
On Uncertainty Calibration for Equivariant Functions
Authors
Edward Berman, Jacob Ginesin, Marco Pacini, Robin Walters
Abstract
Data-sparse settings such as robotic manipulation, molecular physics, and galaxy morphology classification are some of the hardest domains for deep learning. For these problems, equivariant networks can help improve modeling across undersampled parts of the input space, and uncertainty estimation can guard against overconfidence. However, until now, the relationships between equivariance and model confidence, and more generally equivariance and model calibration, has yet to be studied. Since traditional classification and regression error terms show up in the definitions of calibration error, it is natural to suspect that previous work can be used to help understand the relationship between equivariance and calibration error. In this work, we present a theory relating equivariance to uncertainty estimation. By proving lower and upper bounds on uncertainty calibration errors (ECE and ENCE) under various equivariance conditions, we elucidate the generalization limits of equivariant models and illustrate how symmetry mismatch can result in miscalibration in both classification and regression. We complement our theoretical framework with numerical experiments that clarify the relationship between equivariance and uncertainty using a variety of real and simulated datasets, and we comment on trends with symmetry mismatch, group size, and aleatoric and epistemic uncertainties.
Concepts
The Big Picture
Imagine a robot that can pick up objects from any angle. Thanks to the symmetry of physical space, a good robotic arm shouldn’t need to learn separately that a cup is graspable when rotated 90 degrees versus 180 degrees. It should know this automatically. That’s the promise of symmetry-aware neural networks: bake the relevant symmetry directly into the model’s architecture, and you get better generalization with less data.
But here’s the catch: what happens when the robot says “I’m 95% confident I can grab this,” and then drops the cup? Confidence without calibration (stated probabilities that actually match how often you’re right) is worse than useless.
Researchers already understood how symmetry-awareness affects raw accuracy. What nobody had studied rigorously was how it affects a model’s confidence: whether its stated probabilities match its real-world error rates. A model that gets the right answer but doesn’t know when it might be wrong is a liability in any safety-critical system.
A team at Northeastern University, Carnegie Mellon, and the University of Trento has now tackled this. In a paper published in Transactions on Machine Learning Research, Edward Berman, Jacob Ginesin, Marco Pacini, and Robin Walters present the first formal theory connecting symmetry structure to uncertainty calibration. Their bounds are provable, and they test them on everything from molecular physics to galaxy classification.
Key Insight: Symmetry mismatch between a model and the real world doesn’t just hurt accuracy. It systematically miscalibrates confidence, making models overconfident or underconfident in predictable, theoretically-bounded ways.
How It Works
The paper ties together two foundational concepts. Equivariance means a network’s outputs transform predictably when its inputs are transformed: rotate the input molecule, and the predicted output rotates accordingly. Calibration error measures the gap between stated confidence and actual correctness. A perfectly calibrated classifier saying “70% confidence” should be right exactly 70% of the time.
Here’s the core observation: the mathematical expressions for calibration error contain the same error terms that prior work used to bound equivariant generalization. Berman et al. extended this machinery to prove upper and lower bounds on two standard metrics:
- ECE (Expected Calibration Error) — for classification tasks, measuring how far predicted probabilities deviate from empirical accuracy
- ENCE (Expected Normalized Calibration Error) — for regression tasks, measuring whether predicted uncertainty bands contain the right fraction of true values
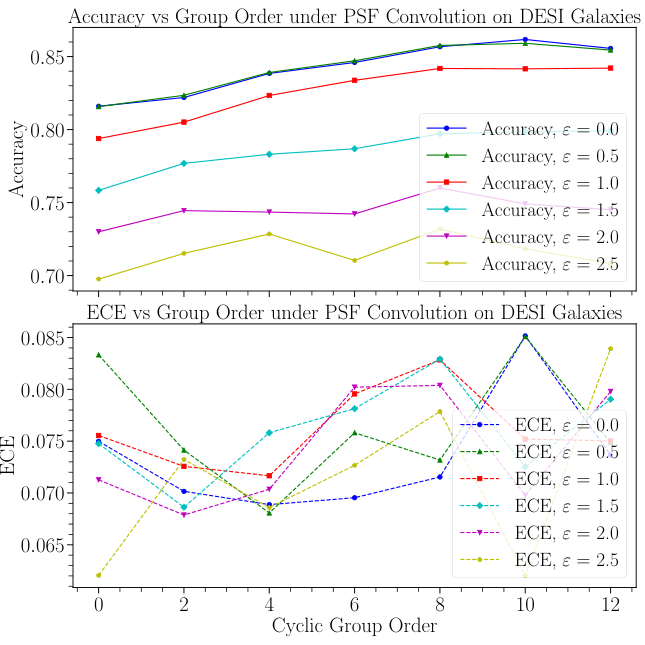
These bounds depend on the equivariance taxonomy, a classification scheme from prior work that sorts model-data relationships into three scenarios. When the model’s symmetry matches the data exactly, the bounds are tightest. If the model assumes a symmetry the data doesn’t fully obey (symmetry mismatch), the guarantees loosen. The third and worst case: applying a symmetry transformation to normal data takes it outside the range the model has seen.
They also introduced what they call the aleatoric bleed. This metric quantifies whether a model can distinguish between two fundamentally different kinds of uncertainty. Aleatoric uncertainty is irreducible randomness baked into the data itself (quantum noise, measurement limits). Epistemic uncertainty reflects the model’s own ignorance, which more data could reduce.
Confusing these two is dangerous: a model that attributes its own ignorance to fundamental randomness will never flag that it needs more training data. The aleatoric bleed puts a lower bound on how badly equivariant models conflate them.
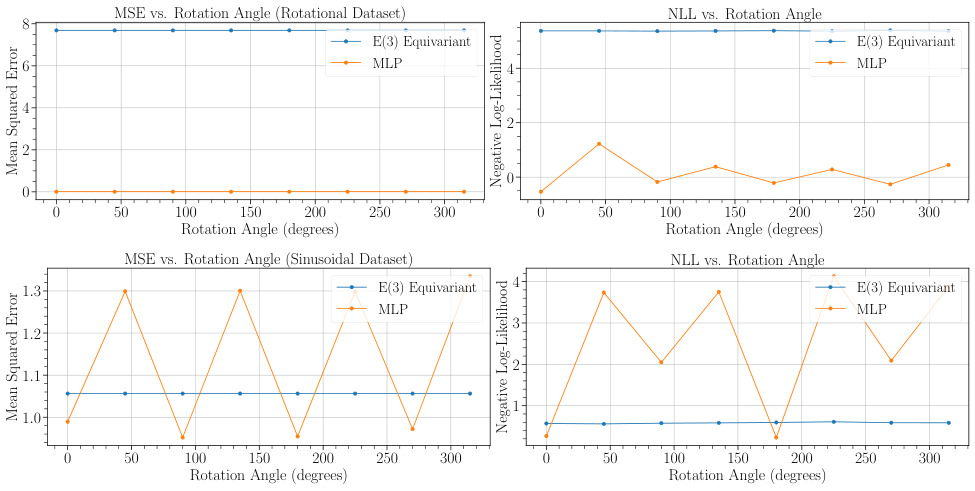
Why It Matters
Theory is only useful if it tracks reality. The team validated their bounds across a variety of settings: simulated 2D toy datasets with controlled symmetry, real molecular physics benchmarks, and galaxy morphology classification. These are exactly the data-sparse domains where equivariant networks get deployed.
The experiments matched the predictions. When assumed symmetry lined up with the data’s true symmetry, calibration was good. As mismatch grew, calibration error increased in the direction the bounds predicted.
Larger symmetry groups amplified the effect in both directions: helpful when the symmetry was real, harmful when it wasn’t. Aleatoric bleed worsened under mismatch too. Models genuinely struggled to tell apart “the data is noisy here” from “I haven’t seen enough examples here.”
Two currents in scientific AI are converging here. Physics and chemistry researchers have bet heavily on equivariant architectures for molecular dynamics, protein structure, and particle physics. Those same fields increasingly need reliable predictions. A drug discovery pipeline that doesn’t know when it’s guessing is worse than none at all.
The framework gives practitioners something concrete: a theoretical basis for anticipating how well-calibrated an equivariant model will be before running expensive experiments. If your assumed symmetry is only approximate (as it almost always is in practice), you now have a formal way to estimate the confidence penalty you’ll pay. That’s directly useful for deciding whether to invest in better data, architectural changes, or post-hoc calibration methods.
Bottom Line: Symmetry mismatch measurably miscalibrates model confidence. This work gives AI practitioners a rigorous tool for building trustworthy equivariant models in the data-scarce, high-stakes domains (molecular physics, robotics, cosmology) where they’re needed most.
IAIFI Research Highlights
This work connects the mathematical structure of physical symmetries with the practical demand for reliable AI predictions in physics domains, proving the first formal bounds linking equivariance to uncertainty calibration.
The paper introduces the aleatoric bleed metric and generalizes Expected Normalized Calibration Error to multivariate predictions, giving theoretical grounding for trustworthy machine learning in data-sparse settings.
By formalizing when symmetry-aware models are and aren't reliably confident, the work addresses calibration challenges facing AI applications in molecular physics, galaxy morphology classification, and other fundamental physics domains.
Next steps include tightening bounds for specific architectures and extending the aleatoric bleed framework to guide experimental data collection. The paper is published in *Transactions on Machine Learning Research* (January 2026) and available at [arXiv:2510.21691](https://arxiv.org/abs/2510.21691).