
QuanTA: Efficient High-Rank Fine-Tuning of LLMs with Quantum-Informed Tensor Adaptation
Authors
Zhuo Chen, Rumen Dangovski, Charlotte Loh, Owen Dugan, Di Luo, Marin Soljačić
Abstract
We propose Quantum-informed Tensor Adaptation (QuanTA), a novel, easy-to-implement, fine-tuning method with no inference overhead for large-scale pre-trained language models. By leveraging quantum-inspired methods derived from quantum circuit structures, QuanTA enables efficient high-rank fine-tuning, surpassing the limitations of Low-Rank Adaptation (LoRA)--low-rank approximation may fail for complicated downstream tasks. Our approach is theoretically supported by the universality theorem and the rank representation theorem to achieve efficient high-rank adaptations. Experiments demonstrate that QuanTA significantly enhances commonsense reasoning, arithmetic reasoning, and scalability compared to traditional methods. Furthermore, QuanTA shows superior performance with fewer trainable parameters compared to other approaches and can be designed to integrate with existing fine-tuning algorithms for further improvement, providing a scalable and efficient solution for fine-tuning large language models and advancing state-of-the-art in natural language processing.
Concepts
The Big Picture
Imagine you’re trying to teach a brilliant but rigid expert a new skill. You could retrain them from scratch: expensive, slow, wasteful. Or give them a narrow cheat sheet: cheap, but maybe too limited for the task. The challenge in modern AI is exactly this. How do you adapt a massive, already-trained language model to new jobs without the enormous cost of retraining from scratch?
The dominant solution has been Low-Rank Adaptation (LoRA), which works by injecting small, precisely constrained tweaks into a model’s weight matrices. Instead of modifying millions of parameters directly, LoRA represents each update as a product of two much smaller matrices, dramatically cutting costs. The hidden assumption: that the necessary changes are low-complexity adjustments. For many real-world tasks, especially complex reasoning, that assumption breaks down.
Researchers at MIT and IAIFI built a better mousetrap. Their method, QuanTA (Quantum-informed Tensor Adaptation), borrows structural ideas from quantum computing to achieve richer, more expressive fine-tuning at a fraction of the usual cost. No quantum hardware required.
Key Insight: QuanTA uses the mathematical architecture of quantum circuits to represent rich, high-rank weight updates efficiently, breaking past LoRA’s expressiveness ceiling on complex tasks.
How It Works
To understand QuanTA, you first need to understand why LoRA hits a wall. When LoRA updates a model’s weight matrices, the update has rank at most r, a measure of how much independent information the change can encode. Think of rank as the richness of the update: low rank means the model can only learn simple transformations, while high rank allows far more nuanced adjustments. Keep r small to hold down parameter count and costs stay low, but so does what the model can actually learn.
The researchers show this limit concretely: on the DROP arithmetic reasoning benchmark, LoRA’s performance plateaus while full fine-tuning keeps improving. The low-rank assumption simply isn’t valid for hard tasks.
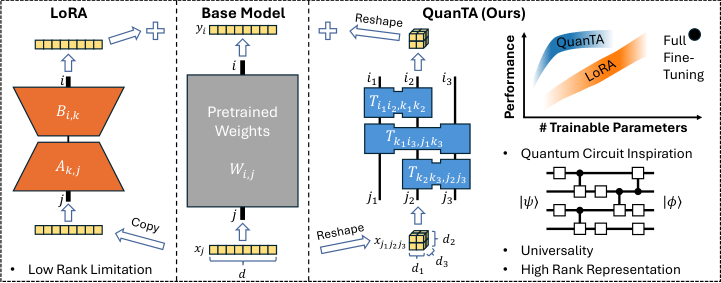
The quantum insight works like this. In quantum computing, a circuit processes information through a sequence of gate operations: simple, local steps that each touch only a small part of the system (a few qubits, the quantum equivalents of classical bits). Each gate is simple on its own, but a sequence of them can carry out any transformation on the entire system. These full-system transformations are inherently full-rank and can capture arbitrarily complex patterns. QuanTA imports this mathematical structure directly into neural network weights.
Here’s how the method works in practice:
- Reshape the weight matrix into a higher-dimensional tensor (a multi-dimensional array), unfolding a flat grid into a structure where each axis corresponds to a group of features.
- Apply a sequence of local tensor operations, each acting on only a small subset of axes at a time, analogous to quantum gates acting on a few qubits.
- The composition of these local operations can represent any matrix, including full-rank ones. This is guaranteed by the paper’s universality theorem, which formally proves QuanTA can parameterize arbitrary weight updates.
- Merge the result back into the base model weights at inference time, adding zero overhead during deployment.
The key theoretical result is the rank representation theorem. It quantifies exactly how much rank QuanTA can achieve as a function of the number of tensor operations used. With just a logarithmic number of operations (step count grows very slowly, far more slowly than problem size), QuanTA can hit full rank. LoRA cannot do this without a proportional explosion in trainable parameters.
Why It Matters
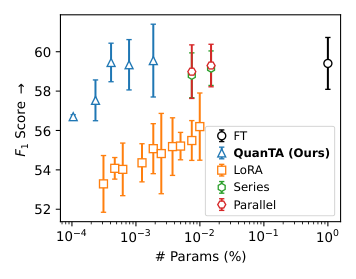
The practical payoff is real. On commonsense reasoning benchmarks, QuanTA matches or exceeds LoRA and its variants while using fewer trainable parameters. On arithmetic reasoning, the harder class of tasks where the low-rank assumption visibly fails, it pulls ahead more decisively.
The method integrates cleanly with existing fine-tuning pipelines. Stack QuanTA on top of LoRA, QLoRA, or other PEFT (Parameter-Efficient Fine-Tuning) techniques and you get further gains, since it addresses a complementary bottleneck.
The deeper point is conceptual. Quantum mechanical structures have genuine mathematical value in classical computing. Quantum circuits were developed to exploit entanglement and superposition, but the underlying tensor algebra turns out to be just as useful for parameterizing complex transformations in neural networks. As language models grow toward hundreds of billions of parameters, methods with theoretical guarantees will matter more than empirical tricks.
Bottom Line: QuanTA achieves high-rank LLM fine-tuning by importing the mathematical structure of quantum circuits, delivering better reasoning performance with fewer parameters and no inference overhead.
IAIFI Research Highlights
This work imports quantum circuit mathematics into machine learning optimization. The tensor algebra of quantum gates turns out to be a provably better way to parameterize high-rank weight updates in classical neural networks.
QuanTA moves parameter-efficient fine-tuning past the low-rank bottleneck that limits LoRA on complex reasoning tasks, backed by formal universality and rank representation theorems rather than heuristic design.
The work validates a core IAIFI thesis: structures from fundamental physics offer transferable mathematical tools. Quantum circuit architecture yields practical gains in a leading AI application.
Future work may explore QuanTA for vision-language and multimodal models, as well as combinations with quantization-aware training. The full paper appeared at NeurIPS 2024 ([arXiv:2406.00132](https://arxiv.org/abs/2406.00132)).
Original Paper Details
QuanTA: Efficient High-Rank Fine-Tuning of LLMs with Quantum-Informed Tensor Adaptation
2406.00132
["Zhuo Chen", "Rumen Dangovski", "Charlotte Loh", "Owen Dugan", "Di Luo", "Marin Soljačić"]
We propose Quantum-informed Tensor Adaptation (QuanTA), a novel, easy-to-implement, fine-tuning method with no inference overhead for large-scale pre-trained language models. By leveraging quantum-inspired methods derived from quantum circuit structures, QuanTA enables efficient high-rank fine-tuning, surpassing the limitations of Low-Rank Adaptation (LoRA)--low-rank approximation may fail for complicated downstream tasks. Our approach is theoretically supported by the universality theorem and the rank representation theorem to achieve efficient high-rank adaptations. Experiments demonstrate that QuanTA significantly enhances commonsense reasoning, arithmetic reasoning, and scalability compared to traditional methods. Furthermore, QuanTA shows superior performance with fewer trainable parameters compared to other approaches and can be designed to integrate with existing fine-tuning algorithms for further improvement, providing a scalable and efficient solution for fine-tuning large language models and advancing state-of-the-art in natural language processing.