dimensional topology, the study shows that the learnability hierarchy of knot invariants reflects known mathematical relationships between them.
The paper introduces two neural similarity measures (gradient saliency cosine similarity and joint misclassification scoring) that provide interpretable tools for comparing what different networks have learned across related tasks.
Knot theory appears throughout quantum computing, string theory, and statistical mechanics; knowing which invariants are efficiently computable by neural networks expands the toolkit available to physicists working with these structures.
Future work could extend these methods to links, higher-crossing knots, or polynomial invariants like the Jones polynomial. The full study is available at [arXiv:2502.12243](https://arxiv.org/abs/2502.12243).
Original Paper Details
On the Learnability of Knot Invariants: Representation, Predictability, and Neural Similarity
2502.12243
["Audrey Lindsay", "Fabian Ruehle"]
We analyze different aspects of neural network predictions of knot invariants. First, we investigate the impact of different knot representations on the prediction of invariants and find that braid representations work in general the best. Second, we study which knot invariants are easy to learn, with invariants derived from hyperbolic geometry and knot diagrams being very easy to learn, while invariants derived from topological or homological data are harder. Predicting the Arf invariant could not be learned for any representation. Third, we propose a cosine similarity score based on gradient saliency vectors, and a joint misclassification score to uncover similarities in neural networks trained to predict related topological invariants.