
Pareto-optimal clustering with the primal deterministic information bottleneck
Authors
Andrew K. Tan, Max Tegmark, Isaac L. Chuang
Abstract
At the heart of both lossy compression and clustering is a trade-off between the fidelity and size of the learned representation. Our goal is to map out and study the Pareto frontier that quantifies this trade-off. We focus on the optimization of the Deterministic Information Bottleneck (DIB) objective over the space of hard clusterings. To this end, we introduce the primal DIB problem, which we show results in a much richer frontier than its previously studied Lagrangian relaxation when optimized over discrete search spaces. We present an algorithm for mapping out the Pareto frontier of the primal DIB trade-off that is also applicable to other two-objective clustering problems. We study general properties of the Pareto frontier, and we give both analytic and numerical evidence for logarithmic sparsity of the frontier in general. We provide evidence that our algorithm has polynomial scaling despite the super-exponential search space, and additionally, we propose a modification to the algorithm that can be used where sampling noise is expected to be significant. Finally, we use our algorithm to map the DIB frontier of three different tasks: compressing the English alphabet, extracting informative color classes from natural images, and compressing a group theory-inspired dataset, revealing interesting features of frontier, and demonstrating how the structure of the frontier can be used for model selection with a focus on points previously hidden by the cloak of the convex hull.
Concepts
The Big Picture
Imagine you’re packing for a long trip, but your suitcase has a strict weight limit. You can’t bring everything, so you make choices: keep the essentials, ditch the rest. But how do you optimally decide what counts as essential? That question sits at the heart of one of the deepest problems in information theory, and it turns out, in machine learning too.
The core challenge is a fundamental tension: the more you compress data, the less information you retain. Squeeze too hard and details blur. Hold too loosely and you’re not compressing at all. For decades, researchers have studied this trade-off mathematically, but most approaches only revealed a partial picture, a smooth curve that obscured rich, discrete structure hiding beneath.
A new paper from MIT and IAIFI researchers Andrew Tan, Max Tegmark, and Isaac Chuang maps that hidden terrain in full. Their central contribution: a new algorithmic framework for mapping out the complete set of best possible trade-offs (the Pareto frontier) between compression and information retention. Every point on this frontier represents a balance where you can’t squeeze data any harder without losing something meaningful, and you can’t preserve any more without giving up compression.
The framework applies to the Deterministic Information Bottleneck (DIB), a mathematical approach to finding the most informative way to group inputs into clusters. The team demonstrates it on tasks ranging from compressing the English alphabet to classifying color in natural images.
Key Insight: By solving the clustering problem directly, keeping both competing objectives separate rather than blending them into a single number, the researchers reveal a much richer set of optimal clusterings that are completely invisible to conventional approaches.
How It Works
The standard approach to the Information Bottleneck (and its deterministic variant, DIB) takes two competing objectives and combines them into a single score using a trade-off parameter β. This is the Lagrangian relaxation: pick β, optimize, get one point on the frontier. Sweep β across values and you trace a curve. Simple, but with a critical blind spot.
The Lagrangian approach only finds solutions on the convex hull of the feasible solution space. Picture the outermost skin stretched tightly around all possible solutions. Everything tucked inside is missed. In discrete problems, where encodings are hard assignments of inputs to clusters, many optimal solutions live inside the convex hull, geometrically unreachable by any choice of β. These solutions are Pareto optimal (you can’t improve one objective without sacrificing the other) but no Lagrangian scan will ever find them.
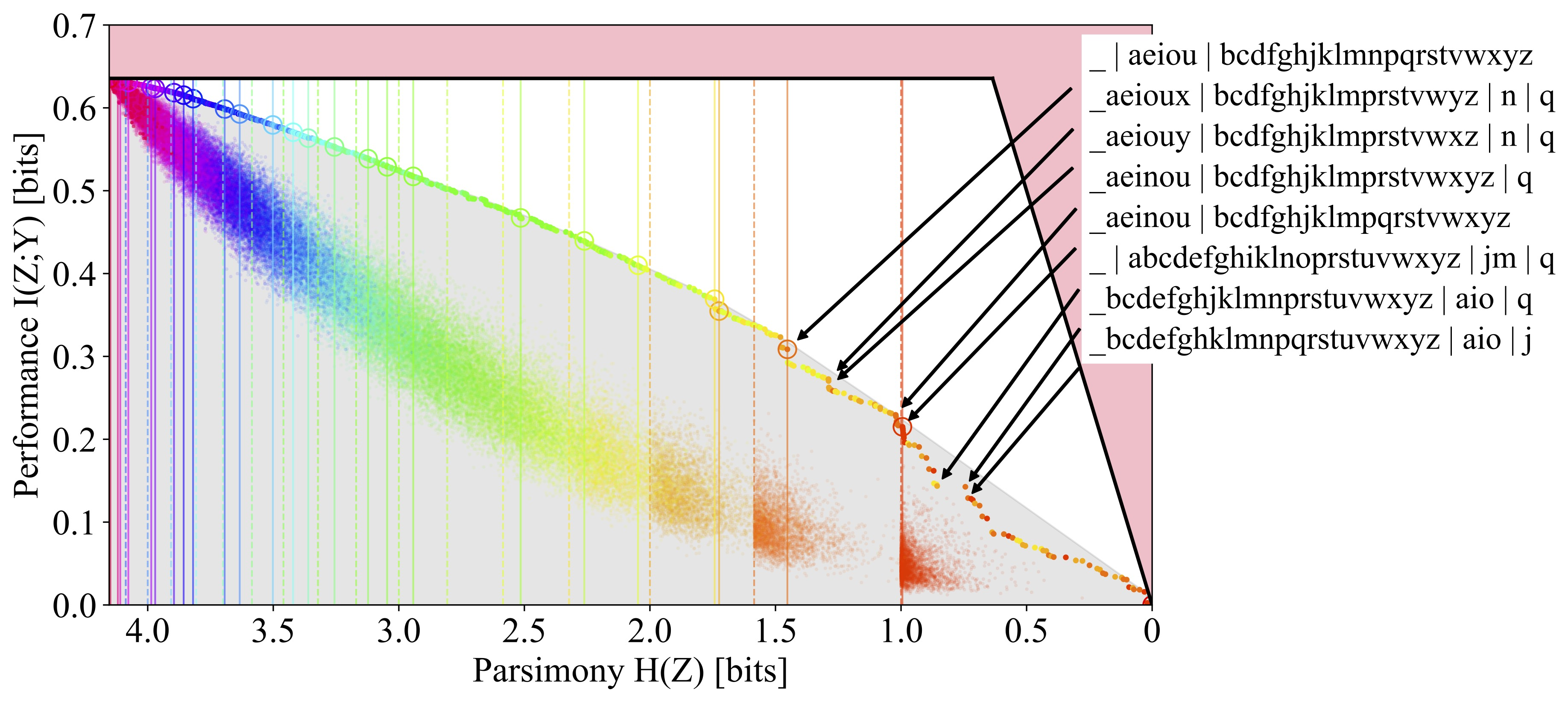
The figure above makes this concrete. On the left, the Lagrangian DIB frontier looks sparse and smooth. On the right, the primal DIB frontier, solved directly, exposes a staircase of discrete optimal clusterings. Most of these lie inside the convex hull and are completely invisible to the Lagrangian approach.
So the authors tackle the primal DIB problem head-on: instead of combining objectives into a single scalar, keep them separate and look for clusterings that genuinely maximize preserved information for a given entropy constraint. The search space grows super-exponentially with input size, which makes brute force impossible. Their solution, Pareto Mapper, is an ε-greedy agglomerative search:
- Start with the “identity clustering,” where every input sits in its own cluster.
- Iteratively consider all pairwise merges of existing clusters.
- Evaluate each merge on both objectives: entropy reduction and mutual information with the target.
- Add Pareto-optimal points to a maintained frontier; probabilistically explore near-Pareto points using the ε-greedy acceptance criterion.
- Continue until the queue is exhausted.
The ε parameter controls exploration. High ε chases leads far from the current frontier, useful when sampling noise is significant. Low ε keeps the search tight. The result is an approximate Pareto frontier discovered in polynomial time, despite a super-exponential search space.
Why It Matters
Model selection, choosing the right number of clusters or compression level, is typically done by picking a single β and solving. But this hides structure.
The primal frontier reveals natural “corners”: sharp bends in the Pareto curve where a small increase in entropy yields a large gain in information retention. These corners are stable, meaningful, and often correspond to the right number of clusters for a given dataset. The Lagrangian approach, by flattening the frontier onto a convex hull, obscures exactly these decision-relevant features.
Three applications show how broadly this matters. Compressing the English alphabet (mapping 26 letters to fewer clusters based on co-occurrence statistics) yields linguistically meaningful groupings on the primal frontier. For natural image color classification, color categories emerge at different compression levels. And for a group theory-inspired synthetic dataset with mathematically known structure, the frontier’s shape aligns with the algebraic structure of the data, serving as ground-truth validation.
There’s also a clean theoretical result: Pareto-optimal frontiers are logarithmically sparse. The number of distinct optimal clusterings grows only as the logarithm of the total number of possible encodings. This explains why Pareto Mapper can work at all. The needle of optimality is rare, but the haystack shrinks faster than you’d expect.
Bottom Line: Tackling the Pareto frontier of clustering directly, rather than through convex relaxation, unlocks a richer map of the compression-information trade-off and provides a principled new toolkit for model selection in machine learning.
IAIFI Research Highlights
This work applies information-theoretic tools from physics (entropy, mutual information, rate-distortion theory) directly to machine learning clustering. Concepts central to statistical mechanics turn out to illuminate the structure of learning algorithms.
Pareto Mapper gives a computationally efficient method for discovering the full frontier of any two-objective hard clustering problem. It surfaces optimal solutions that standard Lagrangian approaches miss entirely, enabling better-informed model selection.
The structure of learned representations, even for abstract tasks like alphabet compression, reflects deep information-theoretic principles. This points toward a more fundamental understanding of what makes representations meaningful.
Future directions include extending primal DIB analysis to soft clusterings and higher-dimensional objective spaces. The full paper is available at [arXiv:2204.02489](https://arxiv.org/abs/2204.02489).