
Pruning a restricted Boltzmann machine for quantum state reconstruction
Authors
Anna Golubeva, Roger G. Melko
Abstract
Restricted Boltzmann machines (RBMs) have proven to be a powerful tool for learning quantum wavefunction representations from qubit projective measurement data. Since the number of classical parameters needed to encode a quantum wavefunction scales rapidly with the number of qubits, the ability to learn efficient representations is of critical importance. In this paper we study magnitude-based pruning as a way to compress the wavefunction representation in an RBM, focusing on RBMs trained on data from the transverse-field Ising model in one dimension. We find that pruning can reduce the total number of RBM weights, but the threshold at which the reconstruction accuracy starts to degrade varies significantly depending on the phase of the model. In a gapped region of the phase diagram, the RBM admits pruning over half of the weights while still accurately reproducing relevant physical observables. At the quantum critical point however, even a small amount of pruning can lead to significant loss of accuracy in the physical properties of the reconstructed quantum state. Our results highlight the importance of tracking all relevant observables as their sensitivity varies strongly with pruning. Finally, we find that sparse RBMs are trainable and discuss how a successful sparsity pattern can be created without pruning.
Concepts
The Big Picture
Imagine you’ve taken thousands of photographs of a quantum system, snapshots of qubits (the quantum version of computer bits, each capable of existing in multiple states at once) flickering between states, and you want to reconstruct the underlying wavefunction from that data alone. A wavefunction is a complete mathematical portrait of a quantum system: it encodes every probability, every correlation, every possible measurement outcome. The catch is that this description grows exponentially with the number of particles. For even 50 qubits, writing down the exact wavefunction would require more numbers than atoms in the observable universe.
Machine learning offers a lifeline, but only if it can learn efficient representations, compressed summaries that capture what matters without drowning in parameters.
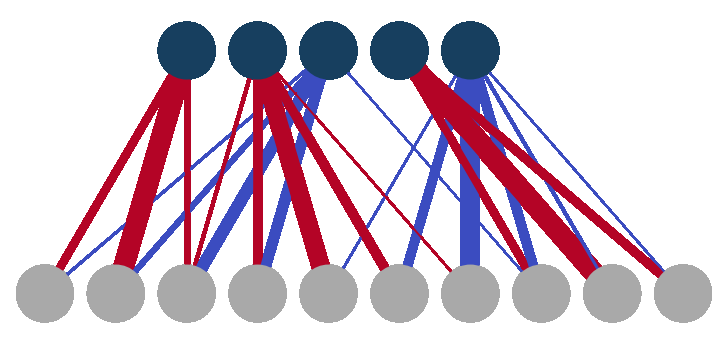
Restricted Boltzmann machines (RBMs) are among the most promising tools for this job. Think of them as compact neural networks with two layers: one that “sees” the raw measurement data and one that learns hidden patterns underneath, connected by a web of tunable weights. The more qubits you study, the bigger the RBM needs to be. But does every connection in that web actually matter? If you could snip away the weakest links without losing accuracy, you’d have a faster, leaner machine that scales better to larger quantum systems.
Physicists Anna Golubeva and Roger Melko put this question to the test. Whether pruning works, it turns out, depends on where you sit in the quantum phase diagram, a map of how a quantum system behaves as you vary physical conditions like magnetic field strength. Get the phase wrong, and the consequences are severe.
Key Insight: Pruning an RBM works well in ordinary quantum phases, where you can eliminate more than half the weights without losing accuracy. But at a quantum critical point, even minor pruning destroys the fidelity of the reconstructed wavefunction.
How It Works
The researchers trained RBMs on data from the one-dimensional transverse-field Ising model (TFIM), one of the most studied models in quantum physics. It describes a chain of interacting qubits subject to a tunable magnetic field, with two distinct phases: a ferromagnetic phase, where quantum spins align like compass needles pulled by a magnet, and a paramagnetic phase, where quantum randomness prevents any stable alignment. Between them lies a quantum critical point, a dramatic transition driven purely by quantum mechanics.
The team used DMRG (Density Matrix Renormalization Group), a standard computational method for finding the lowest-energy state of a quantum system, to generate realistic measurement samples. They trained RBMs using the QuCumber software package. After training, they applied iterative magnitude-based pruning: find the weight with the smallest absolute value, zero it out, let the remaining weights readjust, repeat. It’s the same strategy that has proven powerful for compressing deep learning models onto smartphones and edge devices.
How much pruning can an RBM tolerate before reconstruction falls apart? The researchers tracked four observables:
- KL divergence: how well the learned distribution matches the true one
- Fidelity: the overlap between the RBM wavefunction and the true ground state
- Energy: the system’s average energy, computed from the Hamiltonian (the mathematical rulebook defining how the system evolves)
- Two-point correlation function: how spins are correlated across the chain
In the ferromagnetic phase, pruning more than half the weights left all four observables essentially intact. The RBM had learned a redundant representation; the extra connections were genuinely superfluous.
At the quantum critical point, the story is different. Quantum correlations become long-ranged here, stretching across the entire system with no preferred scale. Capturing this behavior requires full connectivity. Even removing a small fraction of weights caused measurable degradation in the reconstructed state’s physical properties.
Different observables also failed at different pruning thresholds. The energy might look fine while correlation functions had already degraded significantly. This is a real trap: a single metric can give false confidence. Tracking the full set of relevant physical observables matters, not just training loss.
The team also tested a provocative alternative. Instead of training a large RBM and pruning it down, why not start sparse and train directly? It works, but only if the sparsity pattern is chosen carefully. A random sparse network fails. A pattern informed by the known locality of interactions in the TFIM succeeds. This skips the expensive detour of building a full model first.
Why It Matters
Compressing RBM representations directly determines how large a quantum system we can feasibly study. If a particular physical phase admits highly sparse representations, computational resources can be allocated strategically, spent only where quantum complexity actually lives.
Quantum physics also provides something rare for the pruning question: a test bed where “correct” has a rigorous definition. The known Hamiltonian specifies the exact ground state, so reconstruction accuracy is measurable with mathematical precision. That makes quantum state reconstruction a uniquely informative setting for understanding when and why pruning works.
The discovery that pruning sensitivity tracks quantum phase structure points to a connection between the physical complexity of a quantum state and the information-theoretic structure of the network representing it. Future work might explore whether pruning criteria based on physical symmetries, or on quantum entanglement (the web of correlations linking distant qubits that has no classical equivalent), could extend sparse RBMs into the critical regime.
Bottom Line: Pruning half an RBM’s weights is safe in ordinary quantum phases, but quantum critical points demand full connectivity. This has direct implications for scaling up quantum state reconstruction and for the fundamental theory of neural network compression.
IAIFI Research Highlights
This work connects classical machine learning compression to the physical structure of quantum phases, showing that neural network compressibility mirrors the entanglement complexity of the underlying quantum state.
Standard pruning metrics can be misleading for generative models: different physical observables fail at different sparsity thresholds. This motivates more physically-informed pruning criteria for quantum ML.
By mapping how RBM pruning sensitivity varies across the quantum phase diagram of the transverse-field Ising model, the work exposes a concrete signature of quantum criticality in neural network structure.
Future directions include developing sparsity patterns informed by physical symmetries and extending these results to two-dimensional systems and experimental quantum devices; the full paper is available at [arXiv:2110.03676](https://arxiv.org/abs/2110.03676).