
The Geometry of Concepts: Sparse Autoencoder Feature Structure
Authors
Yuxiao Li, Eric J. Michaud, David D. Baek, Joshua Engels, Xiaoqing Sun, Max Tegmark
Abstract
Sparse autoencoders have recently produced dictionaries of high-dimensional vectors corresponding to the universe of concepts represented by large language models. We find that this concept universe has interesting structure at three levels: 1) The "atomic" small-scale structure contains "crystals" whose faces are parallelograms or trapezoids, generalizing well-known examples such as (man-woman-king-queen). We find that the quality of such parallelograms and associated function vectors improves greatly when projecting out global distractor directions such as word length, which is efficiently done with linear discriminant analysis. 2) The "brain" intermediate-scale structure has significant spatial modularity; for example, math and code features form a "lobe" akin to functional lobes seen in neural fMRI images. We quantify the spatial locality of these lobes with multiple metrics and find that clusters of co-occurring features, at coarse enough scale, also cluster together spatially far more than one would expect if feature geometry were random. 3) The "galaxy" scale large-scale structure of the feature point cloud is not isotropic, but instead has a power law of eigenvalues with steepest slope in middle layers. We also quantify how the clustering entropy depends on the layer.
Concepts
The Big Picture
Imagine cracking open a large language model and seeing how it organizes concepts. Not as a tangled mess of numbers, but as a structured universe with its own geography. Galaxies of related ideas. Brain-like lobes for math and code. Crystals encoding logical relationships between words. A team of MIT physicists and AI researchers have found exactly this lurking inside the hidden layers of modern language models.
For years, the internal workings of LLMs have been largely opaque. We know these systems can write poetry, solve math problems, and debate philosophy, but how they do it remains one of the deepest mysteries in AI. Making sense of billions of numbers takes more than raw inspection. It takes finding the right language to describe what’s happening inside.
That language may now be available. Using sparse autoencoders (SAEs), tools that decompose a model’s internal activity into distinct “features” roughly corresponding to individual concepts, a team led by Max Tegmark at MIT has mapped the geometry of those concepts across three scales. The result is a richly structured space that behaves more like a physical system than a random collection of data points.
The concepts inside large language models aren’t arranged randomly. They form structured geometric patterns at multiple scales: crystal-like local clusters, brain-like functional lobes, and galaxy-scale distributions following power laws.
How It Works
At any given moment, a language model’s internal signals can be thought of as a blend of many “features,” each representing a concept like “royalty,” “Paris,” or “negation.” Most features are dormant; only a handful switch on for any particular word or sentence. That’s what sparse means here. An SAE learns to discover which features are active and reconstruct the original signal from them. Think of it as separating a complex chord into its individual notes.
Once you have a dictionary of such features (the researchers use publicly available SAEs trained on the Gemma language model), you can ask: how are these features arranged geometrically? The team examined structure at three scales.
Scale 1: Crystal Structures
The classic example of geometric structure in word representations is the parallelogram: man − woman ≈ king − queen. The researchers find that SAE features form analogous parallelograms at the concept level, and many such parallelograms tile together into crystal-like structures. A grid of (country, capital, language, demonym) relationships is one example.
These parallelograms become much cleaner when you remove “distractor” directions, global patterns like word length that contaminate the geometry. The team does this with linear discriminant analysis (LDA), a statistical technique that filters out background noise to isolate the clean geometric signal. After this correction, both parallelogram quality and related “function vectors” (vectors encoding a consistent semantic operation) improve substantially.
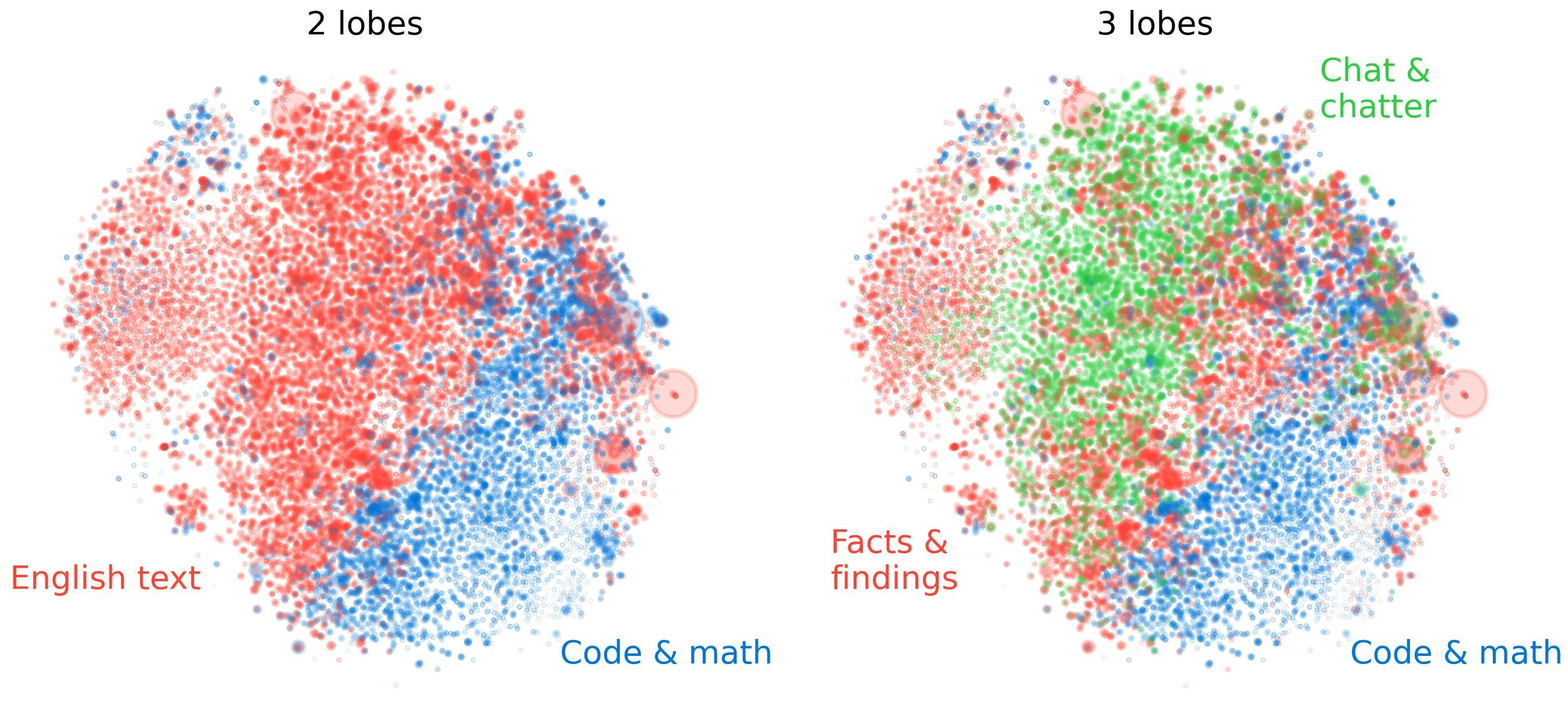
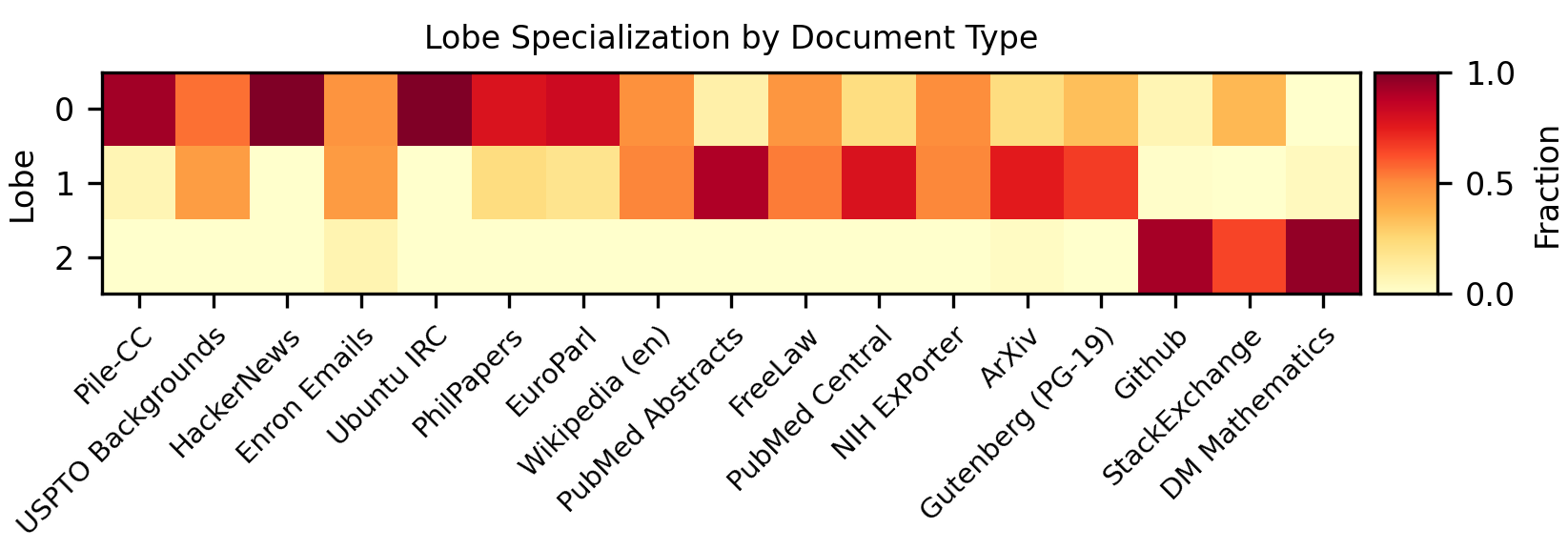
Scale 2: Functional Lobes
At intermediate scales, the SAE feature space has spatial modularity resembling the functional organization of a biological brain. Math features cluster together. Code features form their own region. Language-specific features occupy distinct neighborhoods.
The team quantifies this using multiple metrics, including nearest-neighbor locality tests and co-activation clustering. Concept clusters at coarse spatial scales turn out to be far more localized than you’d expect from random arrangement. Just as neuroscientists use fMRI to identify brain regions that “light up” together, co-occurring SAE features tend to sit near each other spatially. At fine scales the clustering is modest, but zoom out and the structure becomes hard to miss.

Scale 3: Large-Scale Anisotropy
At the largest scale, the full cloud of feature vectors is anything but a uniform sphere. The researchers compute the eigenvalue spectrum of the feature covariance matrix, measuring how much the cloud stretches in different directions, and find a power-law distribution. Power laws are a hallmark of structured, non-random systems.
The slope is steepest in the middle layers of the model, suggesting that intermediate processing stages carry the richest geometric structure. Clustering entropy, a measure of how evenly features are distributed across concept clusters, also varies by layer in consistent patterns. This may reflect how the model builds increasingly abstract representations as information flows through its layers.
Why It Matters
This work sits at the intersection of two urgent questions in AI: What do language models actually represent? and Can we trust what we can’t see? Mechanistic interpretability has made real progress with sparse autoencoders, but understanding individual features is only part of the puzzle. If we want to audit AI systems for hidden goals or deceptive behavior, we need to understand not just individual concepts but how the entire concept space is organized.
The geometric structure uncovered here opens concrete new directions:
- Crystal-like local structure implies that systematic semantic relationships (analogies, transformations, hierarchies) are encoded in precise geometric form. We might eventually “read” a model’s internal logic by examining the shapes of these crystals.
- Brain-like modularity suggests LLMs develop functional specialization on their own during training, not because anyone designed them to.
- Galaxy-scale power laws point to connections between language model representations and statistical physics, a link Tegmark’s group is actively pursuing.
The open questions are just as interesting. Does this geometric structure hold across model families and scales? Do the “lobes” correspond to computational modules that can be manipulated or interpreted independently? Each question brings us closer to language models we can genuinely understand, not just use.
Language model concepts aren’t just vectors in a void. They form a structured geometric universe with crystal-like clusters, brain-like functional lobes, and galaxy-scale power laws, giving us a new map for navigating AI interpretability.
IAIFI Research Highlights
This work synthesizes tools from statistics, condensed matter physics, and neuroscience to understand the internal structure of large language models, a cross-disciplinary contribution from MIT's IAIFI.
By characterizing the geometric structure of sparse autoencoder feature spaces at multiple scales, this research provides new quantitative tools for mechanistic interpretability and for auditing AI systems for hidden or misaligned behaviors.
The discovery of power-law eigenvalue spectra and crystal-like geometric structures in neural concept spaces reveals connections between language model representations and the mathematics of physical systems.
Future work will test whether this geometric structure generalizes across model families and scales, and whether it can inform AI safety applications. The full paper is available at [arXiv:2410.19750](https://arxiv.org/abs/2410.19750) and published in *Entropy* (2025).
Original Paper Details
The Geometry of Concepts: Sparse Autoencoder Feature Structure
[2410.19750](https://arxiv.org/abs/2410.19750)
["Yuxiao Li", "Eric J. Michaud", "David D. Baek", "Joshua Engels", "Xiaoqing Sun", "Max Tegmark"]
Sparse autoencoders have recently produced dictionaries of high-dimensional vectors corresponding to the universe of concepts represented by large language models. We find that this concept universe has interesting structure at three levels: 1) The "atomic" small-scale structure contains "crystals" whose faces are parallelograms or trapezoids, generalizing well-known examples such as (man-woman-king-queen). We find that the quality of such parallelograms and associated function vectors improves greatly when projecting out global distractor directions such as word length, which is efficiently done with linear discriminant analysis. 2) The "brain" intermediate-scale structure has significant spatial modularity; for example, math and code features form a "lobe" akin to functional lobes seen in neural fMRI images. We quantify the spatial locality of these lobes with multiple metrics and find that clusters of co-occurring features, at coarse enough scale, also cluster together spatially far more than one would expect if feature geometry were random. 3) The "galaxy" scale large-scale structure of the feature point cloud is not isotropic, but instead has a power law of eigenvalues with steepest slope in middle layers. We also quantify how the clustering entropy depends on the layer.