
The Price of Freedom: Exploring Expressivity and Runtime Tradeoffs in Equivariant Tensor Products
Authors
YuQing Xie, Ameya Daigavane, Mit Kotak, Tess Smidt
Abstract
$E(3)$-equivariant neural networks have demonstrated success across a wide range of 3D modelling tasks. A fundamental operation in these networks is the tensor product, which interacts two geometric features in an equivariant manner to create new features. Due to the high computational complexity of the tensor product, significant effort has been invested to optimize the runtime of this operation. For example, Luo et al. (2024) recently proposed the Gaunt tensor product (GTP) which promises a significant speedup. In this work, we provide a careful, systematic analysis of a number of tensor product operations. In particular, we emphasize that different tensor products are not performing the same operation. The reported speedups typically come at the cost of expressivity. We introduce measures of expressivity and interactability to characterize these differences. In addition, we realized the original implementation of GTP can be greatly simplified by directly using a spherical grid at no cost in asymptotic runtime. This spherical grid approach is faster on our benchmarks and in actual training of the MACE interatomic potential by 30%. Finally, we provide the first systematic microbenchmarks of the various tensor product operations. We find that the theoretical runtime guarantees can differ wildly from empirical performance, demonstrating the need for careful application-specific benchmarking. Code is available at https://github.com/atomicarchitects/PriceofFreedom.
Concepts
The Big Picture
Imagine teaching a computer to understand the shape of a molecule: not just which atoms are present, but how they’re arranged in 3D space and how that arrangement changes when you rotate it. The model must “know” that a water molecule rotated 90 degrees is still a water molecule. This requirement, that outputs rotate consistently with inputs, is called equivariance, and building it into neural networks is one of the central challenges of scientific AI.
At the heart of every equivariant network sits a mathematical operation called the tensor product: a universal mixer that takes two geometric signals, combines their rotational patterns at every level of angular detail, and produces a richer signal that still respects 3D symmetry.
But this mixer is expensive. Increase the angular resolution parameter L (how finely the model represents rotational patterns) and the cost scales as L⁵. A modest jump from L=2 to L=4 makes the computation roughly 32 times slower.
Recent papers have claimed dramatic speedups by achieving O(L³) complexity, scaling as the cube of L. This paper from MIT’s Smidt group asks an uncomfortable question: are these faster operations actually computing the same thing? The answer is no, and the difference matters in practice.
Key Insight: Faster “tensor products” in equivariant networks aren’t computing the same thing as the standard one. They sacrifice mathematical expressivity for speed, and this paper is the first to rigorously measure what you’re giving up.
How It Works
The Clebsch-Gordan tensor product (CGTP) is the gold standard. It uses angular momentum coupling coefficients from quantum mechanics to combine features of any angular frequency in the most general possible way. The operation is universal: any equivariant operation that takes two inputs and combines them linearly can be written as a linear layer on top of a CGTP output. That universality costs O(L⁵).
To quantify what faster alternatives sacrifice, the authors introduce two measures:
- Expressivity: how many independent output channels an operation can produce, essentially how rich the mixing is.
- Interactability: whether two specific input frequencies can actually influence each other in the output.
The Gaunt tensor product (GTP), proposed by Luo et al. in 2024, achieves O(L³) using Gaunt coefficients. These describe how angular patterns on a sphere combine, drawing from the same mathematics used to model electron orbitals. It turns out GTP is mathematically equivalent to projecting both inputs onto a discrete spherical grid, multiplying pointwise, and projecting back.
This spherical grid interpretation isn’t just cleaner conceptually; it’s simpler to implement. The original GTP required an intricate change-of-basis (a transformation switching between different mathematical representations of the same data), and the grid approach skips it entirely at no asymptotic cost.
The matrix tensor product (MTP), from Unke & Maennel 2024, takes a different shortcut: it treats features as matrices and multiplies them. Natural in linear algebra, but this imposes a strong structural constraint. MTP has lower expressivity than even GTP, and certain cross-frequency interactions (where different levels of angular detail must influence each other) are completely absent.
Every O(L³) operation achieves its speedup by restricting which feature interactions are possible. The researchers formalize this with a diagram showing which (L₁, L₂) → L_out interactions each operation supports, i.e., which combinations of input angular frequencies can produce each output frequency. The gaps are substantial.
The authors then ran the first systematic microbenchmarks across all major tensor product implementations. The results are surprising:
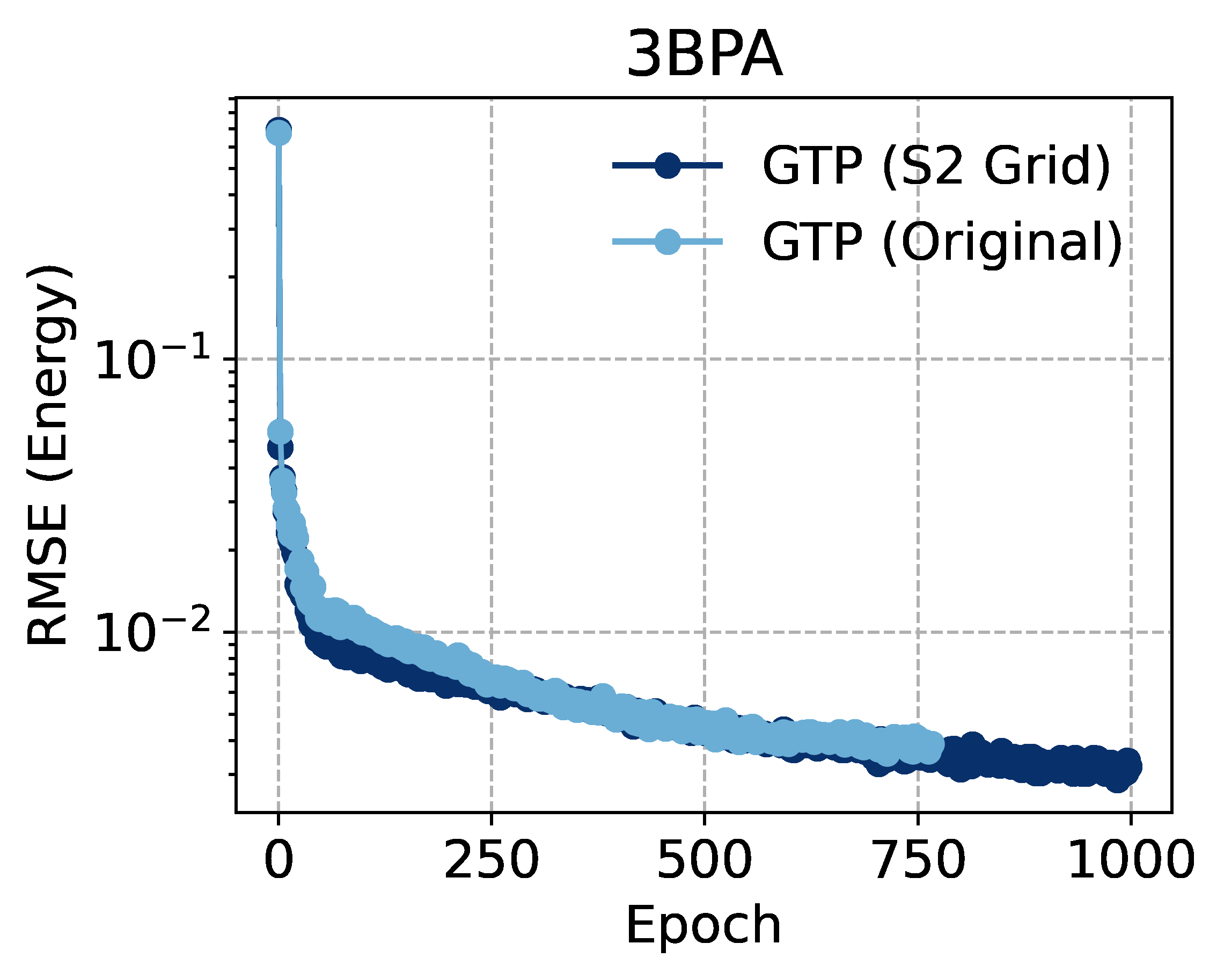
- The spherical grid implementation of GTP is consistently faster than the original GTP across all tested L values, despite identical asymptotic complexity.
- On MACE interatomic potential training (a real-world molecular dynamics benchmark), the spherical grid approach is 30% faster than the original GTP implementation.
- The CGTP, despite O(L⁵) theoretical scaling, outperforms supposedly faster operations at small L values where hardware-level optimizations dominate.
- Theoretical complexity rankings often completely reverse in practice at the L values researchers actually use.
Researchers have been making architectural choices, trading expressivity for speed, based on asymptotic arguments that don’t hold at practical scales. This paper provides the benchmarking infrastructure to make better-informed tradeoffs.
Why It Matters
Equivariant neural networks are the backbone of scientific AI: they power molecular force fields like MACE and NequIP, protein structure prediction, and catalyst discovery tools. All of them use tensor products as a core building block. The choice of which tensor product to use, and at what angular frequency, shapes both model accuracy and computational budget.
The paper gives researchers a rigorous vocabulary for comparing operations that look similar but behave very differently. The expressivity and interactability measures let practitioners ask “what am I giving up?” before choosing a faster approximation. The simplification of GTP to a spherical grid is immediately deployable: a free 30% speedup with no change in mathematical behavior.
The open questions are real. Can higher-expressivity operations be designed at O(L³) cost? Are there physics problems where the missing interactions in GTP or MTP actually degrade prediction accuracy? The authors’ benchmarking framework and open-source code make these questions tractable.
Bottom Line: The “fast” tensor products in equivariant AI aren’t computing what you think. The actual fastest implementation is a conceptual simplification that was there all along: project everything onto a sphere, and you get a 30% real-world speedup for free.
IAIFI Research Highlights
This work connects representation theory from quantum mechanics (specifically the Clebsch-Gordan and Gaunt coefficients used in angular momentum coupling) to practical neural network engineering, showing that a physics-inspired spherical grid interpretation yields a concrete computational speedup.
The paper introduces the first rigorous framework for measuring expressivity and interactability of equivariant tensor product operations. Researchers now have formal tools to evaluate architectural tradeoffs in symmetry-preserving networks.
Faster equivariant networks translate directly to faster simulation of matter at the quantum level, from molecular dynamics to materials design. Molecular force fields like MACE and NequIP are the immediate beneficiaries.
Future work should explore whether higher-expressivity operations at O(L³) cost are achievable, and whether missing interactions affect accuracy on specific physical systems. The full benchmarking suite is open-source at [github.com/atomicarchitects/PriceofFreedom](https://github.com/atomicarchitects/PriceofFreedom).
Original Paper Details
The Price of Freedom: Exploring Expressivity and Runtime Tradeoffs in Equivariant Tensor Products
[arXiv:2506.13523](https://arxiv.org/abs/2506.13523)
["YuQing Xie", "Ameya Daigavane", "Mit Kotak", "Tess Smidt"]
$E(3)$-equivariant neural networks have demonstrated success across a wide range of 3D modelling tasks. A fundamental operation in these networks is the tensor product, which interacts two geometric features in an equivariant manner to create new features. Due to the high computational complexity of the tensor product, significant effort has been invested to optimize the runtime of this operation. For example, Luo et al. (2024) recently proposed the Gaunt tensor product (GTP) which promises a significant speedup. In this work, we provide a careful, systematic analysis of a number of tensor product operations. In particular, we emphasize that different tensor products are not performing the same operation. The reported speedups typically come at the cost of expressivity. We introduce measures of expressivity and interactability to characterize these differences. In addition, we realized the original implementation of GTP can be greatly simplified by directly using a spherical grid at no cost in asymptotic runtime. This spherical grid approach is faster on our benchmarks and in actual training of the MACE interatomic potential by 30%. Finally, we provide the first systematic microbenchmarks of the various tensor product operations. We find that the theoretical runtime guarantees can differ wildly from empirical performance, demonstrating the need for careful application-specific benchmarking. Code is available at https://github.com/atomicarchitects/PriceofFreedom.