
SymbolNet: Neural Symbolic Regression with Adaptive Dynamic Pruning for Compression
Authors
Ho Fung Tsoi, Vladimir Loncar, Sridhara Dasu, Philip Harris
Abstract
Compact symbolic expressions have been shown to be more efficient than neural network models in terms of resource consumption and inference speed when implemented on custom hardware such as FPGAs, while maintaining comparable accuracy~\cite{tsoi2023symbolic}. These capabilities are highly valuable in environments with stringent computational resource constraints, such as high-energy physics experiments at the CERN Large Hadron Collider. However, finding compact expressions for high-dimensional datasets remains challenging due to the inherent limitations of genetic programming, the search algorithm of most symbolic regression methods. Contrary to genetic programming, the neural network approach to symbolic regression offers scalability to high-dimensional inputs and leverages gradient methods for faster equation searching. Common ways of constraining expression complexity often involve multistage pruning with fine-tuning, which can result in significant performance loss. In this work, we propose $\tt{SymbolNet}$, a neural network approach to symbolic regression specifically designed as a model compression technique, aimed at enabling low-latency inference for high-dimensional inputs on custom hardware such as FPGAs. This framework allows dynamic pruning of model weights, input features, and mathematical operators in a single training process, where both training loss and expression complexity are optimized simultaneously. We introduce a sparsity regularization term for each pruning type, which can adaptively adjust its strength, leading to convergence at a target sparsity ratio. Unlike most existing symbolic regression methods that struggle with datasets containing more than $\mathcal{O}(10)$ inputs, we demonstrate the effectiveness of our model on the LHC jet tagging task (16 inputs), MNIST (784 inputs), and SVHN (3072 inputs).
Concepts
The Big Picture
Imagine you’re a physicist at CERN, and a particle collision happens every 25 nanoseconds. Your detector must decide in real time whether to keep or discard that event, with the compute budget of a calculator, not a supercomputer. Deep learning models are too slow, too hungry. What you want is a compact formula written on a napkin.
Symbolic regression tries to find that formula automatically. Instead of fitting data to a pre-defined equation, it searches the space of all possible mathematical expressions (addition, multiplication, sine, square roots) to discover the one that fits best. It’s a modern version of what Max Planck did in 1900: stare at data from glowing hot objects, find a formula that fits the curve, and accidentally invent quantum mechanics.
The problem? Classical symbolic regression algorithms choke when data has more than roughly ten input variables. Physics datasets at the LHC (Large Hadron Collider) have hundreds or thousands.
SymbolNet is a neural network framework that closes this gap. It performs symbolic regression on high-dimensional inputs while pruning away unnecessary variables, operators, and connections, all in a single training run.
Key Insight: SymbolNet treats symbolic regression as a compression problem, using adaptive dynamic pruning to optimize both model accuracy and expression compactness. This scales symbolic regression to thousands of input features for the first time.
How It Works
The traditional approach to symbolic regression is genetic programming (GP), an evolutionary algorithm that breeds and mutates mathematical formulas across generations, selecting the fittest survivors. It works for small problems but becomes intractably slow as input dimensionality grows. SymbolNet replaces the evolutionary search with a neural network whose architecture produces human-readable symbolic expressions by construction.
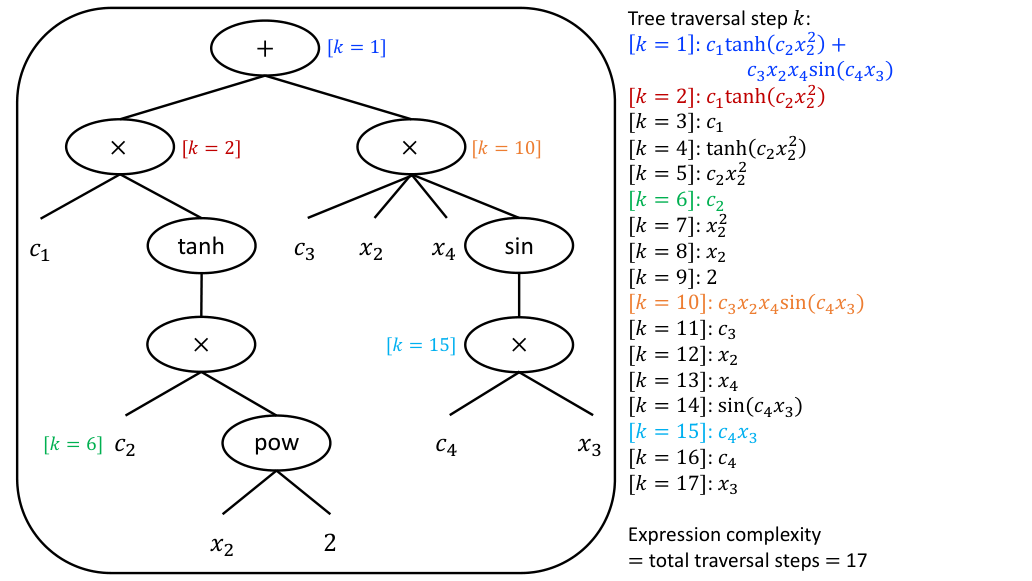
Each neuron applies one function from a library of activation functions: addition, multiplication, square, sine, absolute value, and so on. The network learns which operators to keep and which to simplify. A complex sine function might collapse to a linear term if the data doesn’t require it, reducing complexity without human intervention. This is called operator pruning.
SymbolNet prunes three things at once during a single training pass:
- Model weights — individual connection strengths, the standard form of network sparsity
- Input features — entire input variables, performing automatic feature selection
- Mathematical operators — complex functions downgraded to simpler arithmetic
Each prunable element carries a trainable threshold, a learned cutoff that determines what survives. A weight survives if its magnitude exceeds its threshold; otherwise it’s masked to zero. The network continuously renegotiates what to keep based on its impact on accuracy.
To prevent the network from ignoring sparsity, SymbolNet adds a self-adaptive regularization term for each pruning type. This regularization adjusts its own strength during training: if the expression is still too complex, the penalty increases; if sparsity is already at target, it relaxes. The user specifies a desired sparsity ratio (say, keep only 10% of weights) and training converges there automatically, without manual coefficient tuning.
Why It Matters
SymbolNet was tested on three datasets spanning vastly different scales. For LHC jet tagging (16 inputs), it matched or outperformed baseline neural symbolic regression methods while producing significantly sparser expressions. On MNIST (784 pixel inputs) and binary SVHN (3,072 inputs, street house numbers from photographs), SymbolNet produced compact symbolic expressions for image-scale inputs, something no prior symbolic regression tool had managed.
The payoff for compactness is speed. When the extracted expressions were synthesized onto an FPGA (a reconfigurable hardware chip used in LHC trigger systems), inference ran in nanoseconds with a fraction of the resource usage of a conventional neural network. For jet tagging, the FPGA implementation achieved latency comparable to hls4ml-compressed networks (a tool for converting neural networks into hardware firmware) but with a far simpler, auditable expression underneath.
At the LHC, the first-level hardware trigger must process 40 million collisions per second and reduce that stream to a manageable size in microseconds. Every nanosecond counts, and every FPGA lookup table is a scarce resource shared across an entire detector.
SymbolNet’s expressions are not just fast; they’re transparent. A physicist can read the formula, check it against physical intuition, and trust it in a way that a 50-layer neural network never could. Symbolic regression has long been proposed as a path toward AI-assisted scientific discovery, where machines uncover physical laws directly from data the way Planck or Kepler did by hand. The bottleneck has always been scalability.
SymbolNet’s results on 3,072-dimensional image data suggest that neural symbolic regression is no longer confined to toy problems. Whether the expressions it finds on real physics datasets encode genuinely new physical insight remains an open question, and exactly the right question to be asking next.
Bottom Line: SymbolNet makes symbolic regression practical for high-dimensional real-world datasets by combining neural networks with single-phase adaptive pruning. The result: compact mathematical expressions that run at nanosecond latency on FPGA hardware, directly useful for physics experiments at the LHC and beyond.
IAIFI Research Highlights
SymbolNet tackles a core bottleneck between machine learning and experimental particle physics, turning neural symbolic regression into a hardware-deployable compression technique validated on LHC jet tagging tasks.
The adaptive dynamic pruning framework, which simultaneously optimizes weights, input features, and operators with self-adjusting regularization, pushes the state of the art in neural symbolic regression and scales the approach to datasets with thousands of inputs.
By enabling real-time symbolic inference on FPGAs at nanosecond latency, this work directly supports the LHC's hardware trigger pipeline, where ultra-fast and resource-efficient models are essential for capturing rare collision events.
Future work includes extending SymbolNet to multiclass tasks and exploring whether discovered expressions encode novel physical principles. The paper is available as [arXiv:2401.09949](https://arxiv.org/abs/2401.09949).
Original Paper Details
SymbolNet: Neural Symbolic Regression with Adaptive Dynamic Pruning for Compression
2401.09949
["Ho Fung Tsoi", "Vladimir Loncar", "Sridhara Dasu", "Philip Harris"]
Compact symbolic expressions have been shown to be more efficient than neural network models in terms of resource consumption and inference speed when implemented on custom hardware such as FPGAs, while maintaining comparable accuracy~\cite{tsoi2023symbolic}. These capabilities are highly valuable in environments with stringent computational resource constraints, such as high-energy physics experiments at the CERN Large Hadron Collider. However, finding compact expressions for high-dimensional datasets remains challenging due to the inherent limitations of genetic programming, the search algorithm of most symbolic regression methods. Contrary to genetic programming, the neural network approach to symbolic regression offers scalability to high-dimensional inputs and leverages gradient methods for faster equation searching. Common ways of constraining expression complexity often involve multistage pruning with fine-tuning, which can result in significant performance loss. In this work, we propose $\tt{SymbolNet}$, a neural network approach to symbolic regression specifically designed as a model compression technique, aimed at enabling low-latency inference for high-dimensional inputs on custom hardware such as FPGAs. This framework allows dynamic pruning of model weights, input features, and mathematical operators in a single training process, where both training loss and expression complexity are optimized simultaneously. We introduce a sparsity regularization term for each pruning type, which can adaptively adjust its strength, leading to convergence at a target sparsity ratio. Unlike most existing symbolic regression methods that struggle with datasets containing more than $\mathcal{O}(10)$ inputs, we demonstrate the effectiveness of our model on the LHC jet tagging task (16 inputs), MNIST (784 inputs), and SVHN (3072 inputs).