
The Pareto Frontier of Resilient Jet Tagging
Authors
Rikab Gambhir, Matt LeBlanc, Yuanchen Zhou
Abstract
Classifying hadronic jets using their constituents' kinematic information is a critical task in modern high-energy collider physics. Often, classifiers are designed by targeting the best performance using metrics such as accuracy, AUC, or rejection rates. However, the use of a single metric can lead to the use of architectures that are more model-dependent than competitive alternatives, leading to potential uncertainty and bias in analysis. We explore such trade-offs and demonstrate the consequences of using networks with high performance metrics but low resilience.
Concepts
The Big Picture
Imagine hiring the world’s best sprinter to run a marathon. On a dry track, they’re unbeatable. In mud or at altitude, a steady ultrarunner finishes while the sprinter falters. In high-energy physics, machine learning classifiers face exactly this dilemma.
At CERN’s Large Hadron Collider, protons smash together millions of times per second, producing tight sprays of particles called jets, debris cones carrying clues about what originally collided. Figuring out which kind of particle produced a given jet is called jet tagging, one of the most important tasks in modern particle physics. It enables searches for undiscovered particles and precise measurements of known ones.
Over the past decade, physicists have turned to increasingly powerful AI designs claiming ever higher scores on standard benchmarks. But a new study from IAIFI-affiliated researchers asks a disquieting question: what if chasing higher test scores is making our physics analyses worse?
Key Insight: The most accurate jet-tagging models are often the least reliable on real data, because they’ve learned quirks of their training simulations rather than genuine physics. The researchers map out a fundamental trade-off between raw performance and robustness, revealing a Pareto frontier that no model can escape.
How It Works
The core problem is simulation dependence. Real collisions are too complex for exact equations, so researchers rely on Monte Carlo event generators, software that simulates millions of virtual collisions. No simulator perfectly captures nature. Two leading packages, PYTHIA and HERWIG, make different modeling choices that produce subtly different jet distributions. A classifier trained on PYTHIA may score brilliantly on PYTHIA test data, then quietly degrade when confronted with HERWIG data or real detector output.
The researchers introduce resilience: how much a classifier’s performance drops when tested on a different simulator than the one it trained on. They measure it as the percent difference in AUC (area under the ROC curve, a standard score where 1.0 is perfect and 0.5 is no better than a coin flip) between PYTHIA and HERWIG samples. A resilient model shows little change; a fragile one diverges.
They surveyed five architecture classes spanning a wide range of complexity:
- Expert features: hand-crafted physics variables like angularities (how spread out a jet is) and multiplicities (particle count inside the jet)
- Deep Neural Networks (DNNs): 2–10 hidden layers with varying neuron counts
- Particle-Flow Networks (PFNs) and Energy-Flow Networks (EFNs): architectures treating each jet as an unordered particle cloud, built to respect the symmetry that results shouldn’t change if particles are reordered
- Particle Transformer (ParT): a state-of-the-art attention-based architecture, the same core approach used in large language models
All models received only raw kinematic information (particle momenta and angles) and were trained on two tasks: quark/gluon discrimination and boosted top-quark tagging.
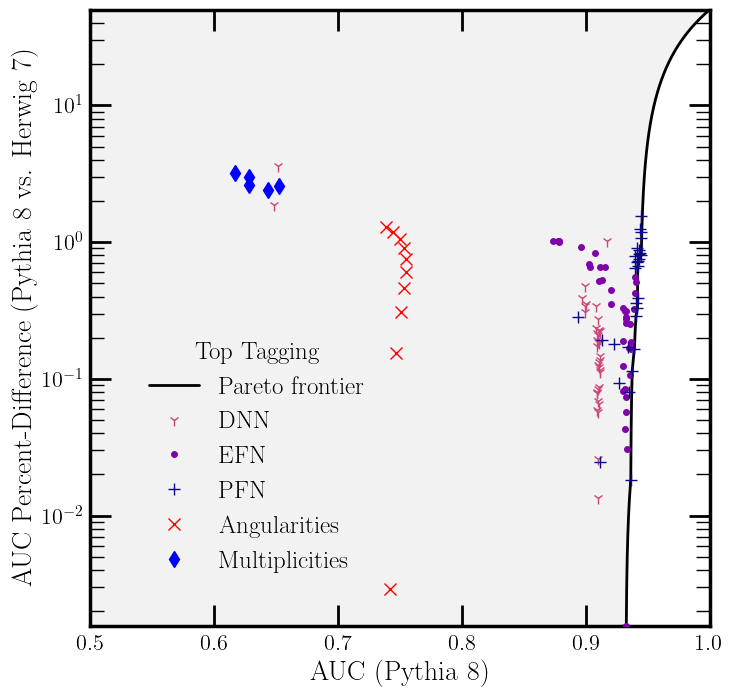
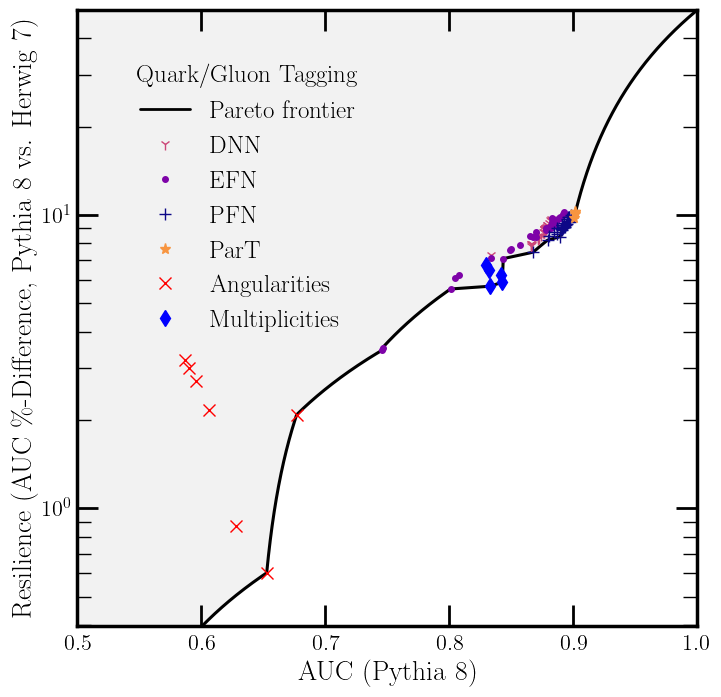
The Pareto frontier plot tells the story at a glance. In the AUC-versus-resilience plane, the frontier curves like a physical law. The Particle Transformer achieves the highest raw AUC but pays with substantially reduced resilience. EFNs and simple expert features sit in the opposite corner: lower peak performance, but far more stable across simulators. Models in the “Pareto-excluded” region are simply inferior, beaten on both metrics simultaneously by another architecture.
The Knowledge Distillation Attempt
Could clever training tricks break through the frontier? The team tested knowledge distillation, a technique where a smaller “student” model learns to copy a larger, more powerful “teacher,” hoping to inherit the teacher’s accuracy while retaining the student’s stability.
Students did improve beyond naive linear interpolation between teacher and baseline, meaning distillation provided genuine gains. But no distilled student pushed past the existing Pareto frontier. Whatever sets that boundary seems to reflect something fundamental about the trade-off between model expressivity and cross-simulator generalization.
A Real-World Consequence
The team ran a concrete case study: estimating the flavor mixture fraction κ (the proportion of quark jets versus gluon jets in a mixed sample) using two PFNs at different points on the Pareto frontier.
The large, high-AUC PFN (latent dimension 128, 250 nodes per hidden layer) produces biased estimates of κ when test data comes from a different simulator than training data. The small, resilient PFN (latent dimension 8, 50 nodes per hidden layer) yields less precise estimates under ideal conditions but far more accurate ones when simulator mismatch is present. By conventional metrics, the “better” classifier can actively mislead a downstream physics analysis.
Why It Matters
The LHC’s Run 3 is underway, and the upcoming High-Luminosity LHC will produce data at vastly higher rates, placing even greater demands on AI classifiers. As the field pushes toward graph networks, transformers, and foundation models, the temptation to optimize for leaderboard scores grows stronger. If those scores are measured purely on simulation-matched test sets, they may not reflect real-world reliability at all.
The lesson applies well beyond jet physics. Across machine learning, models trained and tested under matched conditions are brittle when real-world data shifts even slightly. The Pareto frontier framework gives physicists a principled way to talk about this trade-off: classifier quality is a curve in a multidimensional space, not a single number.
Open questions remain. Does the Pareto frontier itself shift as training datasets grow, or does it reflect a hard limit imposed by the information content of jet constituents? Can physics-informed architectures fundamentally push the boundary? And how does the picture change when accounting for detector uncertainties, pile-up effects, and domain shifts between LHC runs?
Bottom Line: Chasing AUC alone builds jet taggers that are fast but fragile. The Pareto frontier shows there’s no free lunch: physicists should treat resilience as a first-class benchmark alongside accuracy, or risk biasing the very measurements they’re trying to make.
IAIFI Research Highlights
This work imports the Pareto frontier concept from economics into particle physics classifier design, showing how a cross-disciplinary framework can expose trade-offs invisible from within either field.
Knowledge distillation provides genuine gains but cannot overcome fundamental performance-robustness trade-offs, a cautionary result for practitioners who rely on distillation to compress brittle models.
High-AUC jet taggers can systematically bias measurements like quark/gluon fraction estimation. This finding challenges standard practices at the LHC and argues for resilience-aware classifier design in precision analyses.
Future work includes extending the Pareto framework to detector effects, pile-up, and future collider conditions, and exploring whether physics-informed architectures can shift the frontier; the paper is available at [arXiv:2509.19431](https://arxiv.org/abs/2509.19431).