
Opening the AI black box: program synthesis via mechanistic interpretability
Authors
Eric J. Michaud, Isaac Liao, Vedang Lad, Ziming Liu, Anish Mudide, Chloe Loughridge, Zifan Carl Guo, Tara Rezaei Kheirkhah, Mateja Vukelić, Max Tegmark
Abstract
We present MIPS, a novel method for program synthesis based on automated mechanistic interpretability of neural networks trained to perform the desired task, auto-distilling the learned algorithm into Python code. We test MIPS on a benchmark of 62 algorithmic tasks that can be learned by an RNN and find it highly complementary to GPT-4: MIPS solves 32 of them, including 13 that are not solved by GPT-4 (which also solves 30). MIPS uses an integer autoencoder to convert the RNN into a finite state machine, then applies Boolean or integer symbolic regression to capture the learned algorithm. As opposed to large language models, this program synthesis technique makes no use of (and is therefore not limited by) human training data such as algorithms and code from GitHub. We discuss opportunities and challenges for scaling up this approach to make machine-learned models more interpretable and trustworthy.
Concepts
The Big Picture
Imagine hiring a brilliant but completely mute mathematician. She solves every problem you give her (long division, sorting algorithms, pattern matching) with perfect accuracy. But she can’t explain her work. She just hands you the answer. You know that she solved it; you have no idea how.
That’s where AI researchers stand with modern neural networks. These systems learn to perform complex tasks, sometimes better than any human algorithm, but their internal computations remain opaque, trapped inside billions of numbers. The field of mechanistic interpretability (figuring out, step by step, what a network is actually doing inside) has grown up to crack this opacity open, mostly through painstaking human analysis. A team at MIT and IAIFI is now asking a bolder question: can we automate that process entirely?
Their answer is MIPS (Mechanistic Interpretability-based Program Synthesis), a system that watches a neural network solve problems, reverse-engineers what it learned, and writes clean Python code that does the same thing. No human interpretation required.
Key Insight: MIPS can look inside a trained neural network, extract the algorithm it discovered, and express it as readable Python code, solving problems that even GPT-4 can’t crack and using zero human-written code as training data.
How It Works
The MIPS pipeline turns a black-box neural network into human-readable code in four stages.
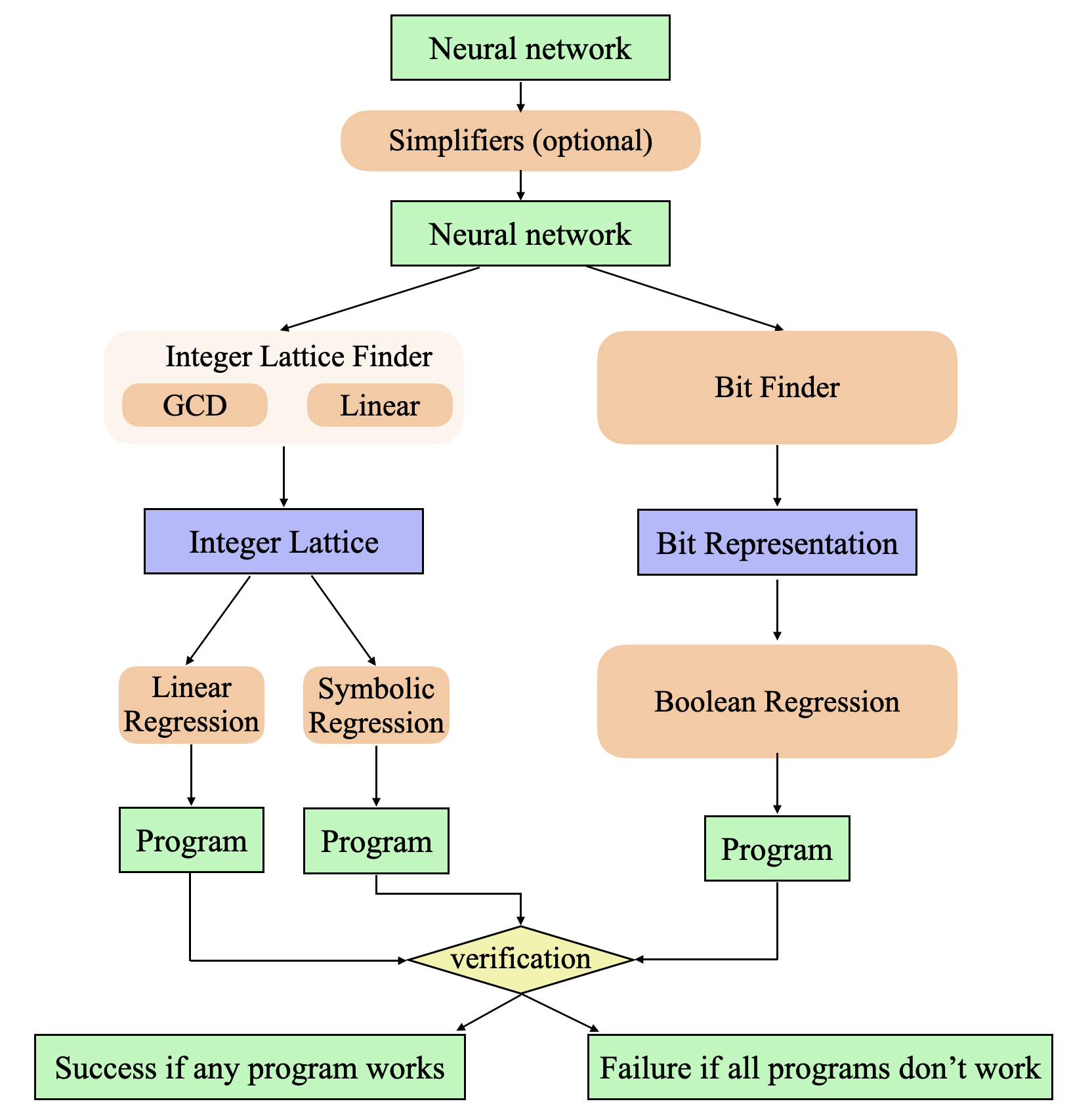
Stage 1: Train a neural network to learn the task. MIPS uses a recurrent neural network (RNN), a network that processes sequences by maintaining a running “memory” called a hidden state. The team also runs an AutoML search, an automated process that tries thousands of different network designs, to find the simplest RNN that achieves perfect accuracy. Simpler networks are easier to reverse-engineer. The search space spans over 75 million possible configurations.
Stage 2: Simplify the network. MIPS prunes and compresses the trained network to strip out redundancy, making later analysis cleaner.
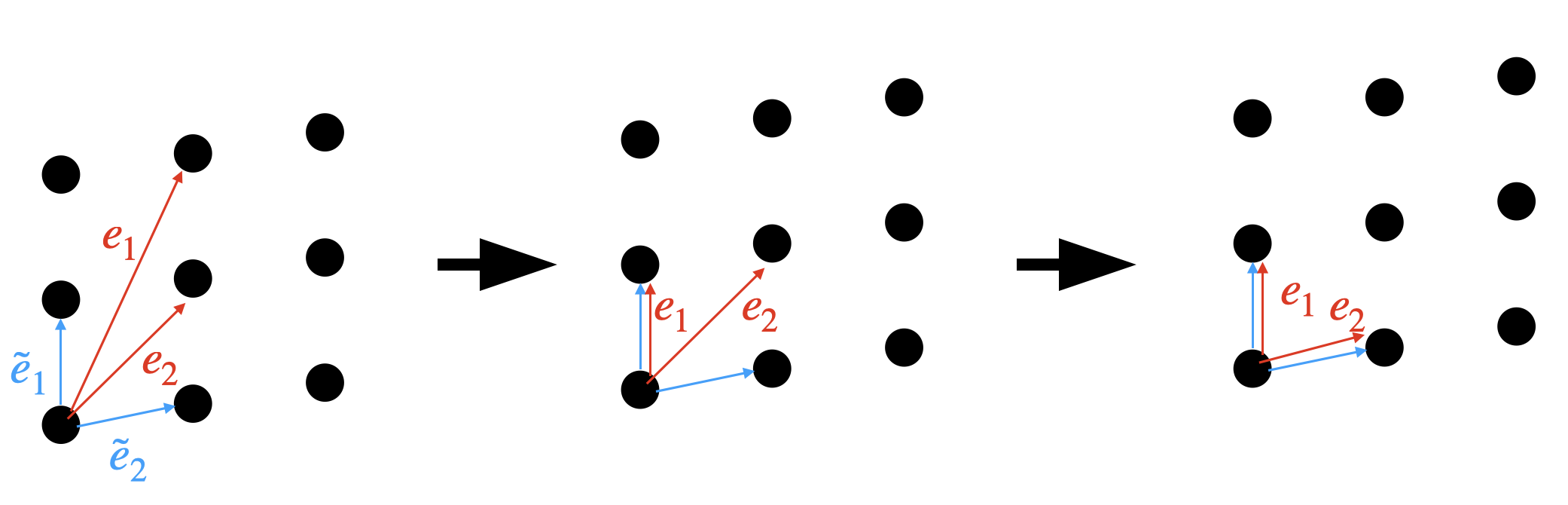
Stage 3: Convert to a finite state machine. When a network processes discrete inputs (integers, tokens, symbols), its hidden states cluster into groups rather than wandering freely through space. MIPS uses an integer autoencoder, a compression tool that describes each cluster using only whole numbers or yes/no flags, to discover that these clusters often sit on a regular, grid-like arrangement. Each point in that grid is one possible “mode” the network can be in. The continuous RNN becomes a crisp finite state machine: a lookup table mapping state-plus-input to next state.
Stage 4: Apply symbolic regression. With a finite state machine in hand, MIPS applies symbolic regression, a search for compact mathematical formulas that fit the data, to find the rules governing state transitions. The result is Python code that faithfully implements the algorithm the network discovered on its own.
The team tested MIPS against a benchmark of 62 algorithmic tasks: detecting balanced parentheses, computing modular arithmetic, tracking state through a sequence. They compared it to GPT-4, which tackles the same benchmark by generating code from verbal problem descriptions.
- GPT-4 solved 30 of 62 tasks
- MIPS solved 32 of 62 tasks
- 13 tasks solved by MIPS were not solved by GPT-4
- 11 tasks solved by GPT-4 were not solved by MIPS
They’re not just close in score; they’re solving different problems. GPT-4 draws on vast human-written code to recognize familiar patterns. MIPS uses zero human training data, discovering algorithms from scratch by watching a network think. Together, the two approaches solve problems that neither could handle alone.
Why It Matters
MIPS goes after one of the hard problems in AI: we increasingly deploy systems we don’t understand. A network that aces benchmarks may still fail in subtle, dangerous ways when conditions shift, and we usually can’t tell why because we don’t know how it worked in the first place. Automatically extracting the algorithm a network learned would let us audit it, verify it, and trust it far more completely.
This is a proof of concept that automated interpretability is achievable, at least for small RNNs on well-defined tasks. The authors are upfront that scaling to large transformer models (the kind powering today’s AI assistants) remains a major challenge. Transformers are vastly more complex, and their hidden states don’t cluster as neatly. But the direction is clear: find the right representation and you can extract the algorithm.
There’s a physics angle too. The tools MIPS uses (symbolic regression, sparse representations, minimal descriptions) are the same tools physicists use to discover natural laws from data. The integer autoencoder is essentially finding the “quantum numbers” of the network’s internal states: the conserved quantities that characterize its behavior. Treating neural networks as physical systems to be understood, not just engineered, is a distinctly IAIFI way of thinking.
Bottom Line: MIPS shows that neural networks can be reverse-engineered automatically, turned from opaque black boxes into readable code. It solves 13 problems GPT-4 cannot, suggesting that human-free algorithm discovery is a powerful complement to LLM-based coding.
IAIFI Research Highlights
MIPS applies physics-inspired tools (symbolic regression, minimal representations, finite-state abstractions) to AI interpretability, treating neural networks as physical systems whose internal "laws" can be discovered from observation.
Fully automated mechanistic interpretability solves 32 of 62 algorithmic benchmark tasks, opening a path toward auditable, trustworthy AI systems that require no human-written training data.
The integer autoencoder technique provides a general framework for discovering discrete, structured representations inside continuous neural networks, with broad applications across scientific machine learning.
Future work will push MIPS beyond small RNNs to larger transformer architectures. The paper is available at [arXiv:2402.05110](https://arxiv.org/abs/2402.05110) and represents a collaboration between MIT CSAIL and the IAIFI.