
Presenting Unbinned Differential Cross Section Results
Authors
Miguel Arratia, Anja Butter, Mario Campanelli, Vincent Croft, Aishik Ghosh, Dag Gillberg, Kristin Lohwasser, Bogdan Malaescu, Vinicius Mikuni, Benjamin Nachman, Juan Rojo, Jesse Thaler, Ramon Winterhalder
Abstract
Machine learning tools have empowered a qualitatively new way to perform differential cross section measurements whereby the data are unbinned, possibly in many dimensions. Unbinned measurements can enable, improve, or at least simplify comparisons between experiments and with theoretical predictions. Furthermore, many-dimensional measurements can be used to define observables after the measurement instead of before. There is currently no community standard for publishing unbinned data. While there are also essentially no measurements of this type public, unbinned measurements are expected in the near future given recent methodological advances. The purpose of this paper is to propose a scheme for presenting and using unbinned results, which can hopefully form the basis for a community standard to allow for integration into analysis workflows. This is foreseen to be the start of an evolving community dialogue, in order to accommodate future developments in this field that is rapidly evolving.
Concepts
The Big Picture
Imagine describing a mountain range using only a bar chart. You divide the terrain into columns, record the average height in each, and call it a day. You’d capture the general shape but lose the individual peaks, the subtle valleys, the precise contours that make each ridge unique. For nearly a century, particle physicists have done something roughly analogous: measuring collision outcomes by sorting events into discrete bins and counting how many fall into each bucket. It works, but the information lost in that sorting quietly limits what scientists can do with the data.
Machine learning is changing that. New algorithms can now process raw, continuous collision data with no binning required. The result is a richer kind of measurement called an unbinned differential cross section (a continuous, full-detail map of how often each type of collision outcome occurs), where every event retains its precise coordinates in a potentially high-dimensional space.
The problem? Nobody agreed on how to publish this data. A group of thirteen physicists from labs across Europe and North America set out to fix that, proposing the first community standard for sharing unbinned results. This paper isn’t about a new detector or a new discovery. It’s about the infrastructure that will let unbinned measurements actually reach the scientists who need them.
Key Insight: Unbinned measurements preserve far more information than traditional histograms, but their scientific value is zero if the community can’t agree on how to store and share them. This paper proposes the format that makes that possible.
How It Works
Why do physicists bin data in the first place? A differential cross section measures how likely a particular collision outcome is as a function of some observable, say, the angle of a scattered particle. Traditionally, you divide that angle into a grid of bins, count events in each, and report the histogram. Easy to visualize, easy to store, easy to compare with theory.
The catch: you have to choose your bins before analyzing the data, and the optimal binning depends on what you want to do with the result. A parton distribution function (PDF) fit, which extracts the internal quark-and-gluon structure of protons, needs different bin boundaries than an effective field theory analysis (a framework for detecting how undiscovered particles might subtly alter known physics). With a binned result, you’re locked into whatever choices the original experimenters made.
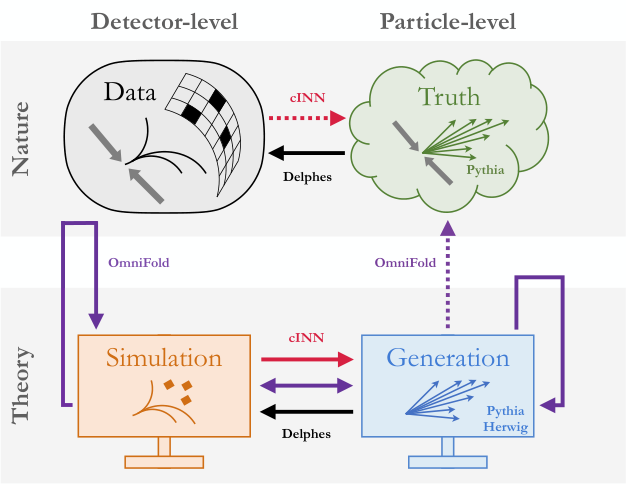
Unbinned measurements dissolve this problem. Instead of a histogram, an unbinned result is a density estimate: a continuous function assigning a probability weight to every possible collision outcome. Need a PDF fit? Bin it however that analysis requires. New theoretical calculation arrives years later? Re-bin the stored density. No new experiment needed.
The paper describes two technical approaches for producing these density estimates:
- Density-based models directly learn the probability distribution of the data, corrected for detector smearing effects (the way real detectors blur precise particle trajectories into approximate measurements). These produce an explicit function you can evaluate anywhere.
- Classifier-based models train a neural network to distinguish real data from a reference simulation, then extract the density ratio. These are often easier to train under experimental conditions.
Both approaches output the same thing for archiving: per-event weights encoding each event’s position in the unfolded distribution, the underlying true physics signal corrected for detector effects.
Publishing an unbinned result means releasing something more complex than a table of bin counts. The authors propose storing results as collections of weighted pseudo-data points. Each event carries coordinates in the observable space plus a weight representing its contribution to the cross section. The format must also encode systematic uncertainties, which in the unbinned world aren’t simple percentage errors but correlated shifts across the entire continuous distribution.
A few statistical subtleties need explicit handling. Acceptance effects (the fact that detectors don’t catch every particle) must be folded in. Background subtraction enters through negative-weight events rather than subtracted bin counts. And local statistical uncertainty gets special treatment, since a density estimate is smoothly defined even where only a handful of events exist.
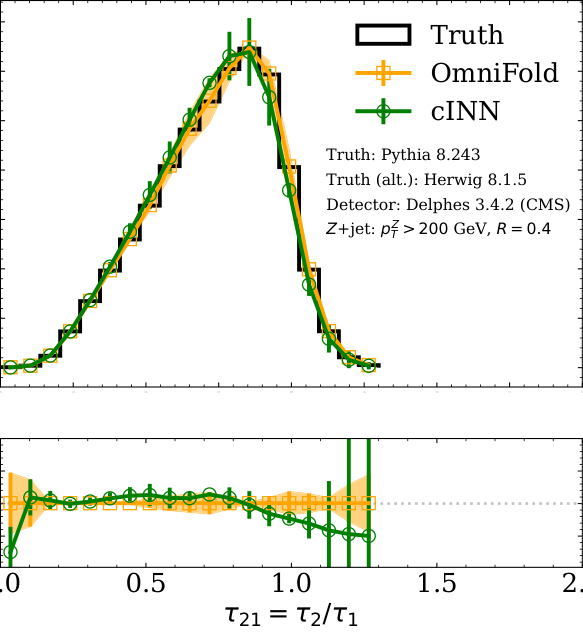
The proposed format handles all of this through a structured file schema integrated with HEPData, the existing community repository for particle physics measurements. Shared reference software lets theorists and phenomenologists immediately start using unbinned results in global fits. A worked example walks through the full pipeline: simulated dataset, unbinned unfolding, proposed format, then re-binned comparison with a traditional analysis. The agreement validates the approach and makes the information-preservation advantage concrete.
Why It Matters
One of the most promising possibilities here is derivative measurements: defining new observables after the measurement is already done. Instead of histogramming a single kinematic variable (a measurable quantity describing a particle’s motion, such as its speed or angle), you publish the full multi-dimensional distribution. When theorists later identify a combination of variables sensitive to a new physics effect, they construct that observable directly from the stored data. No new experiment, no new beamtime.
This matters most in high dimensions. Modern ML unfolding algorithms handle dozens of correlated observables simultaneously, mapping out entire regions of phase space (the full range of possible collision outcomes). Traditional binning in ten dimensions would require astronomically many bins. Unbinned methods handle this naturally.
The payoff for global physics analyses is real. Experiments at ATLAS, CMS, LHCb, and other major detectors at CERN regularly combine measurements to extract fundamental parameters of the Standard Model, the established theory describing all known particles and forces. With binned results, downstream fits must accept each experiment’s fixed histogram choices. With unbinned results, the community could iteratively refine which observables and binnings are most constraining, feeding information back to the stored data.
The paper frames itself as the opening of a community dialogue. But the concrete artifacts it proposes (a file schema, software tools, HEPData integration) are what transform a dialogue into a standard.
Bottom Line: By proposing a concrete standard for publishing unbinned particle physics measurements, this paper lays the groundwork for a new generation of physics analyses, ones that preserve full information, enable post-hoc observable definition, and remain usable for decades after the original data were collected.
IAIFI Research Highlights
This work applies machine learning to one of experimental physics' most basic challenges, data representation, connecting ML-based unfolding algorithms with traditional physics analysis workflows.
The paper shows how density estimation and classifier-based neural networks can replace handcrafted histograms as the primary output of physics measurements, pushing ML from analysis tool to archival infrastructure.
Unbinned measurements preserve full phase-space information from particle collisions, enabling more powerful extractions of Standard Model parameters, parton distribution functions, and searches for physics beyond the Standard Model.
The authors frame this as the opening of a community dialogue rather than a final answer, with integration into HEPData and shared software tools as near-term goals; the work is available at [arXiv:2109.13243](https://arxiv.org/abs/2109.13243).
Original Paper Details
Presenting Unbinned Differential Cross Section Results
[2109.13243](https://arxiv.org/abs/2109.13243)
["Miguel Arratia", "Anja Butter", "Mario Campanelli", "Vincent Croft", "Aishik Ghosh", "Dag Gillberg", "Kristin Lohwasser", "Bogdan Malaescu", "Vinicius Mikuni", "Benjamin Nachman", "Juan Rojo", "Jesse Thaler", "Ramon Winterhalder"]
Machine learning tools have empowered a qualitatively new way to perform differential cross section measurements whereby the data are unbinned, possibly in many dimensions. Unbinned measurements can enable, improve, or at least simplify comparisons between experiments and with theoretical predictions. Furthermore, many-dimensional measurements can be used to define observables after the measurement instead of before. There is currently no community standard for publishing unbinned data. While there are also essentially no measurements of this type public, unbinned measurements are expected in the near future given recent methodological advances. The purpose of this paper is to propose a scheme for presenting and using unbinned results, which can hopefully form the basis for a community standard to allow for integration into analysis workflows. This is foreseen to be the start of an evolving community dialogue, in order to accommodate future developments in this field that is rapidly evolving.