
Symbolic Regression with Multimodal Large Language Models and Kolmogorov Arnold Networks
Authors
Thomas R. Harvey, Fabian Ruehle, Kit Fraser-Taliente, James Halverson
Abstract
We present a novel approach to symbolic regression using vision-capable large language models (LLMs) and the ideas behind Google DeepMind's Funsearch. The LLM is given a plot of a univariate function and tasked with proposing an ansatz for that function. The free parameters of the ansatz are fitted using standard numerical optimisers, and a collection of such ansätze make up the population of a genetic algorithm. Unlike other symbolic regression techniques, our method does not require the specification of a set of functions to be used in regression, but with appropriate prompt engineering, we can arbitrarily condition the generative step. By using Kolmogorov Arnold Networks (KANs), we demonstrate that ``univariate is all you need'' for symbolic regression, and extend this method to multivariate functions by learning the univariate function on each edge of a trained KAN. The combined expression is then simplified by further processing with a language model.
Concepts
The Big Picture
Imagine handing a graph to a physicist and asking, “What equation made this?” Within seconds, they might sketch out a guess, maybe a sine wave decaying under an exponential, and they’d probably be right. That flash of pattern recognition, built from years of staring at equations and their curves, is something computers have historically been terrible at. Traditional software handed the same graph tends to vomit back a 19th-degree polynomial that technically fits the data but tells you absolutely nothing about the underlying physics.
This gap sits at the heart of symbolic regression: the challenge of finding the actual mathematical formula, in clean human-readable form, that produced a set of data. When physicists find the right equation, they understand something real about the universe. When they get a polynomial approximation, they’ve gained little more than a lookup table.
Now, a team from MIT, Northeastern, and Oxford has found a way to give computers something resembling that physicist’s intuition. Their trick? Ask an AI that can process images to literally look at the graph and take a guess.
Key Insight: By showing a large language model a picture of a function and asking it to propose a formula, researchers opened a new route to symbolic regression, one that requires almost no assumptions about what kinds of functions to look for.
How It Works
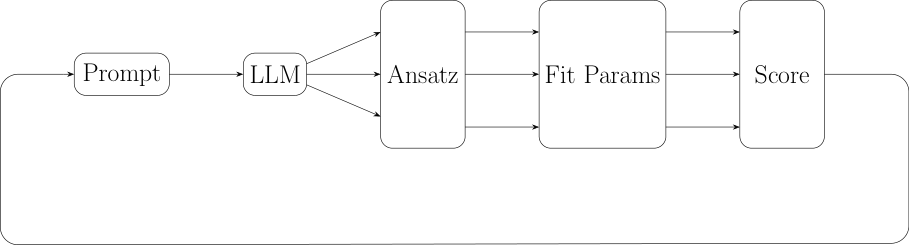
The core idea is simple. Show a multimodal LLM (an AI that processes both text and images; here, gpt-4o) a plot of a mathematical function, and ask it to suggest an ansatz: a candidate formula with free parameters like a, b, c. Then use a standard numerical optimizer to fit those parameters to the actual data.
The first example in the paper makes the case immediately. Given a plot of y = e^(−10x²) sin(2x), an oscillating, decaying wave, Mathematica’s FindFormula returns a grotesque 19th-degree polynomial. The LLM, shown the same graph, proposes:
curve = lambda x, params: np.sin(params[0]*x) * np.exp(-params[1]*x**2)That’s the correct functional form. The model recognized the oscillation, the decay, and combined them, just as a trained physicist would.
A single LLM guess isn’t reliable, of course. So the researchers incorporated a genetic algorithm, an optimization technique inspired by biological evolution and the same core idea behind Google DeepMind’s FunSearch. Instead of one guess, the system generates a population of candidate expressions. The best-fitting ones survive, get recombined and mutated via the LLM, and the cycle repeats. Over generations, the population evolves toward increasingly accurate expressions.
The full pipeline:
- Generate — Show the LLM a plot; collect multiple proposed ansätze
- Fit — Optimize free parameters for each candidate using standard numerical methods
- Score — Rank candidates by how well they fit the data
- Evolve — Pass top performers back to the LLM to generate improved variants
- Repeat — Run for multiple generations until convergence
Unlike most symbolic regression methods, this approach requires no predefined library of allowed functions. The LLM draws on its entire training: virtually every mathematical function humans have written about, including exotic forms like Bessel functions (curves that arise in physics problems involving waves and cylindrical geometry). Want to hint that the solution involves unusual mathematical forms from physics? Just say so in the prompt.
Real physics problems are rarely univariate. A formula describing particle interactions might depend on dozens of variables simultaneously. The researchers extended their method using the Kolmogorov–Arnold representation theorem, which guarantees that any continuous multivariate function can be decomposed into sums and compositions of univariate functions.
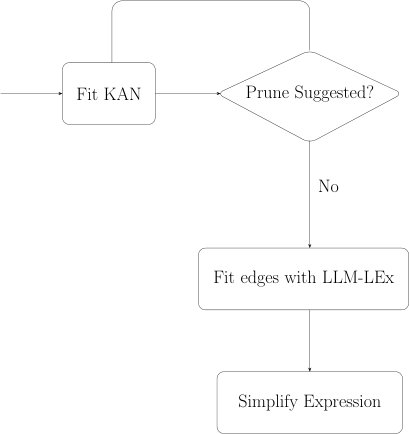
Their combined system, KAN-LEx, trains a Kolmogorov–Arnold Network (KAN) on the dataset. A trained KAN represents its function as a graph where each edge carries a learned univariate transformation. The image-based symbolic regression method then identifies each edge separately, and a final LLM pass assembles and simplifies the full expression.
“Univariate is all you need” captures the philosophy. Reduce a hard multivariate problem to a collection of easy univariate problems, then solve each with the same image-based approach.
Benchmarking against methods like gplearn showed KAN-LEx is competitive, and sometimes better, particularly for functions with structure that resists purely syntactic search. The entire initial implementation fit in roughly 100 lines of Python.
Why It Matters
Symbolic regression is a tool scientists reach for when they want to discover laws, not just model data. The ability to guide that search using plain-English domain knowledge has no precedent in mainstream symbolic regression tools. A physicist studying a new phenomenon can say, “I think the answer involves Bessel functions” or “this should grow without bound near zero,” and the algorithm takes that seriously.
The KAN combination also matters for scale. As KAN architectures improve, KAN-LEx could tackle increasingly high-dimensional scientific datasets of the kind that arise in string theory landscape searches, particle physics parameter spaces, or climate modeling. Because the method is modular, any future improvement to univariate symbolic regression automatically improves the whole pipeline.
Open questions remain. How does performance scale with function complexity? How sensitive is the method to prompt phrasing? Can open-weight models eventually match proprietary ones? Benchmarks suggest open models lag behind gpt-4o today, but the gap may close. The promise is straightforward: a physicist who suspects their data conceals a clean equation can describe their intuition in plain language and let an AI evolve the answer.
Bottom Line: Teaching an AI to look at a graph and guess the equation, then evolving those guesses like organisms, produces a symbolic regression tool that’s both accurate and unusually flexible. The full method is described in arXiv:2505.07956.
IAIFI Research Highlights
This work fuses computer vision, large language model reasoning, and the Kolmogorov–Arnold representation theorem into a new symbolic regression pipeline, connecting deep learning architectures with a core problem in mathematical physics.
LLM-LEx shows that multimodal LLMs can perform structured mathematical reasoning from visual input, enabling steerable, assumption-free function discovery in roughly 100 lines of code.
By making symbolic regression flexible and physics-aware through prompt engineering, this method lowers the bar for discovering compact, interpretable equations in theoretical and experimental physics.
Future work includes scaling KAN-LEx to higher-dimensional problems and improving open-model performance; the paper and code are publicly available at [arXiv:2505.07956](https://arxiv.org/abs/2505.07956).
Original Paper Details
Symbolic Regression with Multimodal Large Language Models and Kolmogorov Arnold Networks
[2505.07956](https://arxiv.org/abs/2505.07956)
Thomas R. Harvey, Fabian Ruehle, Kit Fraser-Taliente, James Halverson