
Reducing Simulation Dependence in Neutrino Telescopes with Masked Point Transformers
Authors
Felix J. Yu, Nicholas Kamp, Carlos A. Argüelles
Abstract
Machine learning techniques in neutrino physics have traditionally relied on simulated data, which provides access to ground-truth labels. However, the accuracy of these simulations and the discrepancies between simulated and real data remain significant concerns, particularly for large-scale neutrino telescopes that operate in complex natural media. In recent years, self-supervised learning has emerged as a powerful paradigm for reducing dependence on labeled datasets. Here, we present the first self-supervised training pipeline for neutrino telescopes, leveraging point cloud transformers and masked autoencoders. By shifting the majority of training to real data, this approach minimizes reliance on simulations, thereby mitigating associated systematic uncertainties. This represents a fundamental departure from previous machine learning applications in neutrino telescopes, paving the way for substantial improvements in event reconstruction and classification.
Concepts
The Big Picture
Imagine teaching a detective to recognize crime scenes using only staged photographs. The fake blood looks different from real blood, the lighting is too controlled, and the props don’t behave like actual evidence. When that detective arrives at a real crime scene, the mismatches cause confusion. That’s the problem facing physicists at IceCube, one of the world’s largest neutrino detectors, buried a mile beneath the Antarctic ice.
Neutrino telescopes are extraordinary machines: arrays of thousands of light sensors, deep in glacial ice or seawater, that catch faint flashes produced when neutrinos occasionally collide with ice molecules and produce charged particles. (Neutrinos are particles that barely interact with matter, which is what makes detecting them so difficult.) The trouble is that these detectors operate in messy, complex natural environments. The ice has bubbles, the water has currents, and the sensors degrade over time.
For decades, physicists have trained their machine learning models almost entirely on simulated data, using painstakingly detailed computer models that trace every photon through the ice. When those simulations don’t perfectly match reality, the models break.
A team of Harvard physicists has now developed the first self-supervised learning pipeline for neutrino telescopes, a method that learns from raw, unlabeled real detector data rather than requiring carefully labeled examples. The approach shifts how these instruments can be trained, sharply reducing how much they need to trust their simulations.
Key Insight: Training primarily on real, unlabeled detector data instead of simulations sidesteps the accuracy gap between simulated and observed physics, making neutrino event reconstruction far more resistant to unknown detector effects.
How It Works
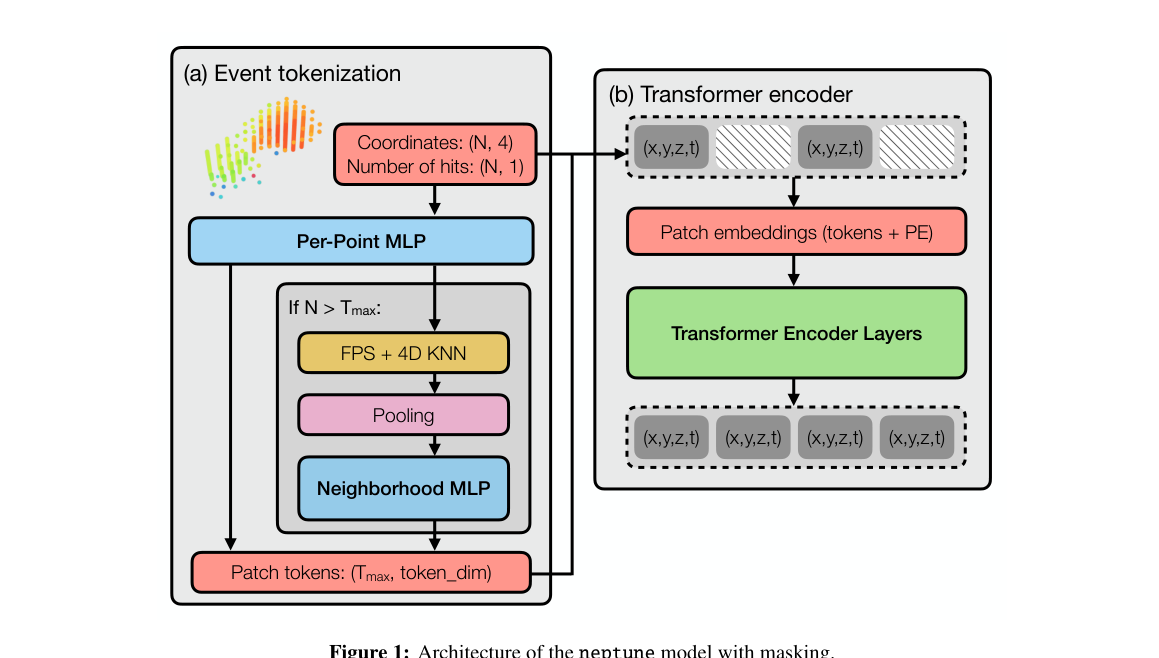
The team built NEPTUNE (Neutrino Efficient Point Transformer for Ultrarelativistic Neutrino Events). It treats a neutrino event not as an image or a time series, but as a point cloud: a collection of light sensors that fired, each tagged with its 3D position and detection time. This is a natural fit for a sparse 3D detector where only a fraction of sensors register a signal in any given event.
NEPTUNE has three main components:
-
Event Tokenizer: Raw sensor hits are grouped into 3-nanosecond time windows and processed through a small neural network that identifies local patterns. If a high-energy event lights up too many sensors, the tokenizer uses farthest point sampling to select up to 512 representative points, choosing the most spread-out subset to preserve spatial coverage. Each selected point also draws on its 32 nearest neighboring sensors for additional context.
-
Transformer Encoder: The resulting tokens feed into a standard transformer architecture (the same fundamental design behind large language models), enriched with each sensor’s spatial position and first-hit time.
-
Prediction Head: A final task-specific layer handles the actual physics question, whether that’s reconstructing a neutrino’s direction or classifying its interaction type.
The real novelty is in the pre-training. The team borrowed from masked autoencoders, a technique from computer vision where a model learns by having portions of its input randomly hidden, then tries to reconstruct what’s missing. NEPTUNE’s version conceals between 75% and 100% of sensor positions and timestamps during pre-training, forcing the model to fill them back in. No labels needed. The model picks up the internal structure of neutrino events purely from real detector data.

After pre-training on unlabeled real data, the model is fine-tuned with a small amount of labeled simulation. The team used block expansion, inserting new processing layers (initialized to simply pass information through unchanged) on top of the frozen pre-trained layers. These fresh layers learn the downstream task without overwriting what the model already knows about actual detector signals.
Why It Matters
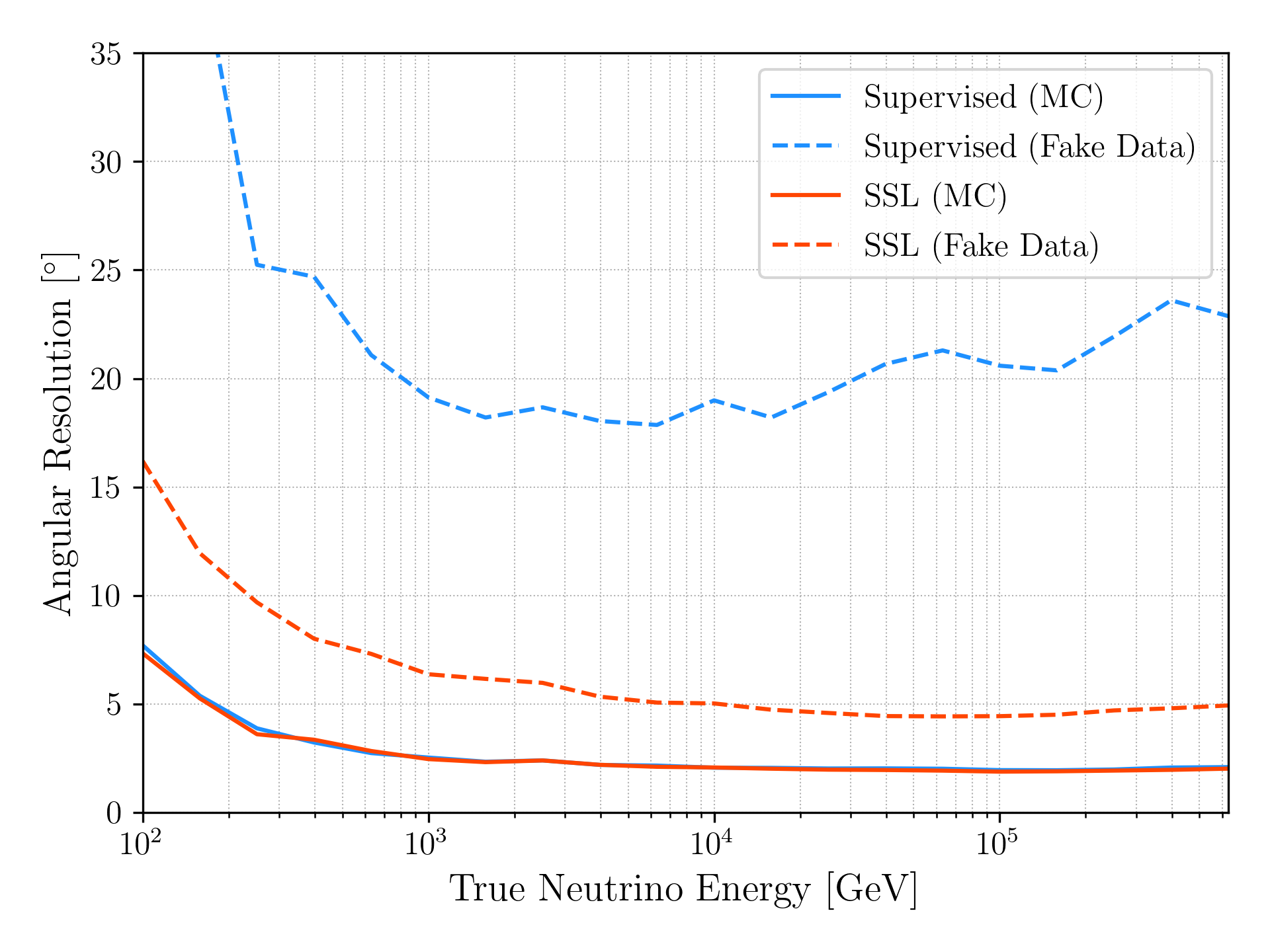
To test whether this actually helps, the team designed a controlled experiment. They took two simulated datasets, treated one as “real” data and the other as labeled simulation, then deliberately broke them apart by injecting random spurious signals into one at a controlled rate. This mimics a realistic scenario: a detector effect present in the data but entirely absent from the simulation.
The results were clear. Conventionally supervised models, trained entirely on simulation, held up when noise rates were slightly wrong but consistent across both datasets. When the noise effect was completely absent from the simulation, performance degraded sharply. NEPTUNE, pre-trained on the “real” data, maintained strong performance in both cases.
This has implications well beyond IceCube. Neutrino physics is entering a new era, with next-generation telescopes like IceCube-Gen2, KM3NeT, and Baikal-GVD coming online or under development. These instruments will collect vastly more data and face equally complex, imperfectly understood detector environments. The simulation-dependence problem only gets worse at scale.
The broader point is that self-supervised learning can serve not as a replacement for physics simulation, but as a way to ground models in the messy reality of actual detector data. The same idea could apply wherever simulation-to-reality gaps create systematic biases, from particle colliders to gravitational wave detectors.
Bottom Line: Training on real, unlabeled detector data can sharply reduce vulnerability to unmodeled detector effects. That becomes increasingly valuable as next-generation experiments push their sensitivity limits.
IAIFI Research Highlights
This work connects transformer-based AI architectures from computer vision with the experimental challenges of large-scale neutrino physics, showing that self-supervised pre-training strategies carry over powerfully into fundamental particle detection.
The paper introduces the first masked autoencoder pre-training pipeline tailored to 3D point cloud data from particle physics detectors, showing that high masking ratios (75–100%) force models to learn physically meaningful representations without any supervision.
By reducing systematic uncertainties from simulation mismodeling, this approach could sharpen neutrino direction reconstruction and flavor classification at IceCube and future gigaton-scale observatories, improving measurements of high-energy astrophysical neutrino sources.
The NEPTUNE codebase is publicly available on GitHub; future work will apply this pipeline at full IceCube scale. See [arXiv:2510.01733](https://arxiv.org/abs/2510.01733) for the full paper.