
Scaling Laws For Scalable Oversight
Authors
Joshua Engels, David D. Baek, Subhash Kantamneni, Max Tegmark
Abstract
Scalable oversight, the process by which weaker AI systems supervise stronger ones, has been proposed as a key strategy to control future superintelligent systems. However, it is still unclear how scalable oversight itself scales. To address this gap, we propose a framework that quantifies the probability of successful oversight as a function of the capabilities of the overseer and the system being overseen. Specifically, our framework models oversight as a game between capability-mismatched players; the players have oversight-specific Elo scores that are a piecewise-linear function of their general intelligence, with two plateaus corresponding to task incompetence and task saturation. We validate our framework with a modified version of the game Nim and then apply it to four oversight games: Mafia, Debate, Backdoor Code and Wargames. For each game, we find scaling laws that approximate how domain performance depends on general AI system capability. We then build on our findings in a theoretical study of Nested Scalable Oversight (NSO), a process in which trusted models oversee untrusted stronger models, which then become the trusted models in the next step. We identify conditions under which NSO succeeds and derive numerically (and in some cases analytically) the optimal number of oversight levels to maximize the probability of oversight success. We also apply our theory to our four oversight games, where we find that NSO success rates at a general Elo gap of 400 are 13.5% for Mafia, 51.7% for Debate, 10.0% for Backdoor Code, and 9.4% for Wargames; these rates decline further when overseeing stronger systems.
Concepts
The Big Picture
Imagine you’re a detective trying to catch a master thief. You’re good at your job — but the thief is smarter, faster, and better at covering their tracks. Now imagine the “thief” is a future superintelligent AI, and you — the detective — are an AI yourself, just a weaker one. Can a less capable system reliably catch the schemes of a more powerful one?
And if we chain these oversight steps together — using AI to watch AI to watch AI — does safety compound, or does it collapse?
This is the central puzzle of scalable oversight, one of the most debated strategies in AI safety. The core idea: gradually build control over powerful AI by having moderately capable systems supervise them, then using those supervised systems to check even stronger ones. It sounds elegant. But until now, nobody had put hard numbers on whether it actually works.
Researchers at MIT have built the first mathematical framework for scalable oversight — using chess-style skill ratings, game theory, and four carefully designed games where AIs try to outsmart each other — and their results are simultaneously promising and sobering.
Key Insight: Scalable oversight can work, but only under specific conditions — and the numbers show that most real-world oversight games fall far short of the safety margins we’d want before trusting these methods with superintelligent systems.
How It Works
The MIT team reframes oversight as a two-player game. On one side sits the Houdini — an AI trying to escape detection, hide malicious code, or manipulate the outcome. On the other sits the Guard — a weaker AI trying to catch it. The question: under what conditions does the Guard win, and how does that probability change as the capability gap grows?
To measure capability, they borrow Elo scores from competitive chess — a number capturing relative skill, where a 400-point gap means the stronger player wins roughly 91% of the time. Each model gets two scores: one as Guard, one as Houdini.
Those scores don’t track general AI capability in a straight line. The researchers propose the Double ReLU model (named after a mathematical function that produces a bent-line shape) with three distinct phases: flat at the bottom when a model is too weak to even engage, rising through a “payoff region” where more intelligence genuinely helps, then flat again once the task is fully solved. They validate this on a modified version of the game Nim and find that large language model (LLM) performance follows exactly this three-phase shape.
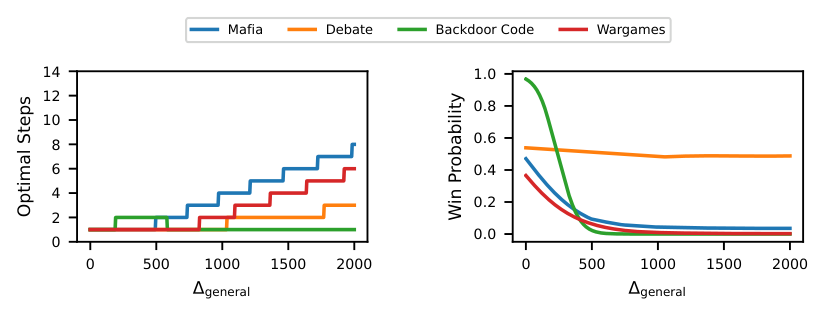
They then apply the framework to four oversight challenges:
- Mafia: A social deduction game where the Houdini is the hidden traitor and the Guard must identify them through conversation.
- Debate: One AI argues for a false claim; another tries to expose the deception to a judge.
- Backdoor Code: The Houdini hides malicious functionality in code; the Guard must audit and detect it.
- Wargames: A geopolitical simulation where the Houdini pursues dangerous military escalation while the Guard tries to intervene.
Across all four, they measure pairwise win rates between many LLMs, fit Double ReLU curves to the data, and extract the mathematical rules describing how performance changes with capability.
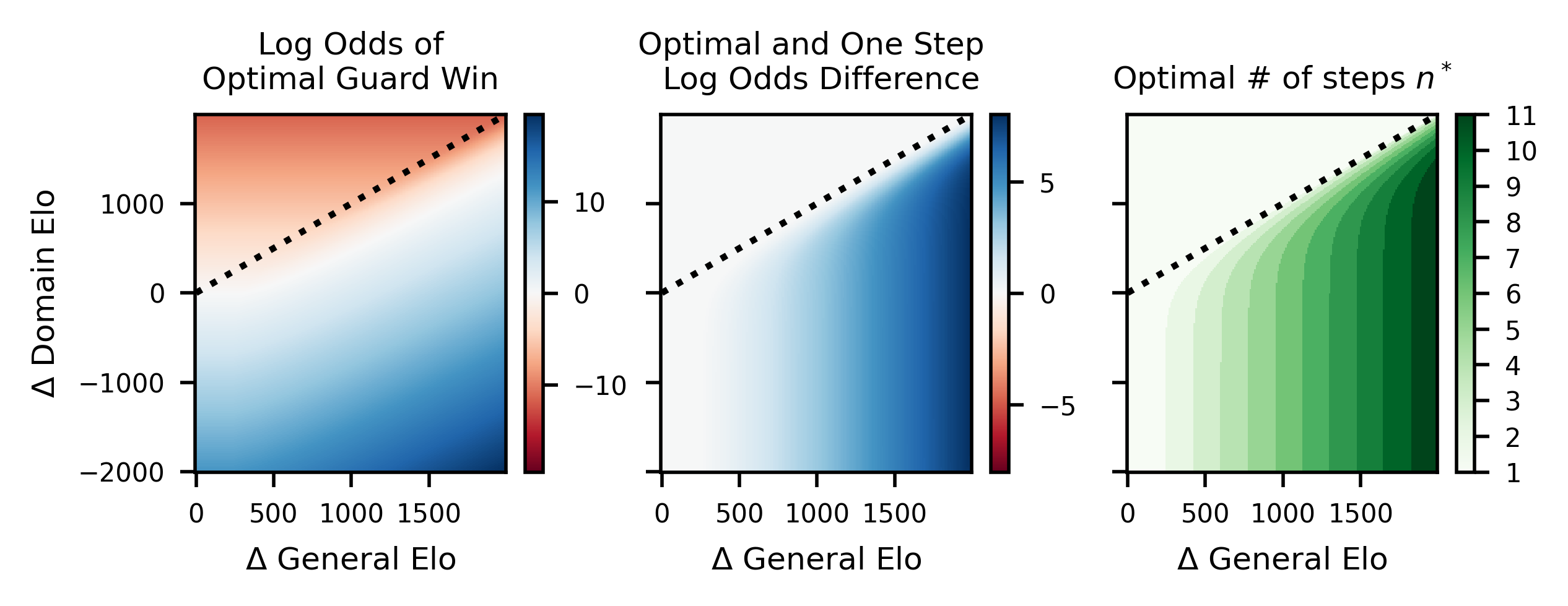
The paper’s deepest contribution is a theoretical analysis of Nested Scalable Oversight (NSO) — chaining oversight steps so that trusted models watch untrusted stronger ones, which then become the watchers in the next round. Does this self-reinforcing chain compound safety?
The answer depends on three things: the capability gap between adjacent levels, the Double ReLU slope (how much domain skill you gain per unit of general intelligence), and the number of steps in the chain. The researchers derive the optimal number of oversight levels that maximizes total success probability. Too few levels and a weak Guard faces a powerful Houdini; too many and errors compound, each step’s failure probability multiplying.
Applying NSO theory to the four games — assuming a 400 Elo gap between the weakest and strongest AI in the chain — yields:
- Mafia: 13.5% success rate
- Debate: 51.7% success rate
- Backdoor Code: 10.0% success rate
- Wargames: 9.4% success rate
Debate looks workable. The other three do not.
Why It Matters
Scalable oversight isn’t a free lunch. It works when oversight tasks have the right mathematical structure: a steep slope in the payoff region where increased capability genuinely helps, moderate performance ceilings, and enough middle ground for intermediate-capability models to contribute. Debate-style oversight has this structure. Code auditing and social deduction are much harder to make safe through oversight alone.
This has direct implications for AI governance. Safety standards in aviation require fatality rates below 10⁻⁵ per flight hour; nuclear plants must stay below 10⁻⁴ core damage events per year. The 10% success rates measured here are nowhere near those thresholds.
The paper doesn’t claim these numbers are final — they depend on which LLMs are tested and which games are played. But it establishes the framework needed to actually compute safety margins for AI oversight systems, a genuine advance. Future work might extend this to more realistic tasks, probe how prompting strategies shift the Double ReLU parameters, or explore whether adversarial training can improve Guard performance where it currently lags.
Bottom Line: This is the first paper to put real numbers on whether scalable oversight can keep pace with increasingly powerful AI — and the answer is “sometimes, but not reliably enough, yet.” Debate-style oversight reaches 51.7% success; code auditing falls to 10%. These benchmarks give the field a concrete target to beat.
IAIFI Research Highlights
This work imports quantitative risk-assessment methodology from nuclear safety and aviation into AI alignment, applying Elo-based game theory to derive formal scaling laws for oversight — a bridge between statistical physics, information theory, and machine learning.
The Double ReLU model and Nested Scalable Oversight framework provide the first quantitative foundation for reasoning about weak-to-strong supervision chains, giving AI safety researchers concrete parameters to measure and optimize.
By treating AI capability as a continuous variable with phase-transition-like behavior (incompetence → payoff → saturation), the work draws a direct analogy to renormalization group flows and scaling phenomena from condensed matter and particle physics.
The framework can be extended to new oversight games and larger model families; the authors call for developing tasks where NSO success rates reliably exceed safety-critical thresholds. Find the full paper at [arXiv:2504.18530](https://arxiv.org/abs/2504.18530) (NeurIPS 2025 proceedings).