
Robust and Provably Monotonic Networks
Authors
Ouail Kitouni, Niklas Nolte, Mike Williams
Abstract
The Lipschitz constant of the map between the input and output space represented by a neural network is a natural metric for assessing the robustness of the model. We present a new method to constrain the Lipschitz constant of dense deep learning models that can also be generalized to other architectures. The method relies on a simple weight normalization scheme during training that ensures the Lipschitz constant of every layer is below an upper limit specified by the analyst. A simple monotonic residual connection can then be used to make the model monotonic in any subset of its inputs, which is useful in scenarios where domain knowledge dictates such dependence. Examples can be found in algorithmic fairness requirements or, as presented here, in the classification of the decays of subatomic particles produced at the CERN Large Hadron Collider. Our normalization is minimally constraining and allows the underlying architecture to maintain higher expressiveness compared to other techniques which aim to either control the Lipschitz constant of the model or ensure its monotonicity. We show how the algorithm was used to train a powerful, robust, and interpretable discriminator for heavy-flavor-quark decays, which has been adopted for use as the primary data-selection algorithm in the LHCb real-time data-processing system in the current LHC data-taking period known as Run 3. In addition, our algorithm has also achieved state-of-the-art performance on benchmarks in medicine, finance, and other applications.
Concepts
The Big Picture
Imagine a security guard at an airport who gets suspicious whenever a traveler looks too different from normal, flagging anyone with an unusual gait, unusual luggage, or unusual travel time. You want the guard calibrated: not overreacting to tiny differences, yet still catching what matters.
Deep inside CERN’s Large Hadron Collider, physicists face this problem at scale. The LHC generates over 100 terabytes of data every second. Custom electronics filter that down, but annual data volumes still reach hundreds of exabytes. Every microsecond, a real-time algorithm must decide: keep this proton collision event, or throw it away forever. Get it wrong, and years of physics discovery go in the bin.
The algorithm needs to catch rare, exotic particle decays while staying insensitive to detector glitches and imperfect simulations.
Researchers at MIT’s IAIFI have built exactly that: a neural network architecture called Monotonic Lipschitz Networks that is more expressive, more robust, and more interpretable than previous approaches. It is now running live at LHCb during Run 3.
Key Insight: By constraining how much a neural network’s output can swing in response to small input changes, and enforcing that certain outputs only increase as key inputs increase, the team built a classifier that is robust by design and monotonic by proof, not just by hope.
How It Works
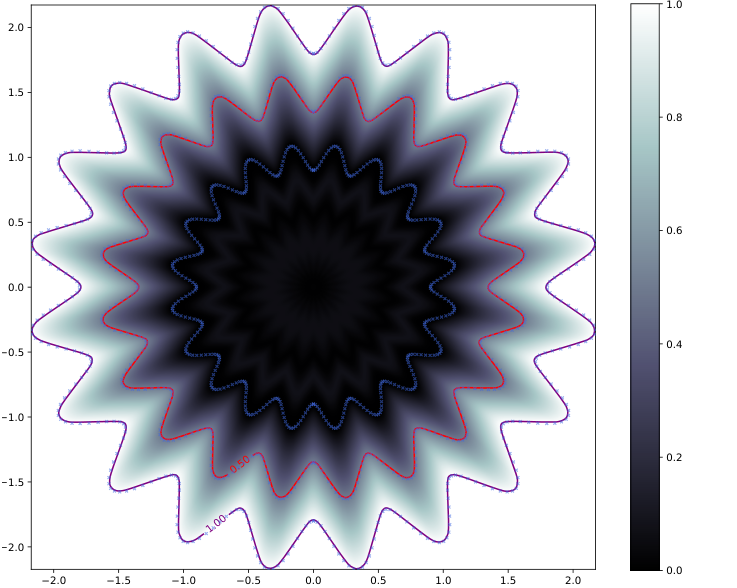
The technical core rests on a concept called the Lipschitz constant, a number that bounds how “jumpy” a function is. A smaller Lipschitz constant means a smoother, more stable function. For neural networks, this translates directly to robustness: a network with a bounded Lipschitz constant won’t wildly flip its output because a detector drifted by 0.1% overnight.
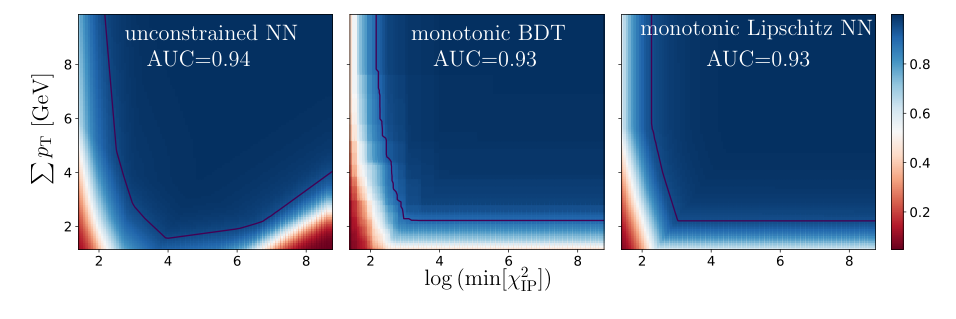
Previous methods to control the Lipschitz constant existed, but they came with a tradeoff. Constraining the network too tightly crushed its ability to learn complex patterns. The MIT team’s solution was column-wise weight normalization. Instead of rescaling an entire weight matrix by its largest singular value (the standard spectral normalization approach, which can be very conservative), they normalize each column independently, keeping the absolute sum of each column’s entries within a target bound. The network retains far more expressiveness because the constraint acts locally rather than globally.
For a layer with weight matrix W, the procedure is:
- Compute the column-wise 1-norms (the sum of absolute values of each column’s entries)
- Divide each column by its norm only if that norm exceeds the allowed limit
- Leave columns already within budget unchanged
The result is a network g(x) whose Lipschitz constant is provably bounded by a value λ chosen by the analyst: total variation in output is bounded by the weighted sum of input variations.
Monotonicity is then achieved through a structural trick. Physics tells us that certain variables should always push the classifier score higher as they increase. A particle track displaced further from the collision vertex (the point where two protons collided) is more likely to signal an interesting heavy-flavor decay, not less. To bake this in, the team adds a monotonic residual connection: a linear term λ·xᵢ for each input that should be monotonic.
Because the base network g(x) has a Lipschitz constant of at most λ, its gradient in any direction is bounded by λ in magnitude. Adding a linear term with slope exactly λ guarantees the combined output always increases with that input: the partial derivative ∂f/∂xᵢ is always non-negative. Monotonicity is enforced structurally. It cannot be violated even if training data is noisy or the model overfits.
Why It Matters
LHCb adopted this architecture as the primary data-selection algorithm for its real-time trigger system during Run 3. The classifier targets B mesons and D mesons, short-lived particles containing heavy quarks whose decay patterns are key windows into CP violation (a subtle matter-antimatter asymmetry that may explain why the universe contains matter at all) and physics beyond the Standard Model.
Encoding the physical prior that “more displaced track = more interesting” directly into the network avoids a specific failure mode. If a miscalibrated detector begins artificially inflating one variable, a conventional classifier might suddenly select the wrong events. A monotonic classifier cannot be fooled this way.
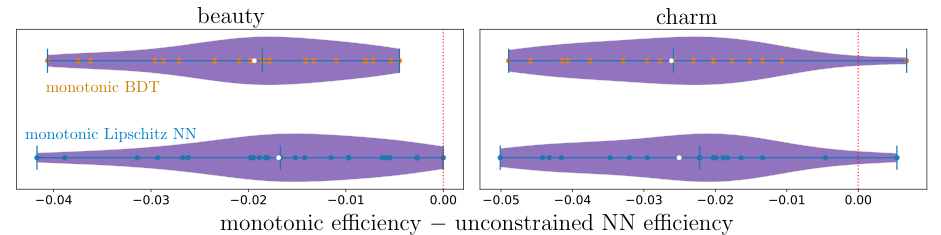
The same principles extend well beyond particle physics. The team demonstrated state-of-the-art results on benchmarks in medicine, where monotonic relationships between biomarkers and risk scores are often clinically required, and in finance, where regulatory fairness demands that certain inputs only push scores in one direction. Algorithmic fairness (the requirement that raising an applicant’s income can never hurt their loan approval odds) is directly expressible as a monotonicity constraint.
The broader point: inductive biases drawn from domain expertise can be encoded as hard architectural constraints without crippling model capacity. That’s a design philosophy with real implications for any field where neural networks are replacing rule-based systems.
Bottom Line: Monotonic Lipschitz Networks give physicists, and anyone else, a neural network that is robust by proof, monotonic by construction, and more expressive than the previous state of the art. That combination was convincing enough for CERN to trust it with irreversible real-time decisions at the world’s most complex physics experiment.
IAIFI Research Highlights
This work directly encodes particle physics domain knowledge (the "more displaced = more interesting" principle for exotic decays) as a mathematical guarantee in a neural network, showing how physics intuition can sharpen AI design rather than merely being approximated by it.
The column-wise weight normalization scheme achieves tighter Lipschitz control with less loss of expressiveness than standard spectral normalization, advancing the theory of constrained neural architectures with broad applications in robustness, fairness, and certified machine learning.
The resulting classifier was adopted as LHCb's primary real-time trigger algorithm for Run 3, directly determining which proton collision events are preserved for analysis, making it one of the highest-stakes machine learning deployments in experimental particle physics to date.
Future work may extend the column-wise normalization scheme to convolutional and graph neural network architectures, broadening its applicability across modern deep learning; the full method is described in [arXiv:2112.00038](https://arxiv.org/abs/2112.00038).