
TASI Lectures on Physics for Machine Learning
Authors
Jim Halverson
Abstract
These notes are based on lectures I gave at TASI 2024 on Physics for Machine Learning. The focus is on neural network theory, organized according to network expressivity, statistics, and dynamics. I present classic results such as the universal approximation theorem and neural network / Gaussian process correspondence, and also more recent results such as the neural tangent kernel, feature learning with the maximal update parameterization, and Kolmogorov-Arnold networks. The exposition on neural network theory emphasizes a field theoretic perspective familiar to theoretical physicists. I elaborate on connections between the two, including a neural network approach to field theory.
Concepts
The Big Picture
Imagine you’re a theoretical physicist dropped into the 1960s, just as experimentalists are discovering dozens of new particles faster than anyone can make sense of them. The theory hasn’t caught up. The experimentalists are running laps around the theorists.
That’s the situation in machine learning today. Neural networks beat world champions at Go, fold proteins, and generate images indistinguishable from photographs, yet the theoretical understanding of why they work remains frustratingly incomplete. At TASI 2024, one of the most prestigious summer schools in theoretical physics, Jim Halverson of Northeastern University gave a set of lectures attacking this problem with physics’ sharpest tools: field theory, statistical mechanics, and the large-N limit.
The result is a framework for understanding neural networks from first principles, organized around three questions: what can a network express, what does it look like statistically, and how does it evolve during training? The punchline is that neural networks and quantum field theories share deep mathematical structure, and that connection gives physicists a genuinely useful new way to think about why deep learning works.
How It Works
Halverson structures the framework around a deceptively simple object: a neural network as a function mapping inputs to outputs through adjustable parameters. (In notation, ϕ_θ: ℝᵈ → ℝ means the network takes a d-dimensional input and produces a single number.) Figuring out what that network actually predicts is complicated by two intertwined problems:
- Statistics: Parameters are initialized randomly, so the network is a random function.
- Dynamics: Training changes those parameters over time.
These two pillars, plus a third on expressivity, form the architecture of the lectures.
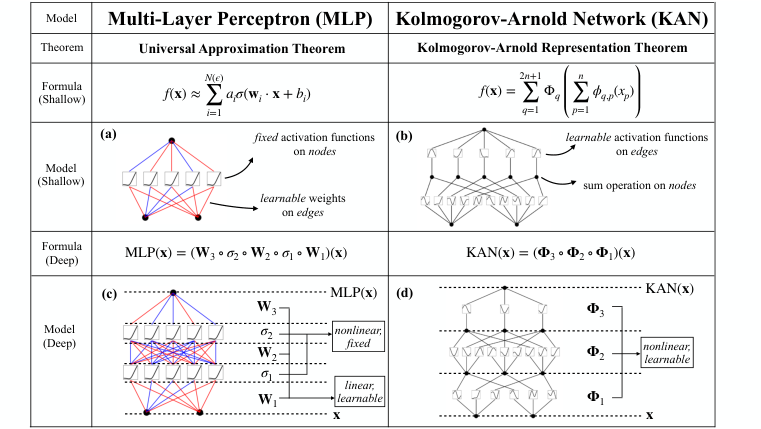
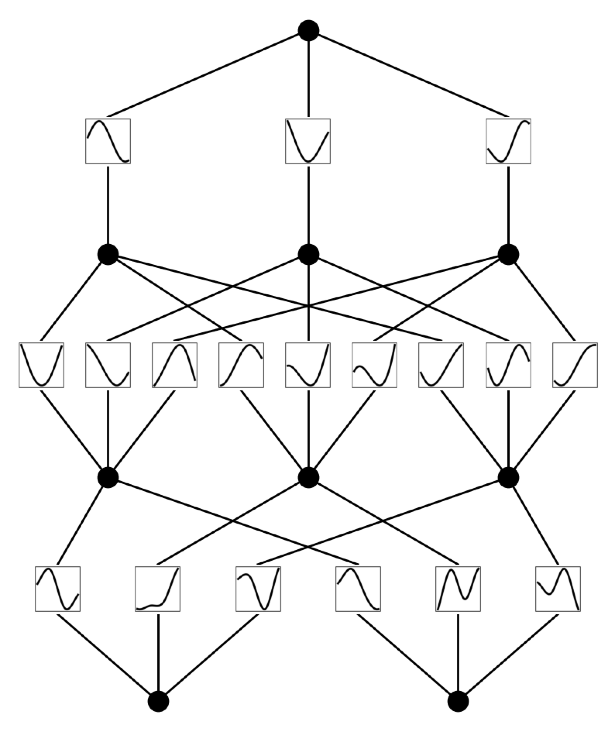
Expressivity asks what functions a network can represent at all. The classic answer is the Universal Approximation Theorem: a sufficiently wide single-hidden-layer network can approximate any continuous function to arbitrary accuracy. Halverson also covers the Kolmogorov-Arnold Theorem, which says any multivariate continuous function can be decomposed into compositions of simpler, single-variable ones. That result recently inspired an entirely new architecture called Kolmogorov-Arnold Networks (KANs), which place learnable activation functions on the network’s edges rather than fixed activations on its nodes.
Statistics is where the physics angle really pays off. When you initialize a neural network with random parameters, the resulting function is itself a random object. In the infinite-width limit, Halverson shows it converges to a Gaussian Process: a probability distribution over functions rather than individual numbers, fully characterized by its mean and covariance. The covariance function is called the kernel, and this result goes by the name NNGP correspondence (Neural Network/Gaussian Process).
Finite-width networks are non-Gaussian. Halverson develops the corrections as a perturbative expansion in 1/width, visualized using Feynman diagrams, the same loop-diagram bookkeeping from particle physics, here repurposed to track correlations between network outputs. These non-Gaussian corrections encode the network’s capacity to learn features (internal representations of the data) rather than simply fitting a fixed kernel.
Dynamics brings in the Neural Tangent Kernel (NTK). In the infinite-width limit, gradient descent doesn’t change the kernel at all. Parameters move, but the geometry of function space stays frozen. Training becomes exactly solvable, reducing to a linear ODE in function space. This is lazy learning: the network performs kernel regression, fitting a smooth curve through training data using the fixed kernel as a similarity measure between inputs.
The more interesting regime is feature learning, captured by the maximal update parameterization (μP). This is a specific scaling of the weights so that hidden layers update by order-one amounts during training, rather than having those updates shrink to zero as the network widens. Hidden layers actually adapt to the data. The contrast between NTK and μP is one of the sharpest distinctions in modern neural network theory and has direct practical consequences for how large models should be initialized and scaled.
Why It Matters
The deepest part of the lectures is the NN-FT correspondence: a formal map between neural network theory and quantum field theory. In QFT, the central object is a path integral, a weighted sum over all possible field configurations. In neural network theory, the analogous object is an integral over all possible parameter configurations, weighted by the initialization distribution. The mathematical skeleton is the same.
Halverson shows explicitly how ϕ⁴ theory (a workhorse model in particle physics, built around a field raised to the fourth power) emerges from the neural network perturbative expansion. The quartic coupling plays the role of the non-Gaussian correction. This isn’t just analogy. It opens a two-way research program: physicists can apply renormalization group methods to understand how neural network behavior changes with scale, while ML researchers can use neural networks as computational tools for field theory calculations.
Several open questions remain. Does renormalization group flow of neural networks correspond to something meaningful about learning? What do the “phases” of neural network behavior look like in hyperparameter space?
For the broader ML community, this perspective brings clarity to questions that have felt empirically murky. Why do wider networks generalize better in some regimes? Why does parameterization choice matter so much at scale? Why do certain data symmetries get automatically respected by trained networks? These aren’t philosophical questions. They have engineering consequences for how we design, train, and scale the next generation of AI systems.
IAIFI Research Highlights
This work establishes a mathematical correspondence between neural network theory and quantum field theory. Techniques from particle physics (Feynman diagrams, perturbative expansions, renormalization group methods) can be applied directly to understanding machine learning systems.
The lectures provide a unified theoretical framework covering expressivity, statistics, and dynamics of neural networks, including the neural tangent kernel and maximal update parameterization. This offers principled guidance for architecture design and large-scale model training.
The NN-FT correspondence opens a new avenue for computation in quantum field theory, with neural networks serving as flexible function approximators for path integrals and field configurations on manifolds including Calabi-Yau spaces relevant to string theory.
Future directions include applying renormalization group techniques to understand neural network scaling laws and using the μP feature-learning regime to probe phase transitions in learning; the full lecture notes are available at [arXiv:2408.00082](https://arxiv.org/abs/2408.00082).