
The Principles of Deep Learning Theory
Authors
Daniel A. Roberts, Sho Yaida, Boris Hanin
Abstract
This book develops an effective theory approach to understanding deep neural networks of practical relevance. Beginning from a first-principles component-level picture of networks, we explain how to determine an accurate description of the output of trained networks by solving layer-to-layer iteration equations and nonlinear learning dynamics. A main result is that the predictions of networks are described by nearly-Gaussian distributions, with the depth-to-width aspect ratio of the network controlling the deviations from the infinite-width Gaussian description. We explain how these effectively-deep networks learn nontrivial representations from training and more broadly analyze the mechanism of representation learning for nonlinear models. From a nearly-kernel-methods perspective, we find that the dependence of such models' predictions on the underlying learning algorithm can be expressed in a simple and universal way. To obtain these results, we develop the notion of representation group flow (RG flow) to characterize the propagation of signals through the network. By tuning networks to criticality, we give a practical solution to the exploding and vanishing gradient problem. We further explain how RG flow leads to near-universal behavior and lets us categorize networks built from different activation functions into universality classes. Altogether, we show that the depth-to-width ratio governs the effective model complexity of the ensemble of trained networks. By using information-theoretic techniques, we estimate the optimal aspect ratio at which we expect the network to be practically most useful and show how residual connections can be used to push this scale to arbitrary depths. With these tools, we can learn in detail about the inductive bias of architectures, hyperparameters, and optimizers.
Concepts
The Big Picture
Imagine trying to understand a city by studying every brick in every building. You’d drown in detail before learning anything useful about traffic patterns or neighborhoods. Physicists learned long ago that the key to understanding complex systems isn’t tracking every microscopic piece; it’s finding the right level of description.
This insight gave us thermodynamics (which explains heat and steam engines without tracking every molecule) and the Standard Model of particle physics (our best account of how electrons, quarks, and the fundamental forces interact). It turns out to be exactly what deep learning theory has been missing.
Deep neural networks work, often unreasonably well. But why they work has remained mysterious. Practitioners adjust settings by intuition, fix obscure failures through trial and error, and choose architectures by folklore as much as principle. Theoretical explanations have either been too simple to be useful or too complicated to be workable. What the field needed was something physicists call an effective theory: a principled framework that captures essential behavior without getting lost in microscopic noise.
That’s what Daniel Roberts, Sho Yaida, and Boris Hanin deliver in The Principles of Deep Learning Theory. Starting from first principles, they build a complete analytical framework for understanding what trained neural networks actually do, and why a single ratio, depth divided by width, controls nearly everything that matters.
Key Insight: The behavior of a deep neural network is governed by its depth-to-width ratio, which controls how far the network’s outputs deviate from a simple Gaussian distribution and how strongly the network learns internal representations from data.
How It Works
The starting observation is clean: at initialization, if a network is infinitely wide, its outputs follow a Gaussian distribution. This is mathematically exact. But infinite-width networks don’t actually learn useful representations. The interesting physics happens when the network is finite, and signals at one layer influence the statistics of the next.
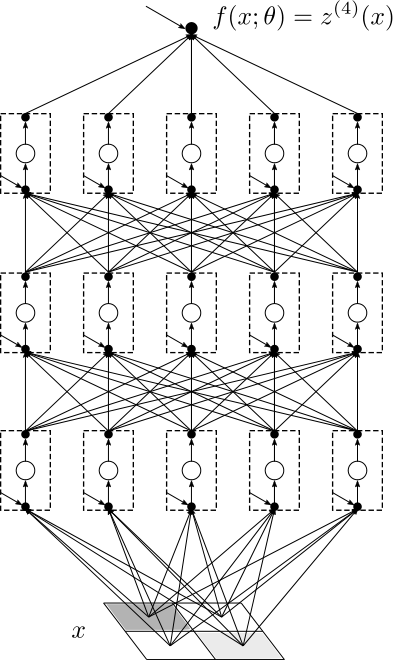
To track these influences, Roberts et al. introduce representation group flow (RG flow), named deliberately to echo the renormalization group from particle physics. In physics, RG flow describes how a theory’s effective description changes as you zoom in or out on a system. Here, it describes how the statistical properties of neural activations transform as signals pass from layer to layer. Starting from Gaussian outputs in the first layer, each successive layer accumulates small non-Gaussian corrections that encode the network’s growing “knowledge” of the data.
The quantity tracking these deviations is the four-point connected correlator, a statistical measure of how much four neurons’ outputs move together in ways a pure bell curve can’t explain. Think of it as a gauge of how “un-bell-curve-like” the network has become. This quantity grows systematically with the depth-to-width ratio L/N. When L/N is small (wide networks), outputs stay nearly Gaussian. When it grows (deeper or narrower networks), non-Gaussianities accumulate and representation learning kicks in.
The framework produces several concrete results:
- Criticality and initialization: By tuning the variance of initial weights, networks can be placed at a “critical point” where signals propagate without exploding or vanishing. The authors derive exact conditions from the RG flow equations, grounding the empirical initialization schemes practitioners already use.
- Universality classes: Just as different physical systems can share the same large-scale behavior, different activation functions fall into distinct universality classes. Whether an activation belongs to the ReLU family, the tanh family, or another group determines the statistical character of deep representations, regardless of fine details.
- The Neural Tangent Kernel: At infinite width, gradient descent training is equivalent to a kernel method, a well-understood statistical technique that finds patterns by measuring similarity between data points. The authors track how finite width breaks this equivalence through the differential of the Neural Tangent Kernel (dNTK), showing how representation learning emerges as a systematic correction on top of kernel behavior.
The training dynamics analysis is particularly elegant. For wide-enough networks, the authors derive closed-form predictions for how outputs evolve during gradient descent. The dependence on the specific optimizer (SGD, Adam, and so on) drops out in a universal way: final trained predictions depend on the optimizer only through a single effective learning rate, not through its detailed trajectory.
Why It Matters
The real contribution here isn’t any single formula. It’s a way of thinking. By casting neural network theory in the language of statistical field theory and renormalization groups, Roberts, Yaida, and Hanin give the field tools that physicists spent a century refining. The effective theory approach tells practitioners not just what to compute, but which quantities are universal and which are accidental details.
The depth-to-width ratio emerges as the central design parameter, a single dimensionless number that determines whether a network is “effectively shallow” (well-described by kernel methods) or “effectively deep” (capable of nontrivial representation learning). Using information-theoretic arguments, the authors estimate the optimal depth-to-width ratio for practical learning. They also show how residual connections, the skip connections in architectures like ResNets, can extend this optimal regime to arbitrarily deep networks.
Plenty of open questions remain. The framework focuses on multilayer perceptrons with clean mathematical structure. Extending these ideas to transformers, convolutional networks, and attention mechanisms is an active frontier. The connection between the effective theory picture and training dynamics at scale, where networks are neither infinitely wide nor infinitely narrow, will likely drive theoretical work for years.
Bottom Line: By borrowing the physicist’s toolkit of effective theories and renormalization group flow, Roberts, Yaida, and Hanin show that a single number, the depth-to-width ratio, governs how neural networks learn representations. This provides the first systematic theoretical foundation for understanding why deep learning works.
IAIFI Research Highlights
This work directly imports renormalization group methods and effective field theory from fundamental physics into deep learning theory. The mathematical structures governing phase transitions and particle interactions turn out to also govern how neural networks process information.
The framework delivers exact analytical predictions for network behavior at initialization and during training, including derivations of optimal initialization schemes and a proof that trained predictions depend on the optimizer in a simple, universal way.
The identification of universality classes for activation functions and the application of criticality analysis to neural networks builds a formal bridge between condensed matter physics and machine learning, exposing deep structural parallels between the two fields.
Extending these techniques to attention-based architectures and practical training regimes at scale is a major open frontier; the full theoretical treatment is available as a Cambridge University Press monograph by Roberts, Yaida, and Hanin.