
Test-time scaling of diffusions with flow maps
Authors
Amirmojtaba Sabour, Michael S. Albergo, Carles Domingo-Enrich, Nicholas M. Boffi, Sanja Fidler, Karsten Kreis, Eric Vanden-Eijnden
Abstract
A common recipe to improve diffusion models at test-time so that samples score highly against a user-specified reward is to introduce the gradient of the reward into the dynamics of the diffusion itself. This procedure is often ill posed, as user-specified rewards are usually only well defined on the data distribution at the end of generation. While common workarounds to this problem are to use a denoiser to estimate what a sample would have been at the end of generation, we propose a simple solution to this problem by working directly with a flow map. By exploiting a relationship between the flow map and velocity field governing the instantaneous transport, we construct an algorithm, Flow Map Trajectory Tilting (FMTT), which provably performs better ascent on the reward than standard test-time methods involving the gradient of the reward. The approach can be used to either perform exact sampling via importance weighting or principled search that identifies local maximizers of the reward-tilted distribution. We demonstrate the efficacy of our approach against other look-ahead techniques, and show how the flow map enables engagement with complicated reward functions that make possible new forms of image editing, e.g. by interfacing with vision language models.
Concepts
The Big Picture
Imagine navigating by dead reckoning in fog. You know your speed and heading at every moment, but can’t see where you’ll land. Now imagine consulting a map that tells you directly: “From this position, sailing these currents, you’ll arrive here.” That’s the shift this paper makes in how AI image generators can be steered toward exactly what you want.
Diffusion models, the engines behind tools like Stable Diffusion and DALL-E, generate images by gradually denoising random static into structured pictures. Researchers have long wanted to steer this process at inference time, nudging the model toward images that score well on some goal: “make the clock read 3:47” or “match this text description.” The standard approach calculates, at each generation step, the mathematical direction that would most improve the image’s score. Think of it as adding a current to push a ship toward port. But there’s a catch.
Scoring functions work only on clean, finished images, not on the blurry, half-formed noise mid-generation. The standard workaround is a denoiser, a neural network that predicts what the final image will look like from any intermediate state. It’s a rough approximation, and it fails badly at the early, most critical stages of generation. The fix proposed here: skip the approximation entirely and work with a flow map, a mathematical object that does what the denoiser tries to do, only provably better. The result is Flow Map Trajectory Tilting (FMTT), an algorithm that reliably generates images matching precise specifications where current methods fall short.
Key Insight: Replacing the standard one-step denoiser with a learned flow map that directly predicts where a trajectory will land gives FMTT provably superior reward ascent during image generation, with no retraining of the underlying model.
How It Works
The framework builds on two complementary descriptions of how noise becomes an image. The velocity field gives the instantaneous drift at each moment. The flow map encodes the full solution: given a particle’s position at time t, where does it end up at time T? The two are related by a fundamental identity that the researchers exploit.
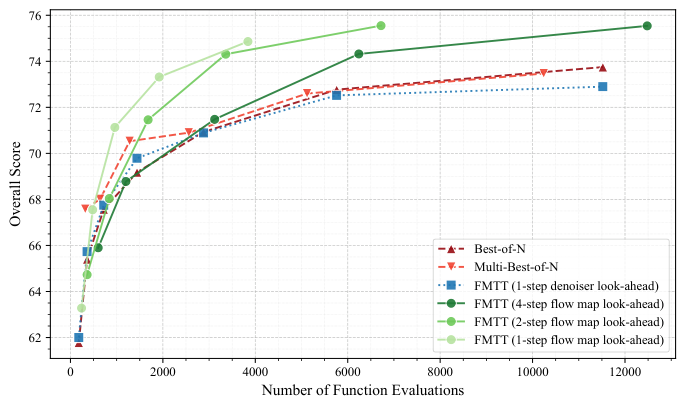
Figure 2 makes the advantage concrete. At early noise levels, the one-step denoiser produces blurry, nearly useless predictions of the final image. A one-step flow map already does better. Four steps yield strikingly clear predictions even from heavily corrupted inputs. This matters because reward guidance depends on accurate look-ahead: garbage prediction, garbage gradient.
The FMTT algorithm works as follows:
- Start with noise drawn from a base distribution and define the target as a tilted distribution, a mathematically adjusted version of the model’s normal output that favors images scoring higher on the goal.
- At each generation step, query the flow map to predict where the current trajectory will terminate. This gives an accurate look-ahead at the clean image.
- Apply the reward gradient with respect to this predicted terminal point. Because the flow map prediction is accurate, the gradient faithfully points toward high-reward outputs.
- Account for thermodynamic length, a measure from non-equilibrium statistical mechanics of how far the guidance pushes the model from its natural behavior. Time-dependent weights compensate for the guidance signal being too weak early in generation.
The framework supports two modes: importance weighting, which adjusts how often different outputs are selected to enable exact sampling from the tilted distribution, and principled search for finding local reward maximizers. Both outperform baseline guidance methods. The importance weighting approach connects to the Jarzynski equality from statistical physics, giving the method formal guarantees about sampling correctness.

The clock example in Figure 1 shows the practical difference. Without FMTT, diffusion models routinely generate clocks showing the wrong time because the model has strong biases toward common clock positions. FMTT’s test-time search overcomes these biases and reliably produces images matching precise time specifications that baselines cannot.
Why It Matters
This work solves a core AI systems problem using mathematical tools from physics. The thermodynamic length formalism gives researchers a principled way to diagnose and improve test-time adaptation methods. That kind of theoretical grounding is rare in guidance research, where most methods are, as the authors put it, “somewhat ad hoc.”
The most immediate payoff is in image editing. FMTT is the first method to successfully use vision-language models (VLMs) as reward functions for diffusion guidance, enabling natural-language-directed editing with fine-grained control. The framework is also architecture-agnostic: any flow-based or diffusion-based generative model, including those used in protein structure prediction or molecular design, could benefit from FMTT-style guidance.
Open questions remain. How do the theoretical guarantees on thermodynamic length translate into practical performance bounds? Can flow maps be trained specifically to optimize look-ahead quality for guidance? How does FMTT scale when the reward function itself is expensive to evaluate, as in physics simulations?
Bottom Line: Flow Map Trajectory Tilting replaces a fundamental approximation at the heart of reward-guided diffusion with a provably superior alternative, achieving reliable test-time steering toward user-specified goals that previous methods could not reach.
IAIFI Research Highlights
The work draws on non-equilibrium statistical mechanics, specifically the Jarzynski equality and thermodynamic length, to build theoretical foundations for a practical AI inference algorithm. It is a clear example of IAIFI's goal of connecting physics and machine learning.
FMTT sets a new state of the art for test-time scaling of diffusion and flow-based generative models, enabling reliable reward-guided generation. It is the first to demonstrate vision-language models as reward functions for diffusion guidance.
The flow map framework and its connections to transport theory and non-equilibrium statistical mechanics provide new mathematical tools for understanding generative modeling as a physical process, with potential applications in scientific domains where precise control over generated structures is critical.
Future work may extend FMTT to scientific domains where fine-grained control over generated structures matters. The paper is available at [arXiv:2511.22688](https://arxiv.org/abs/2511.22688) and is co-authored by IAIFI affiliate Michael S. Albergo at Harvard/Kempner Institute.
Original Paper Details
Test-time scaling of diffusions with flow maps
2511.22688
["Amirmojtaba Sabour", "Michael S. Albergo", "Carles Domingo-Enrich", "Nicholas M. Boffi", "Sanja Fidler", "Karsten Kreis", "Eric Vanden-Eijnden"]
A common recipe to improve diffusion models at test-time so that samples score highly against a user-specified reward is to introduce the gradient of the reward into the dynamics of the diffusion itself. This procedure is often ill posed, as user-specified rewards are usually only well defined on the data distribution at the end of generation. While common workarounds to this problem are to use a denoiser to estimate what a sample would have been at the end of generation, we propose a simple solution to this problem by working directly with a flow map. By exploiting a relationship between the flow map and velocity field governing the instantaneous transport, we construct an algorithm, Flow Map Trajectory Tilting (FMTT), which provably performs better ascent on the reward than standard test-time methods involving the gradient of the reward. The approach can be used to either perform exact sampling via importance weighting or principled search that identifies local maximizers of the reward-tilted distribution. We demonstrate the efficacy of our approach against other look-ahead techniques, and show how the flow map enables engagement with complicated reward functions that make possible new forms of image editing, e.g. by interfacing with vision language models.