
SPLASH: A Rapid Host-Based Supernova Classifier for Wide-Field Time-Domain Surveys
Authors
Adam Boesky, V. Ashley Villar, Alexander Gagliano, Brian Hsu
Abstract
The upcoming Legacy Survey of Space and Time (LSST) conducted by the Vera C. Rubin Observatory will detect millions of supernovae (SNe) and generate millions of nightly alerts, far outpacing available spectroscopic resources. Rapid, scalable photometric classification methods are therefore essential for identifying young SNe for follow-up and enabling large-scale population studies. We present SPLASH, a host-based classification pipeline that infers supernova classes using only host galaxy photometry. SPLASH first associates SNe with their hosts (yielding a redshift estimate), then infers host galaxy stellar mass and star formation rate using deep learning, and finally classifies SNe using a random forest trained on these inferred properties, along with host-SN angular separation and redshift. SPLASH achieves a binary (Type Ia vs. core-collapse) classification accuracy of $76\%$ and an F1-score of $69\%$, comparable to other state-of-the-art methods. By selecting only the most confident predictions, SPLASH can return highly pure subsets of all major SN types, making it well-suited for targeted follow-up. Its efficient design allows classification of $\sim 500$ SNe per second, making it ideal for next-generation surveys. Moreover, its intermediate inference step enables selection of transients by host environment, providing a tool not only for classification but also for probing the demographics of stellar death.
Concepts
The Big Picture
Imagine trying to identify every species of bird on Earth, not by watching them fly or listening to their calls, but purely by looking at the trees they nest in. It sounds like a long shot, yet this is essentially the trick astronomers have built into a new AI system called SPLASH: classifying exploding stars by studying where they live, not how they look.
Every night, somewhere in the universe, a star dies in a cataclysmic explosion called a supernova. These events scatter heavy elements across galaxies, power cosmic chemical evolution, and act as “standard candles” (objects with known intrinsic brightness that let us measure cosmic distances). Studying them in detail requires spectroscopy, which amounts to shining a prism at the explosion and reading its chemical fingerprint. But spectroscopic time on the world’s telescopes is precious and finite, and it’s about to get a lot more strained.
The Vera C. Rubin Observatory, launching its Legacy Survey of Space and Time (LSST) in 2025, will detect over one million supernovae per year and generate ten million nightly transient alerts: automated flags for any object in the sky that suddenly brightens or changes. Today, astronomers can follow up roughly one in ten detected transients with spectroscopy. With LSST’s flood of data, that ratio crashes to one in five hundred. Astronomers need a way to quickly sort the promising candidates from the noise. SPLASH does exactly that, classifying 500 supernovae per second using nothing but a photograph of the host galaxy.
Key Insight: SPLASH proves you don’t need to watch a supernova evolve to classify it. The neighborhood it explodes in tells you most of what you need to know, instantly, before the explosion is even a day old.
How It Works
The SPLASH pipeline has three stages, each feeding into the next.
Stage 1: Finding the host. When LSST flags a new transient, SPLASH identifies which galaxy it belongs to using directional light radius (DLR) association, a method that accounts for the angular separation between the supernova and potential host galaxies as well as the shape and orientation of those galaxies. This step also yields a photometric redshift: an estimate of how far away the supernova is, derived from the host’s light profile.
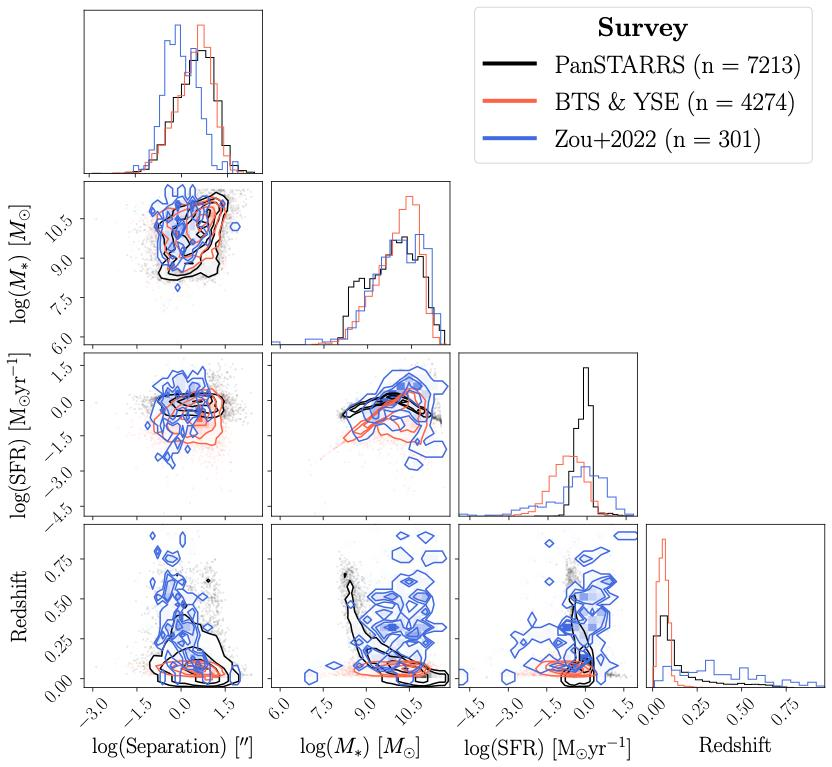
Stage 2: Reading the galaxy’s vital signs. SPLASH feeds multi-band photometric measurements of the host galaxy into a neural network trained on nearly three million galaxies from the Zou et al. (2022) catalog. The network infers two key physical properties:
- Stellar mass (M★): roughly how much “stuff” is in the galaxy, a proxy for its age and evolutionary history
- Star formation rate (SFR): how actively the galaxy is currently making new stars
These aren’t just convenient numbers. Old, massive, “red and dead” elliptical galaxies with low star formation rates overwhelmingly host Type Ia supernovae, which arise from white dwarfs (the dense, Earth-sized remnants of burned-out stars) that steal mass from a companion star until they finally explode. Young, gas-rich, actively star-forming galaxies preferentially host core-collapse supernovae (CCSNe), the deaths of massive, short-lived stars. The galaxy is, in a real sense, a record of which kind of stars it’s been making.
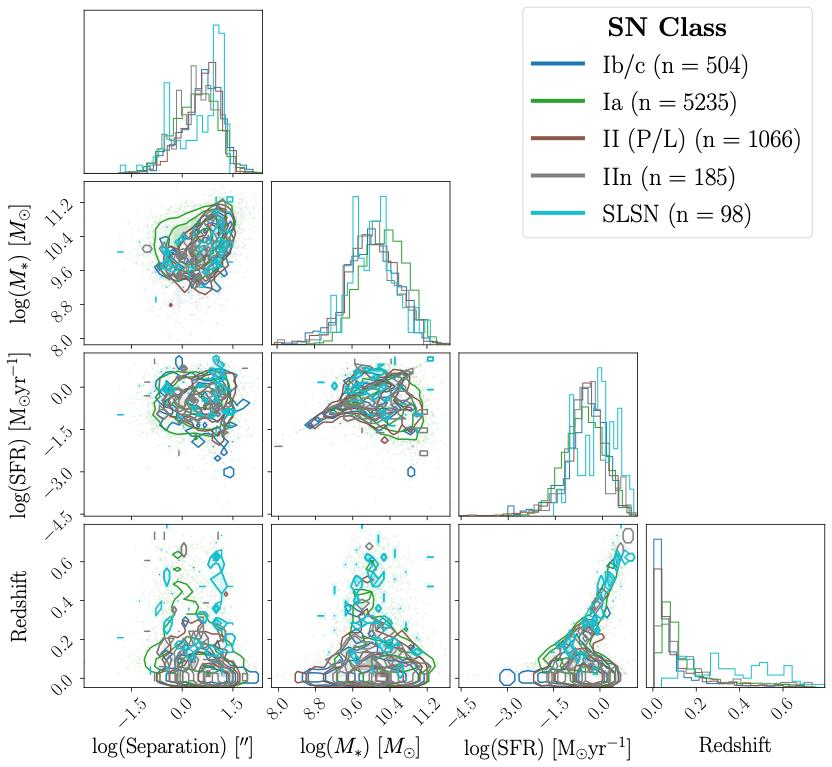
Stage 3: The random forest classifier. SPLASH takes the inferred stellar mass, star formation rate, host-SN angular separation, and redshift and feeds them into a random forest, an ensemble of decision trees that votes on the most likely supernova type. The classifier handles both binary classification (Type Ia vs. core-collapse) and finer-grained multi-class scenarios covering subtypes like Type Ib/c, Type II, and superluminous supernovae (SLSNe).
The results are competitive with state-of-the-art photometric classifiers: 76% binary accuracy and a 69% F1-score, a combined measure of how well the classifier avoids both false alarms and missed detections. SPLASH can also tune its confidence threshold to return highly pure samples. If you only want confident Type Ia candidates for a cosmology study, you can dial up the purity at the cost of completeness. That kind of flexibility matters enormously for real observational programs.
Why It Matters
The practical payoff is speed. Light-curve-based classifiers, which track how a supernova’s brightness changes over days and weeks, must wait for enough measurements to make a diagnosis. SPLASH can classify a supernova the moment it’s detected, because it only needs a picture of the host galaxy, which existed long before the explosion. That makes it uniquely suited for rapid-response programs targeting supernovae in their first hours, when signals of the original stellar environment (shells of gas ejected by the dying star before it exploded) are still accessible.
SPLASH’s value goes beyond speed, though. Because it infers physical host properties as an intermediate step, it doubles as a selection tool for studying stellar demographics. Want a sample of supernovae in low-mass, high-star-formation-rate galaxies? SPLASH can filter for that.
This opens the door to population-level studies of how stellar death rates vary with galactic environment, a window into the life cycles of stars across cosmic time. As LSST’s dataset grows over its ten-year run, tools like SPLASH will be essential for carving massive catalogs into scientifically meaningful subpopulations.
Bottom Line: SPLASH classifies 500 supernovae per second using only host galaxy photometry, achieving 76% accuracy at the moment of detection. It’s an ideal first-response tool for the data tsunami that LSST is about to unleash.
IAIFI Research Highlights
SPLASH sits squarely at the intersection of astrophysics and machine learning. Deep neural networks extract galaxy physics from photometry, then feed those physical priors into a downstream classifier. The pipeline architecture mirrors the real causal chain from stellar environment to stellar death.
The two-stage approach (inferring interpretable physical properties before classification, rather than classifying from raw photometry) shows how embedding domain knowledge into an ML pipeline can improve generalization while also producing a scientifically useful intermediate product.
Rapid, environment-aware classification of millions of supernovae accelerates discovery on multiple fronts: constraining progenitor physics, measuring the cosmic equation of state through Type Ia cosmology, and mapping how star formation history drives transient demographics.
Future work will incorporate photometric light-curve data alongside host properties to push accuracy further, and the pipeline can scale with LSST's alert stream from day one; see [arXiv:2506.00121](https://arxiv.org/abs/2506.00121) (Boesky et al. 2025).