
Parameter Symmetry Potentially Unifies Deep Learning Theory
Authors
Liu Ziyin, Yizhou Xu, Tomaso Poggio, Isaac Chuang
Abstract
The dynamics of learning in modern large AI systems is hierarchical, often characterized by abrupt, qualitative shifts akin to phase transitions observed in physical systems. While these phenomena hold promise for uncovering the mechanisms behind neural networks and language models, existing theories remain fragmented, addressing specific cases. In this position paper, we advocate for the crucial role of the research direction of parameter symmetries in unifying these fragmented theories. This position is founded on a centralizing hypothesis for this direction: parameter symmetry breaking and restoration are the unifying mechanisms underlying the hierarchical learning behavior of AI models. We synthesize prior observations and theories to argue that this direction of research could lead to a unified understanding of three distinct hierarchies in neural networks: learning dynamics, model complexity, and representation formation. By connecting these hierarchies, our position paper elevates symmetry -- a cornerstone of theoretical physics -- to become a potential fundamental principle in modern AI.
Concepts
The Big Picture
Physics has a superpower most sciences envy: the ability to discover one principle that explains everything. The Standard Model, general relativity, thermodynamics: each swept away a jungle of disconnected observations and replaced it with a single elegant framework. Now, researchers from MIT and EPFL think they’ve found something similar hiding inside neural networks. The secret ingredient? Symmetry.
Here’s the puzzle. Modern AI systems learn in a strangely jerky way (not smoothly, but in sudden leaps). A language model abruptly “gets” grammar. A vision network suddenly recognizes depth. These sudden jumps (phase transitions, in physicists’ language) look uncannily like what happens when water freezes or a magnet forms. Separately, researchers have noticed that neural networks compress information in layered, hierarchical ways, and that different AI models end up learning strangely similar internal patterns. Each of these phenomena has its own mini-theory. None have been explained together.
This paper is a position paper (a bold intellectual bet) arguing that a single concept from theoretical physics, parameter symmetry (roughly: you can rearrange a model’s internal settings without changing what it does), is the thread that ties all these mysteries together.
Key Insight: When a neural network learns, it navigates a landscape carved by symmetries, and the dramatic, abrupt moments of learning correspond to symmetry breaking and restoration events, just like phase transitions in physical matter.
How It Works
A symmetry exists when you can transform a model’s parameters (rearranging, scaling, or flipping them) and get exactly the same output. It’s like a square: rotate it 90 degrees and it looks identical. Table 1 of the paper catalogs a surprisingly long list of such symmetries lurking in everyday neural network architectures:
- Permutation symmetries in dense layers: swapping neurons doesn’t change the function
- Rescaling symmetries in networks using ReLU activations (a common threshold-style mathematical operation)
- Rotation symmetries in self-supervised learning (training without labeled data)
The researchers define two key states: a symmetric state, where parameters sit in a configuration fully described by a symmetry (like a coin balanced perfectly on its edge), and a symmetry-broken state, where they don’t. The central hypothesis: transitions between these states produce the hierarchical, stepped behavior we observe during training.
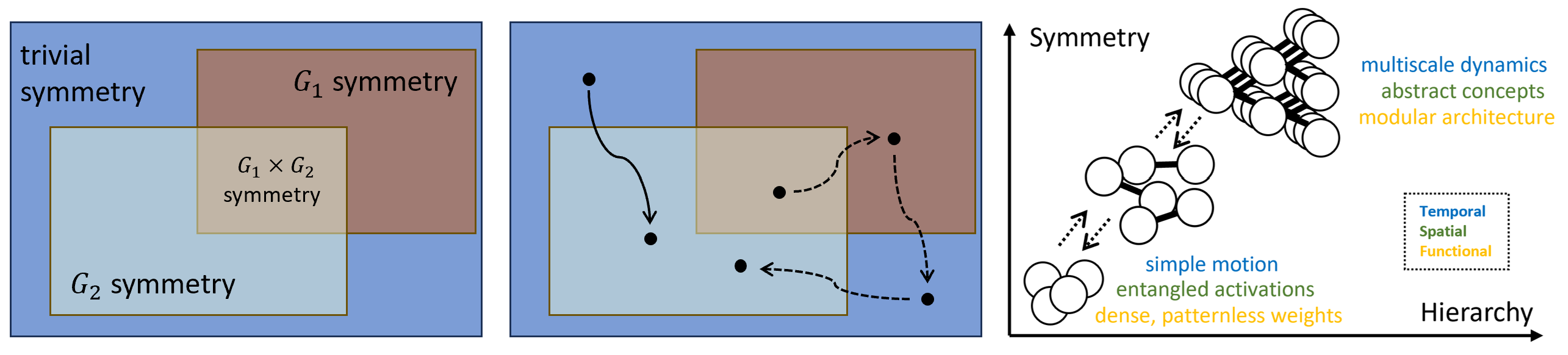
The paper organizes its argument around three distinct hierarchies this framework can explain:
- Temporal hierarchy (learning dynamics): Sudden capability jumps during training correspond to transitions between different symmetry groups. The model “snaps” from one symmetric configuration to another, producing the abrupt shifts visible on loss curves and benchmark scores.
- Functional hierarchy (model complexity): Networks learn simpler functions first, then progressively more complex ones. High-symmetry parameter states correspond to restricted, low-complexity functions; as symmetry breaks, complexity unlocks in a controlled, hierarchical sequence.
- Spatial hierarchy (representations): Layer by layer through a deep network, early layers encode raw features, later layers encode abstract concepts, and the final layer often collapses to a structure called neural collapse, where every example of the same category converges to a single sharp point in the network’s internal space. This progression mirrors symmetry breaking and restoration across network depth.
What makes this more than speculation: each claim is backed by citations to prior empirical and theoretical work. The authors aren’t introducing a new theorem; they’re weaving together existing results and showing that symmetry is the common warp thread running through all of them.
The framework also has a practical edge. Recent work has made it possible to deliberately engineer parameter symmetries into models at design time. If the hypothesis holds, researchers could tune a model’s hierarchical learning dynamics by specifying its symmetry structure upfront, the way physicists design materials with target properties by choosing crystal symmetry groups.
Why It Matters
The deepest implication here isn’t technical: it’s philosophical. For decades, AI researchers and physicists have circled each other warily. Physicists see neural networks as messy empirical objects, far from the clean symmetry principles they love. AI researchers see physics as elegant but irrelevant to billion-parameter transformers trained on internet text.
This paper attempts a genuine peace treaty: symmetry (the cornerstone of modern physics from electromagnetism to the Higgs boson) may also be a fundamental principle of intelligence. If the hypothesis survives scrutiny, the payoff is enormous. A unified theory of deep learning would give practitioners a design vocabulary for building better models, not through brute-force scaling but through principled symmetry engineering. It would give theorists a shared language for connecting phenomena that currently require separate mathematical frameworks. And it would deepen a striking parallel between how the universe organizes matter and how neural networks organize knowledge.
The paper is refreshingly honest: the evidence, while suggestive, is not yet definitive.
Bottom Line: Parameter symmetry may be to deep learning what thermodynamic laws are to heat: a unifying framework that transforms a zoo of disconnected phenomena into a single principled story. This position paper lays out the case; proving it will be one of the most important tasks in AI theory.
IAIFI Research Highlights
This work directly imports the language of symmetry groups and phase transitions from theoretical physics into deep learning theory, treating neural network training as a physical system governed by symmetry-breaking dynamics.
By proposing parameter symmetry as a unifying principle, the paper offers a path toward a coherent theory of deep learning that explains learning dynamics, model complexity, and representation formation within a single framework.
The work elevates symmetry (the organizing principle behind gauge theories and the Standard Model) to a potential fundamental principle of artificial intelligence, deepening the conceptual bridge between physics and computation.
Future work will need to formally validate the symmetry-breaking hypotheses across diverse architectures and tasks; the paper is available at [arXiv:2502.05300](https://arxiv.org/abs/2502.05300).