
SIDDA: SInkhorn Dynamic Domain Adaptation for Image Classification with Equivariant Neural Networks
Authors
Sneh Pandya, Purvik Patel, Brian D. Nord, Mike Walmsley, Aleksandra Ćiprijanović
Abstract
Modern neural networks (NNs) often do not generalize well in the presence of a "covariate shift"; that is, in situations where the training and test data distributions differ, but the conditional distribution of classification labels remains unchanged. In such cases, NN generalization can be reduced to a problem of learning more domain-invariant features. Domain adaptation (DA) methods include a range of techniques aimed at achieving this; however, these methods have struggled with the need for extensive hyperparameter tuning, which then incurs significant computational costs. In this work, we introduce SIDDA, an out-of-the-box DA training algorithm built upon the Sinkhorn divergence, that can achieve effective domain alignment with minimal hyperparameter tuning and computational overhead. We demonstrate the efficacy of our method on multiple simulated and real datasets of varying complexity, including simple shapes, handwritten digits, and real astronomical observations. SIDDA is compatible with a variety of NN architectures, and it works particularly well in improving classification accuracy and model calibration when paired with equivariant neural networks (ENNs). We find that SIDDA enhances the generalization capabilities of NNs, achieving up to a $\approx40\%$ improvement in classification accuracy on unlabeled target data. We also study the efficacy of DA on ENNs with respect to the varying group orders of the dihedral group $D_N$, and find that the model performance improves as the degree of equivariance increases. Finally, we find that SIDDA enhances model calibration on both source and target data--achieving over an order of magnitude improvement in the ECE and Brier score. SIDDA's versatility, combined with its automated approach to domain alignment, has the potential to advance multi-dataset studies by enabling the development of highly generalizable models.
Concepts
The Big Picture
Imagine training a doctor to diagnose X-rays from one hospital, then discovering that scans from another hospital look slightly different: different scanner models, different contrast, different noise. The expertise doesn’t disappear, but accuracy plummets.
Scale that problem to astronomy: a model trained on simulated galaxy images from IllustrisTNG must classify real galaxies from the Hubble Space Telescope. Simulations are clean and pristine. Real data is blurred, noisy, and shot through with instrumental artifacts. The neural network, excellent in the lab, stumbles in the field.
This is the training-deployment gap, one of the most persistent headaches in applied machine learning. The underlying task hasn’t changed; the labels still mean the same thing. But the statistical character of the data has shifted, and modern neural networks are surprisingly brittle in the face of that shift.
Existing fixes, grouped under domain adaptation, generally work but come with a catch: they demand extensive tuning of dozens of internal settings, burning enormous computational resources and expert time.
A team from Northeastern University, Fermilab, the University of Chicago, and the University of Toronto has built a way out. Their method, SIDDA (SInkhorn Dynamic Domain Adaptation), achieves effective domain alignment with minimal tuning. When paired with symmetry-aware neural networks, it pushes classification accuracy up by as much as 40% on unlabeled real-world data.
Key Insight: SIDDA automatically aligns training and deployment data distributions using the Sinkhorn divergence (a computationally efficient form of optimal transport), requiring almost no hyperparameter tuning while delivering large gains in both accuracy and model calibration.
How It Works
The mathematical heart of SIDDA is optimal transport (OT) theory, originally developed to answer a deceptively simple question: what is the cheapest way to move a pile of dirt from one place to another? In machine learning, the “dirt” is your data’s statistical spread, and the goal is to move it from the training domain to the real-world domain at minimum cost. OT captures not just how different two distributions are, but the geometry of those differences.
Raw OT is expensive. SIDDA uses the Sinkhorn divergence, an efficient approximation that runs orders of magnitude faster while preserving the desirable geometric properties: most of the accuracy of full OT at a fraction of the computational price.
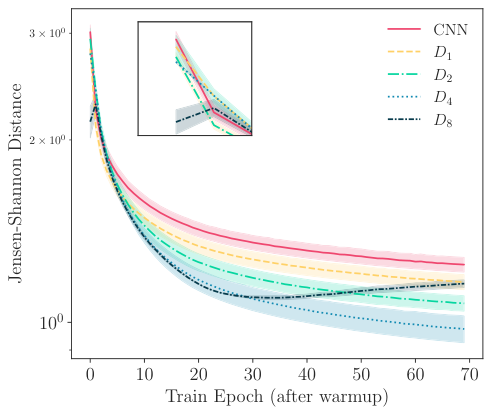
The key innovation is making this divergence dynamic: rather than computing alignment once at the start of training, SIDDA continuously updates the domain alignment loss throughout training. The network learns domain-invariant features progressively, rather than solving a rigid optimization problem upfront.
The training loop works as follows:
- Feed a batch of labeled source images and unlabeled target images through the network in parallel.
- Compute the standard classification loss on the source data.
- Compute the Sinkhorn divergence between the latent representations (the network’s compressed, abstract encoding of each image) for source and target data.
- Sum both losses with a weighting factor λ and backpropagate.
- Repeat; the domain gap shrinks progressively as training proceeds.
The λ weight is the one adjustable setting that matters, and it proves remarkably stable across datasets. This plug-and-play behavior is a genuine practical advance over methods like Maximum Mean Discrepancy (another measure of distributional difference) or adversarial domain adaptation (which pits two networks against each other to force alignment), both of which require careful per-dataset tuning.
SIDDA’s second distinguishing feature is its synergy with equivariant neural networks (ENNs), networks that mathematically enforce symmetry rather than learning it approximately from data. Standard convolutional networks learn approximate symmetries from data; ENNs bake them in. For galaxy images and other rotationally symmetric objects, this matters enormously.
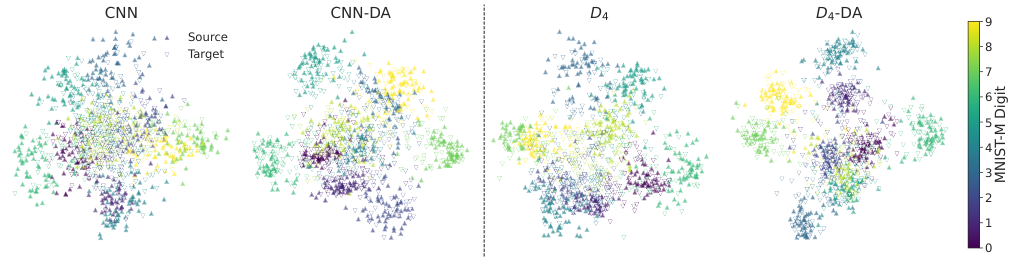
The authors test ENNs with dihedral group symmetry $D_N$ (rotational and reflection symmetry at $N$ discrete angles) and find a clean result: the higher the degree of equivariance, the better SIDDA performs. Symmetry and domain adaptation reinforce each other.
Why It Matters
The immediate application is astronomy, and the stakes are high. Next-generation surveys (the Vera Rubin Observatory’s LSST, the Nancy Grace Roman Space Telescope, and the Euclid mission) will produce data volumes no human team can manually classify. Pipelines trained on simulations will be deployed on real sky, and every percentage point lost to domain shift is a percentage point of scientific insight lost.
SIDDA closes that gap systematically, without requiring each new survey team to spend months tuning adaptation parameters.
The implications extend well beyond astronomy. The paper demonstrates SIDDA on remote sensing data, handwritten digits, and synthetic shapes, a deliberately diverse set of testbeds. Medical imaging faces the same training-deployment headaches when MRI machines from different manufacturers produce subtly different scans. Autonomous driving faces it when weather changes.
Any setting where models are trained in one environment and deployed in another (nearly every real-world deployment) stands to benefit.
Open questions remain. The current framework is unsupervised on the target side, assuming no labeled target data at all. Semi-supervised extensions, where even a handful of target labels are available, could push accuracy higher still. And while the paper studies dihedral symmetry groups, the interaction between continuous symmetry groups and Sinkhorn alignment is largely unexplored territory.
Bottom Line: SIDDA achieves up to ~40% classification accuracy gains and over an order of magnitude improvement in calibration error on unlabeled target data, with almost no hyperparameter tuning, making reliable and generalizable neural networks practical for astronomy and beyond.
IAIFI Research Highlights
This work bridges optimal transport theory from mathematics with equivariant neural network architectures from physics-informed machine learning, solving a critical bottleneck in deploying simulation-trained models on real astronomical data.
SIDDA introduces a dynamic, nearly hyperparameter-free domain adaptation algorithm that outperforms existing methods across diverse image datasets, with the added finding that higher-order equivariance systematically improves adaptation performance.
By enabling models trained on simulated universes to generalize reliably to real telescope data, SIDDA accelerates the science pipeline for next-generation surveys like LSST and Euclid that will probe dark energy, gravitational lensing, and galaxy evolution at unprecedented scale.
The SIDDA codebase is open-source and available for broad use across multi-dataset scientific studies; the full paper is available at [arXiv:2501.14048](https://arxiv.org/abs/2501.14048).