
Sparse, self-organizing ensembles of local kernels detect rare statistical anomalies
Authors
Gaia Grosso, Sai Sumedh R. Hindupur, Thomas Fel, Samuel Bright-Thonney, Philip Harris, Demba Ba
Abstract
Modern artificial intelligence has revolutionized our ability to extract rich and versatile data representations across scientific disciplines. Yet, the statistical properties of these representations remain poorly controlled, causing misspecified anomaly detection (AD) methods to falter. Weak or rare signals can remain hidden within the apparent regularity of normal data, creating a gap in our ability to detect and interpret anomalies. We examine this gap and identify a set of structural desiderata for detection methods operating under minimal prior information: sparsity, to enforce parsimony; locality, to preserve geometric sensitivity; and competition, to promote efficient allocation of model capacity. These principles define a class of self-organizing local kernels that adaptively partition the representation space around regions of statistical imbalance. As an instantiation of these principles, we introduce SparKer, a sparse ensemble of Gaussian kernels trained within a semi-supervised Neyman--Pearson framework to locally model the likelihood ratio between a sample that may contain anomalies and a nominal, anomaly-free reference. We provide theoretical insights into the mechanisms that drive detection and self-organization in the proposed model, and demonstrate the effectiveness of this approach on realistic high-dimensional problems of scientific discovery, open-world novelty detection, intrusion detection, and generative-model validation. Our applications span both the natural- and computer-science domains. We demonstrate that ensembles containing only a handful of kernels can identify statistically significant anomalous locations within representation spaces of thousands of dimensions, underscoring both the interpretability, efficiency and scalability of the proposed approach.
Concepts
The Big Picture
Imagine trying to find a single counterfeit bill hidden in the Federal Reserve vault, not by examining each bill individually, but by noticing a subtle wrinkle in the statistical texture of the entire collection. That’s the challenge anomaly detection faces at its hardest: finding signals so rare and so subtle they barely disturb the vast ocean of normal data surrounding them.
Scientists depend on anomaly detection constantly. Particle physicists sift collider data for glimpses of new physics. Cybersecurity engineers scan network traffic for intrusions. AI researchers probe whether generative models produce realistic outputs. In every case, the hard part isn’t catching glaring outliers. It’s catching the quiet ones: anomalies that blend in, overlap with normal data, and reveal themselves only as the faintest statistical whisper.
Most anomaly detection methods quietly assume that anomalies are either common enough to learn from, or different enough to stand out. When neither is true, they fail. A team from MIT, Harvard, and IAIFI built SparKer for exactly this hardest case.
Key Insight: SparKer uses a handful of self-organizing pattern detectors to locate statistically significant anomalies buried in data spaces stretching across thousands of dimensions, combining the efficiency of simple models with interpretability that reveals where and why something looks anomalous.
How It Works
The team started not by building a model, but by asking what properties an anomaly detector must have when you know almost nothing about the anomaly’s shape.
They landed on three design principles:
- Sparsity: Use as few components as possible. Don’t waste model capacity on normal regions of data space.
- Locality: Focus attention geometrically. Anomalies are local distortions of the data distribution.
- Competition: Force components to specialize. Rather than overlapping redundantly, kernels compete to “own” distinct anomalous regions.
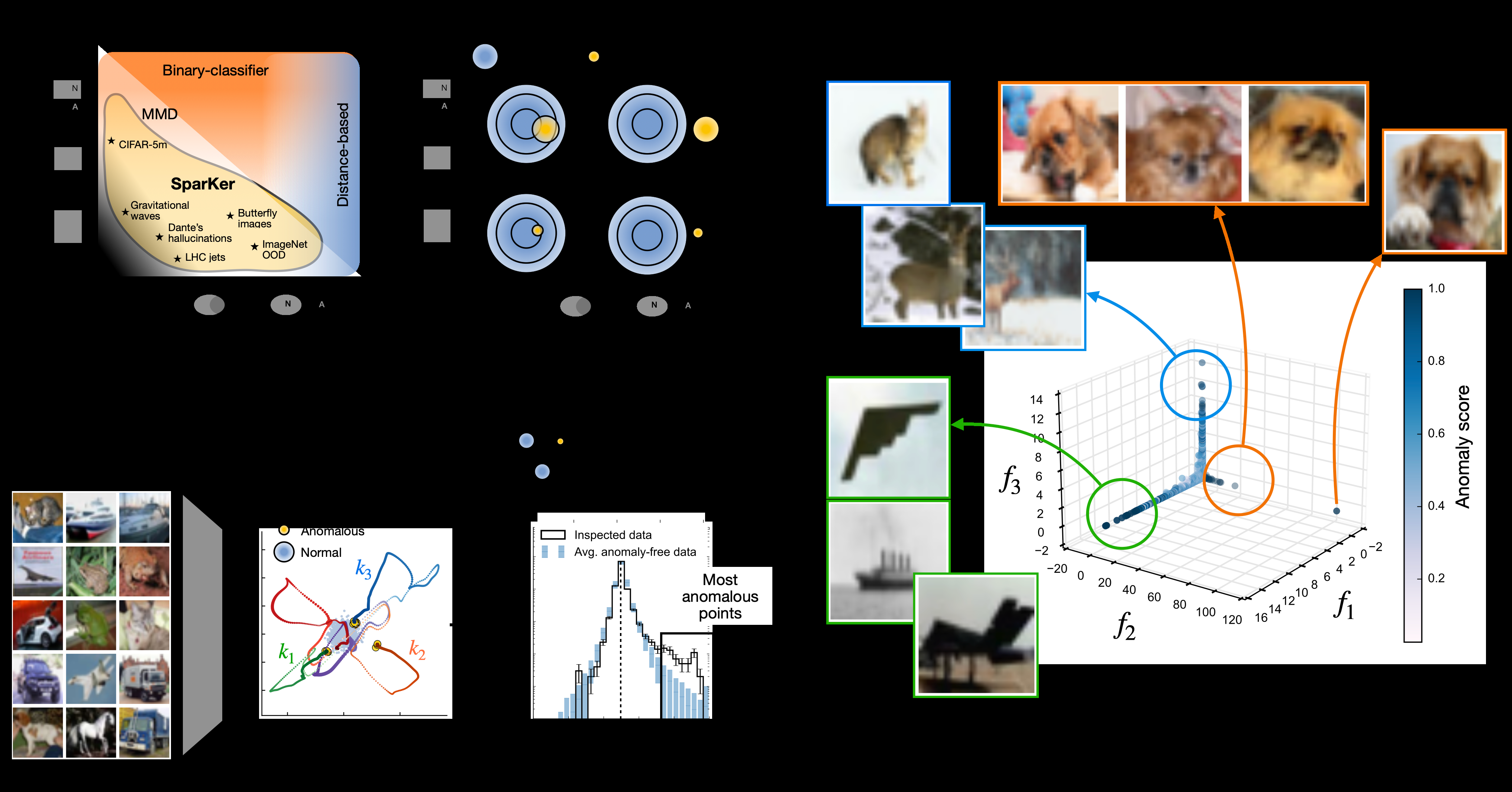
These principles lead to a concrete model. SparKer consists of a sparse ensemble of Gaussian kernels (localized bump functions measuring similarity in high-dimensional space) trained within a Neyman-Pearson framework, a classical statistical approach that maximizes detection power at a controlled false-alarm rate.
The training is semi-supervised: the model has access to a clean reference dataset (anomaly-free) and a test dataset that might contain anomalies, but receives no labels identifying which points are anomalous. It learns to estimate the log-likelihood ratio between the two: how much more likely a given data point is under the test distribution than the reference.
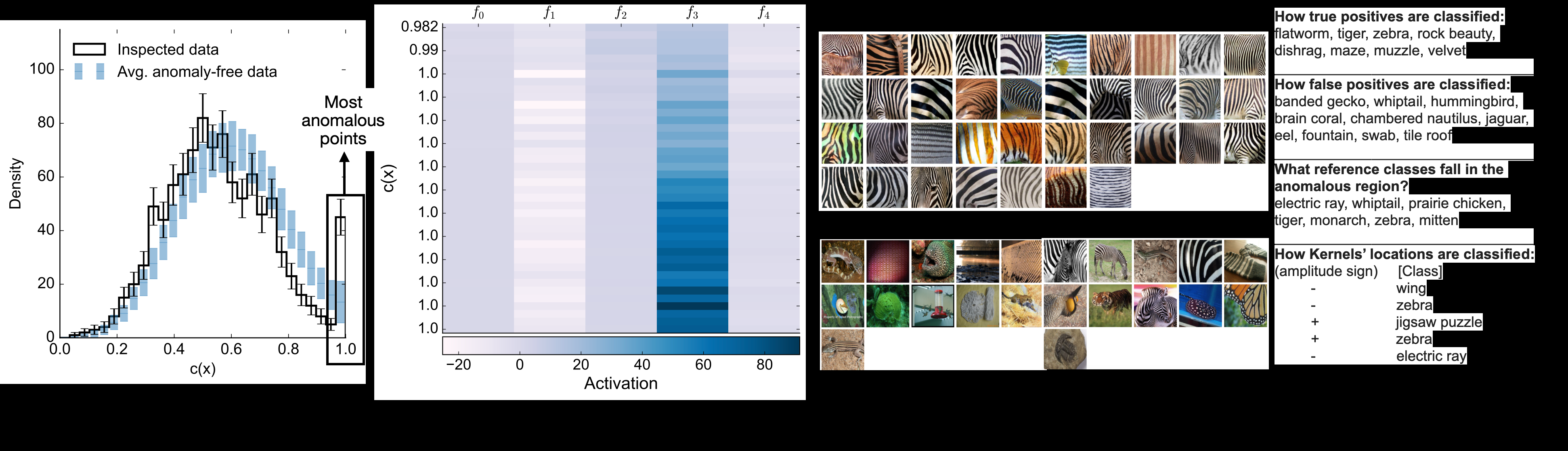
What makes SparKer distinctive is how its kernels self-organize. During training, competition pushes each kernel to stake out its own territory, migrating toward regions of statistical imbalance where the test and reference distributions diverge most. When training converges, each kernel has settled on a distinct anomalous region, its contribution to the total anomaly score both localized and interpretable.
The end product: a model that identifies statistically significant anomalous regions using as few as five to ten kernels, in representation spaces stretching into thousands of dimensions. The researchers also provide theoretical grounding through a teacher/student framework (where an idealized “teacher” represents the true anomaly pattern and the model plays “student” learning to recover it) to characterize detection power and the dynamics of self-organization during training.
Why It Matters
In particle physics, SparKer picks up rare signal events embedded in simulated collider datasets, the kind of model-independent search that might catch new physics no one thought to look for. In computer vision, it validates generative image models by detecting subtle distributional mismatches between real and generated data. In network security, it flags intrusion events in high-dimensional traffic logs.
The same underlying challenge connects these domains: anomalies that are both rare and closely resemble normal data, buried in datasets with thousands of dimensions. One framework handling all three without domain-specific tuning says something about the soundness of the design.
Because each kernel corresponds to a localized region of data space, the model can tell you not just that something is anomalous, but roughly where the anomaly lives and what distinguishes it from normal data. That kind of interpretability matters as AI systems grow more complex and harder to audit.
Generative model validation is one application the team singles out. As large language models and image generators proliferate, being able to pinpoint where their outputs deviate from real data is no longer optional.
Bottom Line: SparKer shows that a small, carefully designed ensemble of local kernels, guided by three principled constraints, can catch the statistical anomalies that larger, less structured models miss, with enough interpretability to explain what it found and why.
IAIFI Research Highlights
SparKer was developed at the boundary of particle physics and machine learning, applying statistical inference methods from high-energy physics (including the Neyman-Pearson framework) to anomaly detection problems in both natural science and computer science.
SparKer advances anomaly detection by replacing flexible but poorly controlled deep models with sparse, self-organizing kernel ensembles that are theoretically grounded, computationally efficient, and interpretable, properties that matter most when deploying AI in high-stakes settings.
For physics applications, SparKer enables model-independent searches for rare new phenomena in high-dimensional collider data, targeting the hardest regime where signals are both rare and closely overlapping with Standard Model backgrounds.
Future directions include applying SparKer to larger-scale particle physics datasets and extending the self-organization theory to more complex kernel families. The full paper is available at [arXiv:2511.03095](https://arxiv.org/abs/2511.03095).