
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks
Authors
Ziqian Zhong, Ziming Liu, Max Tegmark, Jacob Andreas
Abstract
Do neural networks, trained on well-understood algorithmic tasks, reliably rediscover known algorithms for solving those tasks? Several recent studies, on tasks ranging from group arithmetic to in-context linear regression, have suggested that the answer is yes. Using modular addition as a prototypical problem, we show that algorithm discovery in neural networks is sometimes more complex. Small changes to model hyperparameters and initializations can induce the discovery of qualitatively different algorithms from a fixed training set, and even parallel implementations of multiple such algorithms. Some networks trained to perform modular addition implement a familiar Clock algorithm; others implement a previously undescribed, less intuitive, but comprehensible procedure which we term the Pizza algorithm, or a variety of even more complex procedures. Our results show that even simple learning problems can admit a surprising diversity of solutions, motivating the development of new tools for characterizing the behavior of neural networks across their algorithmic phase space.
Concepts
The Big Picture
If a meeting starts at 10 and lasts 3 hours, it ends at 1. You solved that using a clock, and so, apparently, does a neural network. When researchers trained small AI models called transformers to perform modular arithmetic (the kind of math that wraps around like a clock face), a 2022 study found something elegant: the networks spontaneously rediscovered the clockface approach. Numbers were encoded as angles, the angles were added, and out came the answer. A clean, geometric solution hiding inside the learned workings of a neural net.
But what happens when you tweak the design? Change how the model processes information, adjust its size, or shift its random starting point? The researchers behind this new paper did exactly that and found something unexpected. Different networks learned completely different algorithms to solve the same problem. Not variations on the clock, but something else entirely. Something that looks less like a clock and more like a pizza.
The paper’s central finding: for even the simplest well-defined algorithmic tasks, neural networks can land on a surprising diversity of internal solutions, and small design changes can push them across sharp boundaries between qualitatively different algorithms.
Key Insight: Neural networks don’t reliably rediscover a single “correct” algorithm for a task, even a simple one. The same training data can produce qualitatively different internal procedures, depending on architecture choices and initialization.
How It Works
The researchers focused on modular addition: given two numbers a and b, compute (a + b) mod p, where p = 59. Think of it as arithmetic on a circle with 59 positions. They trained two model variants: Model A, a one-layer transformer with fixed (non-learned) attention, effectively a ReLU MLP, and Model B, a standard one-layer ReLU transformer with trainable attention.
The previously known Clock algorithm works like this:
- Embed each input number as a point on a unit circle, so number a becomes the angle 2πka/p for some frequency k
- Use the attention mechanism to multiply the trigonometric components and extract the angle a + b
- Read off the answer by matching the resulting angle to the output embedding
The Clock algorithm requires multiplication, and the transformer’s attention mechanism provides it. Model B, with standard trainable attention, implements this cleanly.
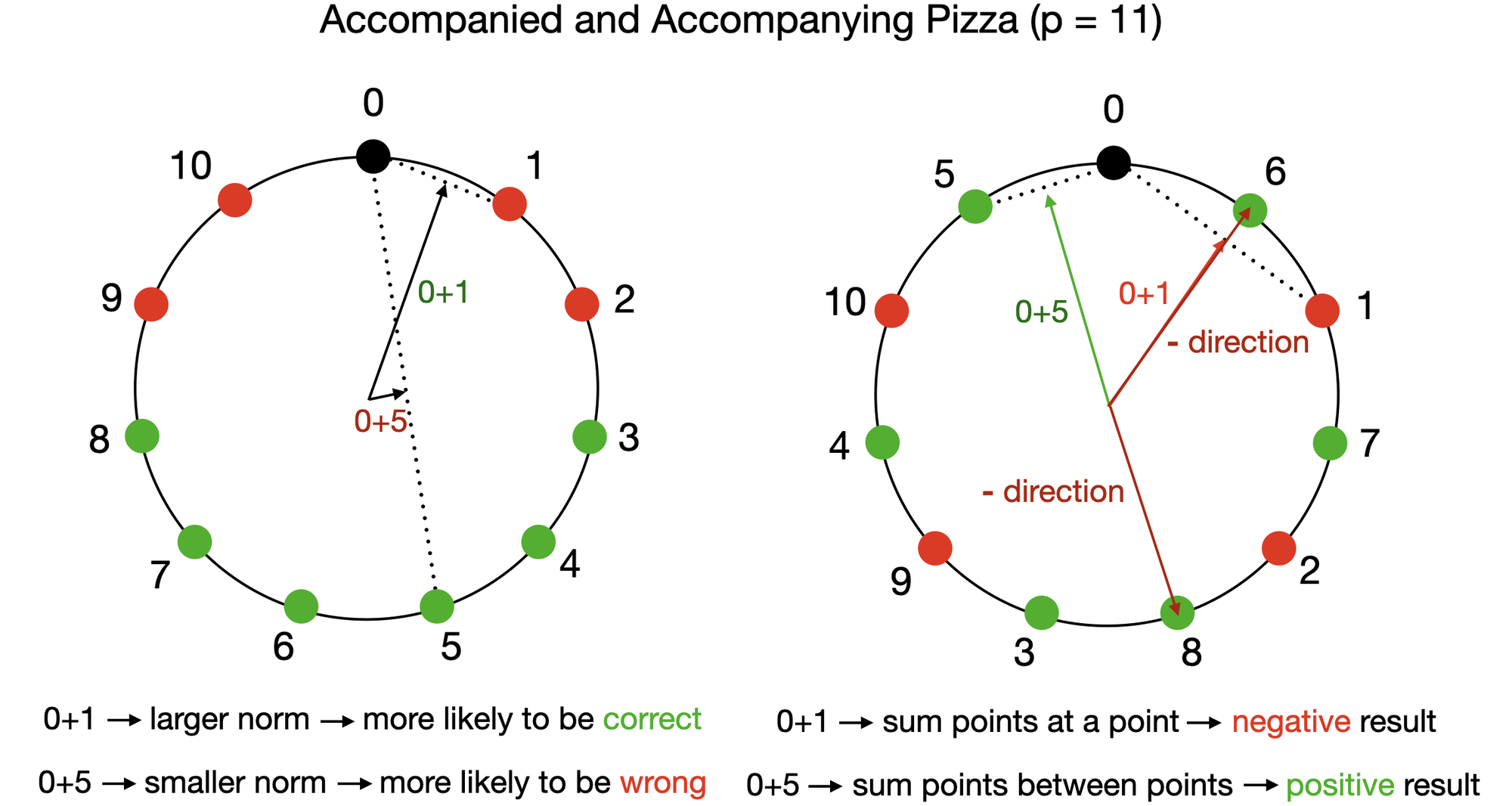
Model A is a different story. Without learnable attention, it can’t multiply the same way. Two signs revealed this. First, the output scores (logits) for each possible answer showed perfect gradient symmetry: the network treated inputs a and b as completely interchangeable. The Clock algorithm breaks this symmetry, so whatever Model A was doing, it wasn’t the Clock. Second, while both models learned circular embeddings, the intermediate computations diverged sharply.
What Model A discovered is the Pizza algorithm, named because it treats the circle not as a continuous angle-space but as something divided into sectors, like pizza slices:
- Embed a and b as circular vectors, just like the Clock algorithm
- Compute the vector mean: average the two input embeddings to get a midpoint vector
- Apply an absolute value nonlinearity, a step that folds negative values to positive, extracting amplitude. This yields a quantity proportional to |cos(wk(a−b)/2)|, which encodes the difference between a and b
- Combine amplitude and direction to reconstruct the sum a + b
The math works because the mean of two unit-circle vectors points in the direction of their angle average, and its magnitude encodes the angle difference. No multiplication required, just the absolute value step.
The sharpest result involves phase transitions. By systematically varying model width and attention strength, the researchers found sharp boundaries where models flipped from Clock to Pizza. They also uncovered messier non-circular algorithms using line-like or Lissajous-curve embeddings (patterns traced by two overlapping oscillations, like a spirograph), and some models ran multiple imperfect Pizza copies in parallel, voting on the answer. The space of solutions has real structure, but it’s far richer than anyone expected.
Why It Matters
A core assumption in interpretability research, sometimes stated, often tacit, is that identifying one algorithm a network uses to solve a task means you’ve understood something fundamental about how that task gets solved. This paper challenges that directly.
Same task, same training data, same basic architecture family: different algorithms. Not different implementations of the same idea, but different mathematical procedures with different computational signatures.
This means interpretability work needs to think in terms of algorithmic phase spaces, the full map of possible internal solutions, not just single algorithmic explanations. Finding one clean story isn’t enough. You need to characterize the full space of possible stories and understand what determines which story any given network will tell. That’s a harder problem, but a more honest one.
It also connects to physics: transitions between algorithmic regimes look structurally similar to phase transitions in physical systems, and the tools physicists use to characterize phase diagrams may find a new home in neural network analysis.
Bottom Line: Neural networks don’t converge on a single algorithm for algorithmic tasks. They explore a phase space of solutions, and small architectural changes can trigger sharp transitions between qualitatively different approaches. To build reliable interpretability tools, we’ll need to map this full phase space rather than settle for one clean explanation.
IAIFI Research Highlights
This work brings the physics concept of phase transitions into neural network analysis. Networks undergo sharp, qualitative shifts in their internal computational strategies as architectural parameters change, a framework borrowed directly from condensed matter physics.
The discovery of the Pizza algorithm and the characterization of algorithmic phase spaces challenge a core assumption in mechanistic interpretability: that networks reliably converge on known algorithms. This motivates new tools for systematically mapping the full diversity of solutions networks can discover.
Even for simple learned systems, mechanistic understanding turns out to be harder than it looks. Researchers should be cautious when assuming a network has "learned" a known physical law or algorithm in scientific applications.
Future work should develop systematic methods for exploring algorithmic phase spaces across model families, transforming how researchers validate neural network solutions in scientific domains. The paper appeared at NeurIPS 2023 and is available at [arXiv:2306.17844](https://arxiv.org/abs/2306.17844), with code at github.com/fjzzq2002/pizza.
Original Paper Details
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks
2306.17844
["Ziqian Zhong", "Ziming Liu", "Max Tegmark", "Jacob Andreas"]
Do neural networks, trained on well-understood algorithmic tasks, reliably rediscover known algorithms for solving those tasks? Several recent studies, on tasks ranging from group arithmetic to in-context linear regression, have suggested that the answer is yes. Using modular addition as a prototypical problem, we show that algorithm discovery in neural networks is sometimes more complex. Small changes to model hyperparameters and initializations can induce the discovery of qualitatively different algorithms from a fixed training set, and even parallel implementations of multiple such algorithms. Some networks trained to perform modular addition implement a familiar Clock algorithm; others implement a previously undescribed, less intuitive, but comprehensible procedure which we term the Pizza algorithm, or a variety of even more complex procedures. Our results show that even simple learning problems can admit a surprising diversity of solutions, motivating the development of new tools for characterizing the behavior of neural networks across their algorithmic phase space.