
The First Two Years of FLEET: an Active Search for Superluminous Supernovae
Authors
Sebastian Gomez, Edo Berger, Peter K. Blanchard, Griffin Hosseinzadeh, Matt Nicholl, Daichi Hiramatsu, V. Ashley Villar, Yao Yin
Abstract
In November 2019 we began operating FLEET (Finding Luminous and Exotic Extragalactic Transients), a machine learning algorithm designed to photometrically identify Type I superluminous supernovae (SLSNe) in transient alert streams. Using FLEET, we spectroscopically classified 21 of the 50 SLSNe identified worldwide between November 2019 and January 2022. Based on our original algorithm, we anticipated that FLEET would achieve a purity of about 50\% for transients with a probability of being a SLSN, \pslsn$>0.5$; the true on-sky purity we obtained is closer to 80\%. Similarly, we anticipated FLEET could reach a completeness of about 30\%, and we indeed measure an upper limit on the completeness of $\approx 33$\%. Here, we present FLEET 2.0, an updated version of FLEET trained on 4,780 transients (almost 3 times more than in FLEET 1.0). FLEET 2.0 has a similar predicted purity to FLEET 1.0, but outperforms FLEET 1.0 in terms of completeness, which is now closer to $\approx 40$\% for transients with \pslsn$>0.5$. Additionally, we explore possible systematics that might arise from the use of FLEET for target selection. We find that the population of SLSNe recovered by FLEET is mostly indistinguishable from the overall SLSN population, in terms of physical and most observational parameters. We provide FLEET as an open source package on GitHub https://github.com/gmzsebastian/FLEET
Concepts
The Big Picture
Imagine trying to find a needle in a cosmic haystack, except the haystack is the entire observable universe, new needles appear every night, and you only have time to examine one in ten of them up close. That’s the reality facing astronomers hunting for superluminous supernovae (SLSNe), stellar explosions that shine up to 100 times brighter than an ordinary supernova, briefly outshining entire galaxies. They’re also extraordinarily rare, making up just 1.5% of all fleeting cosmic events, or transients, that modern sky surveys detect.
Every clear night, survey telescopes like the Zwicky Transient Facility flood astronomers with thousands of alerts about brightening objects. Spectroscopic follow-up, analyzing an object’s light to identify its chemical fingerprint, is the gold standard for confirmation, but it requires pointing a large telescope at a specific target for precious minutes or hours. There’s time to examine only about 10% of all candidates. Choose wrong and you miss a discovery that might not come around again for years.
Sebastian Gomez and colleagues at the Center for Astrophysics | Harvard & Smithsonian built a machine learning triage system called FLEET to address exactly this problem. It scans nightly alerts and flags the most promising SLSN candidates before astronomers commit telescope time. After two years of real-world operation, the system significantly outperformed its designers’ expectations, and a new version pushes the capabilities even further.
Key Insight: FLEET used machine learning to classify 21 out of 50 superluminous supernovae found worldwide over two years, achieving 80% purity (nearly double the expected rate), while a new version trained on nearly 5,000 transients improves completeness to ~40%.
How It Works
FLEET is a random forest classifier: an ensemble of decision trees, each trained on labeled examples, that votes on new cases. For each transient, it combines two distinct information sources: the light curve (how brightness evolves over time) and the properties of its host galaxy (the distant galaxy where the explosion occurred).
Light curve features capture how quickly the object rises and fades, and whether its color matches the characteristically blue light of SLSNe. Host galaxy features exploit a key observational fact: SLSNe tend to explode in small, faint, metal-poor dwarf galaxies, ones with little of the heavier elements beyond hydrogen and helium that are common in larger, older galaxies. Combining both sources gives FLEET a richer fingerprint than either alone.
The system comes in three flavors for different operational needs:
- Rapid version: Uses only the first 20 days of brightness measurements, built for real-time classification when speed matters most
- Late-time version: Uses 70 days of data, providing more reliable predictions and enabling photometric population studies
- Redshift version: The most accurate of the three, but requires knowing the source’s redshift (how much the object’s light has been stretched by cosmic expansion, revealing its distance) in advance
Each version outputs a single number: P(SLSN-I), the probability that the transient is a Type I superluminous supernova. Anything above 0.5 gets flagged for follow-up.
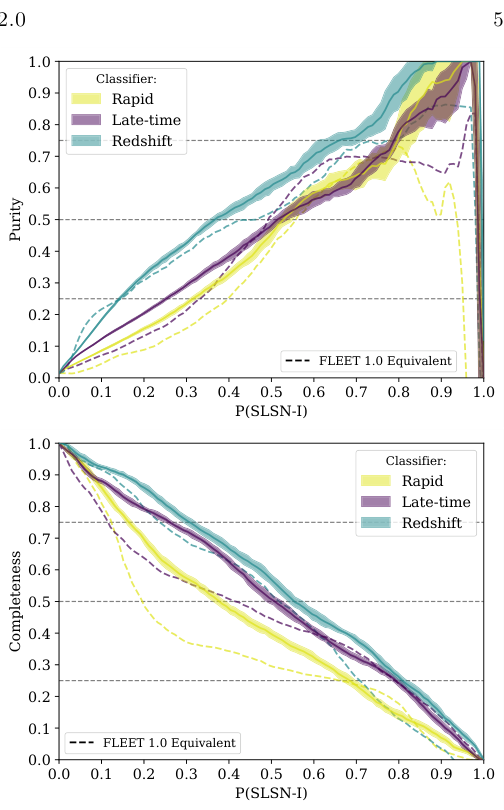
After two years of live operation, FLEET 1.0 did better than predicted. The team had expected roughly 50% purity, meaning half the flagged targets would genuinely be SLSNe. The actual figure came in around 80%, likely because the joint light-curve and host-galaxy approach distinguishes SLSNe from impostors more effectively than anticipated. Completeness, the fraction of all real SLSNe that FLEET caught, landed at roughly 33%, close to the predicted 30%.
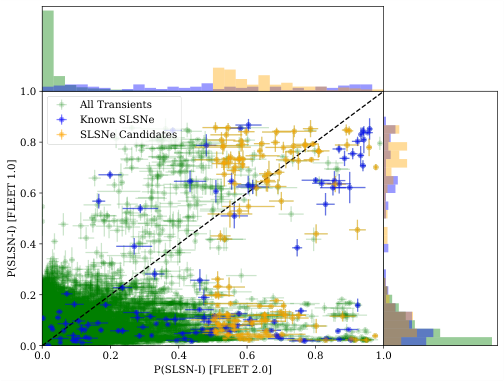
FLEET 2.0 was retrained on 4,780 labeled transients, nearly three times the version 1.0 training set. The larger dataset doesn’t dramatically shift purity, which stays high, but it boosts completeness to approximately 40%. One in ten SLSNe that would have slipped through the old system now gets caught.
The team also checked whether FLEET introduces subtle bias into the scientific record. If the system preferentially recovers only the brightest SLSNe, or only those in certain host galaxies, studies built on FLEET-selected samples could reach skewed conclusions. Their analysis found FLEET-selected SLSNe are largely indistinguishable from the general population across physical and observational parameters, a reassuring sign that the algorithm isn’t unknowingly sculpting the science.
Why It Matters
Superluminous supernovae sit at the frontier of several deep astrophysical questions. What powers them? The leading hypothesis involves a rapidly spinning, highly magnetized neutron star, a magnetar, that deposits energy into expanding debris over weeks to months, but this remains debated. How do they connect to gamma-ray bursts and other exotic transients? What do their unusual host galaxies reveal about the conditions that produce such extreme explosions?
Answering any of these requires statistical samples large enough to separate signal from noise, and building those samples means finding more SLSNe efficiently.
FLEET reflects a broader shift in how astronomy handles the data firehose of modern sky surveys. The Vera Rubin Observatory’s Legacy Survey of Space and Time is expected to detect millions of transients per year, making the target-selection problem orders of magnitude harder. Algorithms trained to triage that flood intelligently, and validated against real follow-up campaigns as FLEET has been, are no longer a nice-to-have. They determine what gets studied and what gets missed.
Bottom Line: FLEET achieved nearly twice its predicted purity in two years of live operation, classifying 42% of all superluminous supernovae found worldwide during that period. Version 2.0, trained on three times more data, improves coverage further while introducing no detectable bias into the recovered population.
IAIFI Research Highlights
This work applies machine learning classification to one of observational astronomy's hardest triage problems, showing that random forest classifiers trained on combined light-curve and host-galaxy features can reliably identify rare transients at scale under real survey conditions.
FLEET 2.0 validates a practical lesson in applied ML: real-world performance can dramatically exceed cross-validated predictions when features are physically well-motivated. Expanding training sets from ~1,700 to ~4,800 labeled examples yielded meaningful gains in recall without sacrificing precision.
By enabling efficient spectroscopic follow-up of superluminous supernovae, likely powered by magnetar engines at the end of massive stellar evolution, FLEET accelerates the collection of samples needed to probe the universe's most luminous explosions.
Future versions of FLEET are positioned to scale to Rubin Observatory data volumes; the full open-source package is available at github.com/gmzsebastian/FLEET, and the paper appears on arXiv as [arXiv:2210.10811](https://arxiv.org/abs/2210.10811).