
Physics of Skill Learning
Authors
Ziming Liu, Yizhou Liu, Eric J. Michaud, Jeff Gore, Max Tegmark
Abstract
We aim to understand physics of skill learning, i.e., how skills are learned in neural networks during training. We start by observing the Domino effect, i.e., skills are learned sequentially, and notably, some skills kick off learning right after others complete learning, similar to the sequential fall of domino cards. To understand the Domino effect and relevant behaviors of skill learning, we take physicists' approach of abstraction and simplification. We propose three models with varying complexities -- the Geometry model, the Resource model, and the Domino model, trading between reality and simplicity. The Domino effect can be reproduced in the Geometry model, whose resource interpretation inspires the Resource model, which can be further simplified to the Domino model. These models present different levels of abstraction and simplification; each is useful to study some aspects of skill learning. The Geometry model provides interesting insights into neural scaling laws and optimizers; the Resource model sheds light on the learning dynamics of compositional tasks; the Domino model reveals the benefits of modularity. These models are not only conceptually interesting -- e.g., we show how Chinchilla scaling laws can emerge from the Geometry model, but also are useful in practice by inspiring algorithmic development -- e.g., we show how simple algorithmic changes, motivated by these toy models, can speed up the training of deep learning models.
Concepts
The Big Picture
Watch a row of dominoes fall. The first tile tips, strikes the second, which strikes the third, each collapse triggering the next in a crisp, satisfying cascade. Now imagine that same dynamic playing out inside a neural network across millions of training steps. This is what a team of MIT physicists discovered when they looked closely at how language models actually learn.
When you train a neural network on multiple tasks at once (grammar rules, arithmetic, logical reasoning), you might expect all these skills to improve roughly together, proportional to how often each appears in the training data. The reality is far stranger. Skills develop in sequence. One ability plateaus, then another suddenly surges. The network doesn’t multitask; it single-tasks in rapid succession, like a student who hyperfocuses on one subject until mastery, then pivots to the next.
Researchers Ziming Liu, Yizhou Liu, Eric Michaud, Jeff Gore, and Max Tegmark set out to build a physics-like theory of this behavior, and in doing so, unlocked surprising connections between neural network training, thermodynamics, and the famous Chinchilla scaling laws that govern how to optimally train large language models.
Key Insight: Neural networks learn skills in a sequential “Domino effect,” and physicists at MIT have built three increasingly simple models to explain why, with practical implications for training modern AI systems faster.
How It Works
The team’s approach is deliberately old-fashioned. Physicists have a long tradition of making absurdly simplified models (the “spherical cow in a vacuum”) that strip away messy reality to reveal underlying structure. The researchers asked: can we do the same for skill learning?
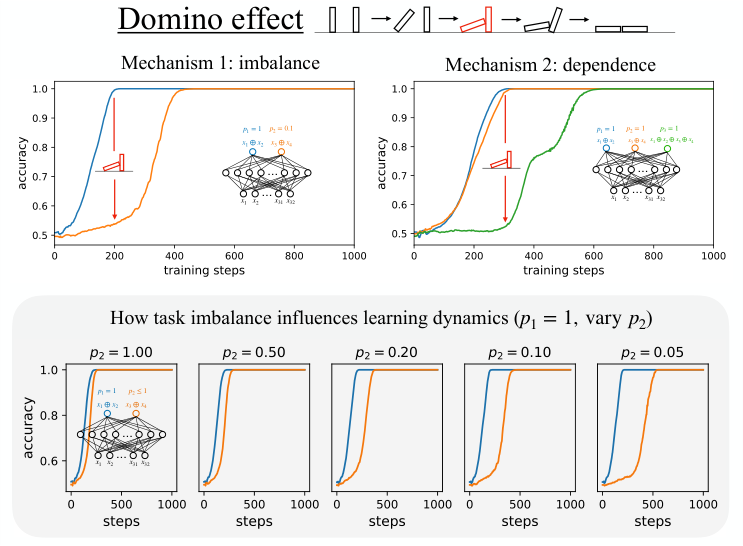
Start with an observation. Train a two-layer neural network on two independent sparse parity tasks (yes/no pattern-recognition puzzles presented at different frequencies, p₁ = 1 and p₂ = 0.1). Task 1 completes learning, and then Task 2 takes off almost immediately.
You might expect this: Task 1 is ten times more frequent, so of course it learns first. But here’s the surprise: Task 2 finishes in just twice the time of Task 1, not ten times as long. Completing Task 1 accelerates Task 2, as if resources suddenly became available. This is the Domino effect: skills learned sequentially, each completion triggering the next.
To explain it, the team constructs three models at different levels of abstraction:
- The Geometry Model: The most realistic. Treats each skill as a direction in the network’s parameter space. Learning signals from different tasks compete geometrically: perpendicular signals are independent, while aligned ones speed or slow each other’s progress.
- The Resource Model: Coarser, but analytically tractable. Treats the network’s “capacity” as a shared resource that skills compete to capture. When one skill monopolizes it, others stagnate; when it finishes, resources flood to the next. This maps the problem onto thermodynamics: skills as phases, training as a phase transition (a sudden, dramatic shift, like water freezing into ice).
- The Domino Model: The simplest. Assumes a strict hierarchy where you cannot learn Task B until Task A is complete. Pure sequential learning, ideal for analyzing modularity.
Each model sacrifices something for clarity. The Domino model can’t capture partial simultaneous learning, but enables clean analytical results. The Geometry model reproduces actual training curves but resists simple analysis. The Resource model sits in the middle, elegant enough for mathematics, realistic enough to match experiments on compositional tasks.
The paper’s most striking result is what falls out of these toy models. The Geometry model, when analyzed carefully, reproduces the Chinchilla scaling laws, empirical rules discovered by DeepMind specifying the optimal ratio of training tokens to model size. The physics of how skill directions interact in parameter space encodes the same information as a multi-billion-dollar empirical study of large language models.
The Resource model makes precise predictions about compositional tasks, problems requiring mastery of sub-skills before tackling the full challenge. It explains why added compositional depth dramatically slows learning: each layer of dependency means another domino must fall before the next can start.
Why It Matters
The practical payoff is as important as the theory. Inspired by the Resource model’s picture of skills competing for attention, the team developed simple algorithmic modifications (changes to how training examples are weighted and how learning signals are scaled) that measurably speed up learning on benchmark tasks. Theory didn’t just explain what’s happening; it told engineers where to push.
More broadly, this work represents a bet that the right tools for understanding AI are the ones physicists have used for a century: stripping complex systems to their essential structure, building toy models that ignore the noise to expose the signal, and having the courage to make things absurdly simple. The Geometry model’s connection to Chinchilla laws suggests that scaling laws might have a deeper mechanistic explanation, rooted in how skills compete in parameter space rather than empirical curve-fitting. That’s a profound shift in how we think about what scaling laws are.
Open questions remain: Can these models extend to transformers trained on language at scale? Do real language models show measurable Domino effects between identifiable skills? Can the training speedups scale to frontier models? The framework is young, but the dominoes are already falling.
Bottom Line: By treating neural networks the way physicists treat gases (building simplified models that capture essential structure), this team explains why AI systems learn skills in sudden cascades, and shows how that understanding can make training faster. The same mathematics that explains ideal gases now explains why GPT learns grammar before trigonometry.
IAIFI Research Highlights
This work applies classical physics methodology (coarse-graining, effective theories, and toy models) to explain emergent learning dynamics in neural networks, building a bridge between statistical physics and deep learning theory.
The three-model framework explains the Domino effect from first principles, connects to Chinchilla scaling laws, and produces practical training algorithms that accelerate learning on compositional tasks.
By framing neural network training as a resource competition problem with phase-transition-like dynamics, the work reveals structural analogies between learning systems and physical systems governed by constrained resource allocation.
Future work will test whether Domino-effect dynamics appear in large-scale language models and whether the algorithmic improvements generalize to frontier architectures. The full paper is available at [arXiv:2501.12391](https://arxiv.org/abs/2501.12391) and code at [github.com/KindXiaoming/physics_of_skill_learning](https://github.com/KindXiaoming/physics_of_skill_learning).