
Symbolic Regression on FPGAs for Fast Machine Learning Inference
Authors
Ho Fung Tsoi, Adrian Alan Pol, Vladimir Loncar, Ekaterina Govorkova, Miles Cranmer, Sridhara Dasu, Peter Elmer, Philip Harris, Isobel Ojalvo, Maurizio Pierini
Abstract
The high-energy physics community is investigating the potential of deploying machine-learning-based solutions on Field-Programmable Gate Arrays (FPGAs) to enhance physics sensitivity while still meeting data processing time constraints. In this contribution, we introduce a novel end-to-end procedure that utilizes a machine learning technique called symbolic regression (SR). It searches the equation space to discover algebraic relations approximating a dataset. We use PySR (a software to uncover these expressions based on an evolutionary algorithm) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimize the top metric by pinning the network size because the vast hyperparameter space prevents an extensive search for neural architecture. Conversely, SR selects a set of models on the Pareto front, which allows for optimizing the performance-resource trade-off directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our method on a physics benchmark: the multiclass classification of jets produced in simulated proton-proton collisions at the CERN Large Hadron Collider. We show that our approach can approximate a 3-layer neural network using an inference model that achieves up to a 13-fold decrease in execution time, down to 5 ns, while still preserving more than 90% approximation accuracy.
Concepts
The Big Picture
Imagine trying to photograph a hummingbird mid-flight using a camera with a shutter speed measured in geological time. That’s roughly the challenge facing physicists at the Large Hadron Collider: proton-proton collisions happen 40 million times per second, and the detector must decide almost instantly which collisions are worth keeping. Miss the window, and the data is gone forever.
The LHC’s real-time filtering system, the trigger, has a budget of roughly one microsecond to classify each collision event. That’s a hard physical constraint, not a guideline. Traditional deep learning models are powerful, but they carry computational weight that can blow this budget.
Field-Programmable Gate Arrays (FPGAs) are chips whose internal circuitry can be reconfigured for specific tasks, and they’re fast enough to meet this constraint. But they need extremely lean algorithms to run on them.
Researchers from MIT, Princeton, Wisconsin, and CERN have demonstrated a surprising solution: instead of compressing a neural network onto an FPGA, they let an AI discover a compact algebraic equation to do the job. The result runs in 5 nanoseconds, 13 times faster than the baseline neural network, preserving more than 90% of its accuracy.
Key Insight: Symbolic regression doesn’t just approximate a neural network. It replaces it with a mathematical formula that hardware can evaluate nearly instantaneously, making physics-quality ML feasible at timescales that were previously out of reach.
How It Works
The core technique is symbolic regression (SR), a machine learning method that searches for mathematical equations rather than tuning parameters inside a fixed architecture. Where a neural network is a black box of weights and activations, SR outputs something you can actually read: an equation like y = x₁ sin(x₂) + 3.4 x₃².
The team used PySR, an open-source SR tool built on Julia. PySR employs an evolutionary algorithm that:
- Grows expression trees (tree-shaped structures representing mathematical formulas) by combining constants, variables, and operators (
+,−,×,/,sin,x²) - Mutates and crossbreeds the best candidates across generations
- Converges toward a Pareto front of solutions, each representing a different tradeoff between equation complexity and accuracy
That Pareto front is the key advantage over deep learning. When you train a neural network, you pick an architecture and optimize within it. With SR, you get an entire menu of models. Choose the equation that fits your FPGA’s resource budget, or the one that maximizes accuracy if you have headroom. You navigate the tradeoff explicitly, not accidentally.
The benchmark problem is jet tagging: classifying particle jets as originating from a quark, gluon, W boson, Z boson, or top quark. The dataset uses 16 physics-motivated features capturing the internal structure and energy distribution of each jet. The baseline is a three-hidden-layer neural network (64, 32, 32 nodes) from the hls4ml benchmarking suite, achieving ~75% overall accuracy.
The team trained five independent SR expressions, one per jet class. To deploy them on actual FPGA hardware, they extended hls4ml, the standard tool for converting ML models to FPGA firmware, to parse and synthesize PySR-generated expressions. They also added support for approximating transcendental functions using lookup tables (LUTs), trading a small amount of precision for dramatic speed and resource gains.
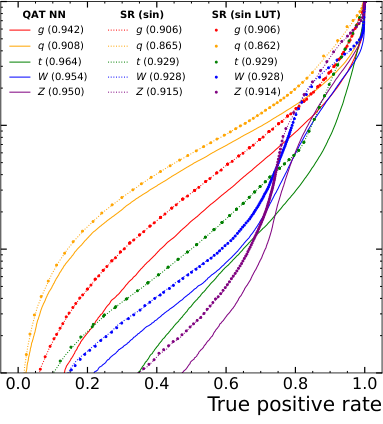
LUT-based approximations for sine and tangent show tiny deviations from exact values, but the resource savings are substantial.
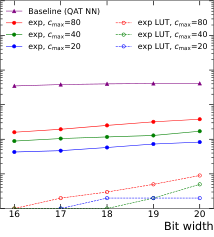
The performance-resource comparison tells the full story. SR models sit near the neural network’s accuracy level while consuming dramatically fewer FPGA resources. The most aggressive SR expression achieves 13× lower latency, down to 5 ns, while retaining over 90% accuracy. Even at higher complexity settings, SR expressions consistently outperform the neural network on the latency-vs-accuracy curve.
Why It Matters
This work matters beyond the LHC. The same constraint (ultra-fast inference on resource-limited hardware) appears in medical imaging devices, autonomous vehicles, and satellite instruments. Neural networks are increasingly the default, but they carry irreducible computational overhead. Symbolic regression offers models that are simultaneously fast, interpretable, and hardware-efficient.
Within particle physics, the implications are immediate. The LHC’s High-Luminosity upgrade will increase collision rates further, tightening the latency budget even more. Showing that SR can match neural network performance at 5 ns opens a new design space for trigger algorithms.
The equations are also human-readable. Physicists can reason about them and potentially extract physical insight from their structure. Future directions include b-jet tagging, anomaly detection, and full event reconstruction, where speed combined with interpretability could prove decisive. The hls4ml extensions are open-source and already integrated into the broader fast ML ecosystem, so the community can adopt this pipeline immediately.
Bottom Line: By replacing a neural network with a compact algebraic equation discovered through evolutionary search, this approach achieves 13× faster FPGA inference at 5 ns, fast enough to fit inside the LHC’s microsecond trigger window, while keeping accuracy above 90%. It’s a rare case where a simpler model is also the smarter one.
IAIFI Research Highlights
This work bridges modern machine learning (symbolic regression and evolutionary algorithms) with experimental particle physics, showing that interpretable AI can meet the extreme real-time demands of LHC trigger systems.
The integration of PySR with hls4ml establishes a new end-to-end pipeline for deploying symbolic ML models on FPGAs, extending the reach of SR from research discovery into production hardware inference.
By enabling 5 ns jet classification on FPGAs, this approach makes physics-sensitive real-time triggering feasible at the LHC and provides a blueprint for High-Luminosity LHC upgrades, where latency constraints become even more stringent.
Future work will apply SR-on-FPGA to more complex HEP classification tasks and anomaly detection; the full methodology and code are described in [arXiv:2305.04099](https://arxiv.org/abs/2305.04099) and the associated hls4ml tutorial repository.