
The Optimiser Hidden in Plain Sight: Training with the Loss Landscape's Induced Metric
Authors
Thomas R. Harvey
Abstract
We present a class of novel optimisers for training neural networks that makes use of the Riemannian metric naturally induced when the loss landscape is embedded in higher-dimensional space. This is the same metric that underlies common visualisations of loss landscapes. By taking this geometric perspective literally and using the induced metric, we develop a new optimiser and compare it to existing methods, namely: SGD, Adam, AdamW, and Muon, across a range of tasks and architectures. Empirically, we conclude that this new class of optimisers is highly effective in low dimensional examples, and provides slight improvement over state-of-the-art methods for training neural networks. These new optimisers have theoretically desirable properties. In particular, the effective learning rate is automatically decreased in regions of high curvature acting as a smoothed out form of gradient clipping. Similarly, one variant of these optimisers can also be viewed as inducing an effective scheduled learning rate and decoupled weight decay is the natural choice from our geometric perspective. The basic method can be used to modify any existing preconditioning method. The new optimiser has a computational complexity comparable to that of Adam.
Concepts
The Big Picture
Picture a hiker trying to find the lowest valley in a vast, fog-covered mountain range. She can only feel the slope beneath her feet, so she steps in whichever direction tilts downward the steepest. That’s gradient descent, the engine behind virtually every neural network trained today. But here’s the catch: the map she draws and the steps she takes are geometrically inconsistent. Sketching the terrain, she naturally captures hills and curves. Moving through it, she ignores them entirely.
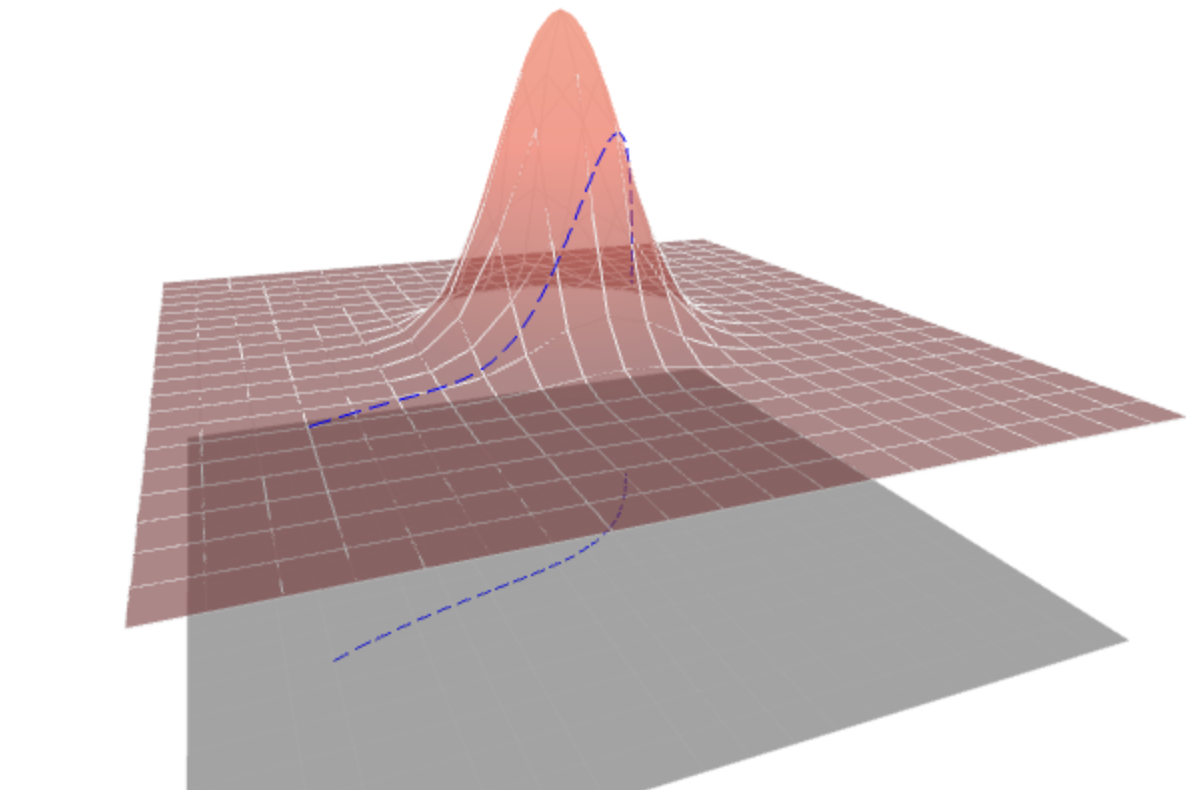
That disconnect is the puzzle Thomas Harvey at MIT’s IAIFI set out to close. Researchers have been drawing loss landscapes (those swooping, curved surfaces showing how a neural network’s errors change as its parameters are adjusted) for decades. Those visualizations implicitly encode a specific geometric structure, a way of measuring distances that accounts for terrain curvature. Yet no one had ever used that geometry to build an optimizer, the algorithm that actually adjusts parameters during training. The curvature was hiding in plain sight.
Harvey’s new work takes that visualization geometry seriously as a mathematical object, derives the optimizer it implies, and shows the result is competitive with modern methods like Adam, AdamW, and Muon, often beating them.
The same geometric structure researchers use to visualize loss landscapes has never been used to navigate them. Treating it as a real measure of curvature yields an optimizer with automatic curvature adaptation and natural connections to gradient clipping, learning rate scheduling, and weight decay.
How It Works
The technical core rests on Riemannian geometry, the mathematics of curved spaces (and the same framework Einstein used to describe gravity). When you embed the loss landscape as a surface in a higher-dimensional space, that embedding automatically defines an induced metric: a way of measuring how far apart two points really are, accounting for the terrain’s curvature.
Harvey takes that induced metric and plugs it directly into the equation governing how parameters change during training. Standard gradient descent moves parameters in proportion to the raw gradient. With a metric, you instead warp the step direction to respect local geometry, stretching or shrinking steps based on how curved the terrain is. This is gradient preconditioning, and it’s exactly what Adam and its relatives already do, just with metrics chosen for numerical convenience rather than geometric principle.
The specific metric Harvey derives depends on a choice of embedding function, which controls how you transform the loss value when lifting it into the higher-dimensional space. There are two natural choices:
- Square-root embedding (f(L) = √L): Produces an optimizer that behaves like smoothed gradient clipping. In high-curvature regions where gradients can explode, the effective learning rate automatically shrinks; in flat regions, it stays large.
- Logarithmic embedding (f(L) = log L): Goes further, inducing a natural learning rate schedule that decays step size as training progresses. Decoupled weight decay, the regularization technique that is the “W” in AdamW, also falls out as the geometrically natural choice.
The computational cost is minimal. Both variants require only a single additional dot product per iteration over vanilla SGD, keeping complexity at O(N), the same as Adam. Compare that to second-order methods, which require computing or approximating the full Hessian matrix (a table of second derivatives capturing how each parameter interacts with every other) and carry prohibitive overhead.
Why It Matters
Harvey tests the new optimizers across a ladder of problems, from pathological toy functions to large-scale neural networks.
In low-dimensional optimization, the log-loss variant was the only optimizer tested that found the global minimum across all pathological test functions. That’s strong evidence the geometric curvature adaptation does exactly what the theory promises.
For neural network training, the picture is more mixed. Across MLPs on MNIST, ResNet-18 on CIFAR-10, and transformer models on TinyShakespeare, the RMSprop-preconditioned variant performed best on average across most tasks. The improvements over Adam and AdamW are modest but consistent.
The framework is also modular. The induced metric correction can be applied on top of any existing preconditioning method, including Muon. It’s not locked to one algorithm; it’s a wrapper that can upgrade existing tools.
The practical gains are incremental rather than revolutionary, and Harvey is careful to say as much. The deeper value is conceptual. The field has built up a grab bag of empirical tricks: gradient clipping to prevent explosions, learning rate schedules to manage convergence, decoupled weight decay to separate regularization from momentum. Each was developed independently, justified by its own ad-hoc rationale.
This paper shows all three fall out naturally from a single geometric principle. That kind of unification is exactly what theoretical physics prizes, not just a new tool but a cleaner picture of why existing tools work.
If the induced metric really is the right geometry for loss landscapes, it opens a systematic research program. What other optimizer behaviors does this framework predict? Can the geometry extend to non-Euclidean parameter spaces? The mathematics of Riemannian geometry underlies general relativity; the same tools for describing curved spacetime now show up at the heart of neural network optimization. It’s the kind of cross-pollination IAIFI was built for.
Harvey takes the geometry behind loss landscape visualizations literally, derives a new family of optimizers from it, and shows they automatically adapt to curvature. Gradient clipping, learning rate scheduling, and weight decay all emerge from one geometric principle. Performance matches or beats state-of-the-art methods at Adam-level computational cost.
IAIFI Research Highlights
This work applies Riemannian differential geometry (the mathematical language of curved spacetime in general relativity) directly to neural network optimization, showing how tools move productively between fundamental physics and machine learning.
The new optimizers match or beat SGD, Adam, AdamW, and Muon across diverse architectures and tasks, while providing a geometric explanation that unifies gradient clipping, learning rate scheduling, and decoupled weight decay.
The geometric framework connects physical notions of curvature and induced metrics to the practical problem of training the AI systems used in fundamental physics research.
Future work may explore alternative embedding functions, hybrid geometric-preconditioning schemes, and extensions to non-Euclidean parameter spaces; the paper and code are available at [arXiv:2509.03594](https://arxiv.org/abs/2509.03594) and [github.com/harveyThomas4692/Induced-Metric-Optimiser](https://github.com/harveyThomas4692/Induced-Metric-Optimiser).