
Synthesis and Analysis of Data as Probability Measures with Entropy-Regularized Optimal Transport
Authors
Brendan Mallery, James M. Murphy, Shuchin Aeron
Abstract
We consider synthesis and analysis of probability measures using the entropy-regularized Wasserstein-2 cost and its unbiased version, the Sinkhorn divergence. The synthesis problem consists of computing the barycenter, with respect to these costs, of reference measures given a set of coefficients belonging to the simplex. The analysis problem consists of finding the coefficients for the closest barycenter in the Wasserstein-2 distance to a given measure. Under the weakest assumptions on the measures thus far in the literature, we compute the derivative of the entropy-regularized Wasserstein-2 cost. We leverage this to establish a characterization of barycenters with respect to the entropy-regularized Wasserstein-2 cost as solutions that correspond to a fixed point of an average of the entropy-regularized displacement maps. This characterization yields a finite-dimensional, convex, quadratic program for solving the analysis problem when the measure being analyzed is a barycenter with respect to the entropy-regularized Wasserstein-2 cost. We show that these coefficients, as well as the value of the barycenter functional, can be estimated from samples with dimension-independent rates of convergence, and that barycentric coefficients are stable with respect to perturbations in the Wasserstein-2 metric. We employ the barycentric coefficients as features for classification of corrupted point cloud data, and show that compared to neural network baselines, our approach is more efficient in small training data regimes.
Concepts
The Big Picture
Imagine a collection of photographs of handwritten letters: not the pixel arrays, but the ink distribution on each page. Each “A” smears ink differently: some bold and angular, others loopy and soft. Can you build a Platonic ideal of the letter A by averaging these distributions intelligently? And given an unknown ink blob, can you determine how much it resembles each letter in your alphabet?
This is the problem at the heart of new work from Tufts University researchers. Instead of ink blobs, they work with any data modeled as a probability measure: a point cloud, a distribution of particle energies, a histogram of features. The challenge: designing principled tools for synthesis (building new distributions from references) and analysis (decomposing a distribution into its components).
Their solution uses entropy-regularized optimal transport, a framework for measuring geometric distances between distributions, and they prove it works efficiently, stably, and even outperforms neural networks when labeled data is scarce.
Key Insight: Adding an entropy regularization term to classical optimal transport unlocks dimension-free convergence rates and fast computation, transforming an intractable problem into a practical data analysis tool with strong theoretical guarantees.
How It Works
Classical optimal transport (OT) measures the “distance” between two probability distributions: the minimum cost to rearrange one pile of dirt into the shape of another. The Wasserstein-2 distance squares the cost of moving each grain, making it sensitive to distributional geometry. But exact computation is expensive (cubic in the number of samples) and in high dimensions, estimation requires exponentially many samples.
Entropy regularization fixes this. The entropy-regularized Wasserstein-2 cost adds a penalty proportional to the Kullback-Leibler divergence between the transport plan and the baseline independent coupling. This seemingly small tweak has large consequences: it makes the problem parallelizable via the Sinkhorn-Knopp algorithm and the cost can be estimated from data at rates that do not depend on dimension. The Sinkhorn divergence is an unbiased variant that corrects for self-transport costs.
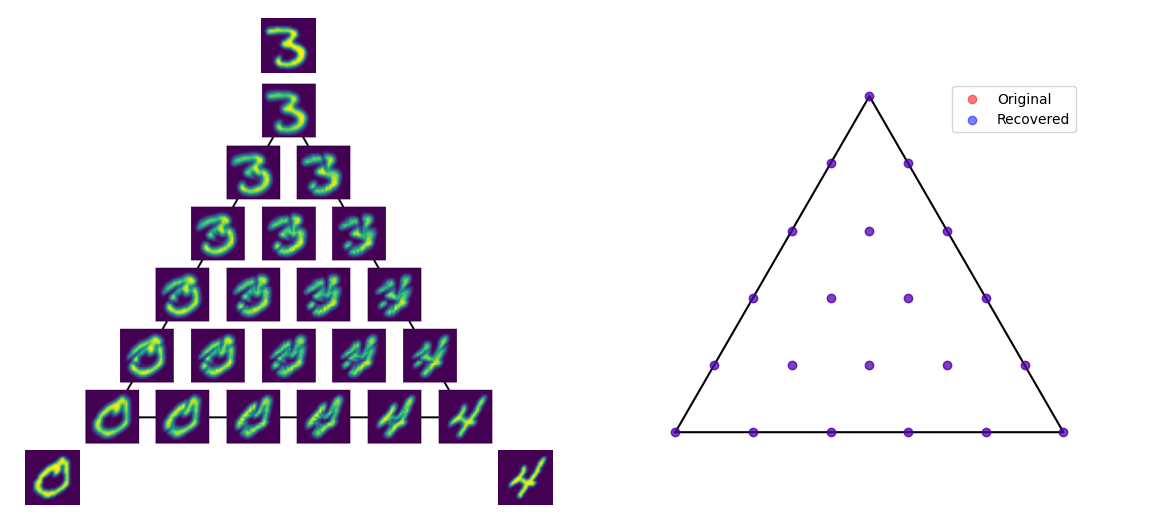
The paper tackles two linked problems:
- Synthesis (the barycenter problem): Given reference measures and a weight vector summing to one, compute their geometric “average”: a new measure that lies between the references in Wasserstein space.
- Analysis (the inverse problem): Given an unknown measure, find the weights that make the barycenter of your references as close as possible to it.
The core theoretical contribution is a fixed-point characterization of entropy-regularized barycenters. The researchers prove that a measure is a barycenter if and only if it is a fixed point of a weighted average of entropy-regularized displacement maps. Put differently, the barycenter is in equilibrium: let each reference optimally push mass toward it, take the weighted average of those pushes, and the barycenter doesn’t move.
This characterization leads to a striking practical result: when the target measure is itself a barycenter of the references, recovering its coefficients reduces to a finite-dimensional, convex quadratic program, a problem with a guaranteed unique global solution. No gradient descent, no iterative black-box optimization. Just a clean convex problem solvable to global optimality.
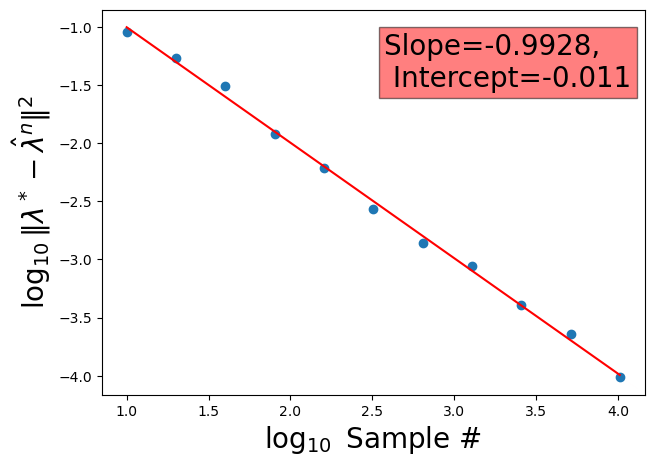
The recovered coefficients are also stable: small perturbations in the Wasserstein-2 metric produce small changes in the output. The convergence rates are dimension-independent, so the method doesn’t degrade as data dimensionality grows — which matters enormously for scientific applications.
Why It Matters
Point clouds (collections of 3D coordinates representing object surfaces) are ubiquitous in robotics, autonomous vehicles, and scientific simulation. Classifying corrupted or occluded point clouds is hard, and deep learning attacks it with complex architectures requiring large labeled datasets.
The Tufts researchers applied their barycentric coefficient framework to corrupted point cloud classification and found a clear result: using coefficients as simple features fed into a standard classifier, their method outperformed neural network baselines in small training data regimes. With only a handful of labeled examples, the geometric structure captured by optimal transport provides stronger inductive bias than a network can learn from scratch.
The reach extends beyond point clouds. Any domain where data is naturally modeled as distributions has something to gain here: particle physics (energy depositions in detectors), cosmology (galaxy surveys as point processes), materials science (atomic configurations). The dimension-free rates mean the framework scales to high-dimensional probability measures without the curse of dimensionality degrading performance.
Open questions remain. The analysis result currently requires knowing the target measure is itself a barycenter of the references. Extending robust recovery to approximate barycenters, or to settings where the reference set is learned jointly, would significantly broaden applicability.
Bottom Line: By combining entropy regularization with a new fixed-point characterization of barycenters, this work delivers a rigorous, computationally tractable framework for distribution-valued data analysis, one that provably beats deep learning when labels are scarce.
IAIFI Research Highlights
This work connects mathematical analysis (optimal transport theory, convex optimization) with practical machine learning, providing a principled alternative to neural networks for data that naturally lives in the space of probability measures, including the geometric and field-theoretic data common in fundamental physics.
The paper establishes dimension-independent convergence guarantees and a convex quadratic formulation for the analysis problem, giving AI practitioners both theoretical foundations and efficient algorithms for distribution-valued feature extraction.
The framework's provable sample efficiency with high-dimensional probability measures gives particle physicists, cosmologists, and materials scientists a new tool for analyzing datasets that are naturally represented as distributions.
Future work may extend robust barycentric analysis to approximate settings and learned reference sets; the paper appeared at AISTATS 2025, with code available at the authors' repository ([arXiv:2501.07446](https://arxiv.org/abs/2501.07446)).