
To Augment or Not to Augment? Diagnosing Distributional Symmetry Breaking
Authors
Hannah Lawrence, Elyssa Hofgard, Vasco Portilheiro, Yuxuan Chen, Tess Smidt, Robin Walters
Abstract
Symmetry-aware methods for machine learning, such as data augmentation and equivariant architectures, encourage correct model behavior on all transformations (e.g. rotations or permutations) of the original dataset. These methods can improve generalization and sample efficiency, under the assumption that the transformed datapoints are highly probable, or "important", under the test distribution. In this work, we develop a method for critically evaluating this assumption. In particular, we propose a metric to quantify the amount of anisotropy, or symmetry-breaking, in a dataset, via a two-sample neural classifier test that distinguishes between the original dataset and its randomly augmented equivalent. We validate our metric on synthetic datasets, and then use it to uncover surprisingly high degrees of alignment in several benchmark point cloud datasets. We show theoretically that distributional symmetry-breaking can actually prevent invariant methods from performing optimally even when the underlying labels are truly invariant, as we show for invariant ridge regression in the infinite feature limit. Empirically, we find that the implication for symmetry-aware methods is dataset-dependent: equivariant methods still impart benefits on some anisotropic datasets, but not others. Overall, these findings suggest that understanding equivariance -- both when it works, and why -- may require rethinking symmetry biases in the data.
Concepts
The Big Picture
Imagine teaching a child to recognize coffee mugs by showing them thousands of photos. Every single photo shows the handle on the right side. Now you test the child on a mug with the handle on the left, and they fail. The child hasn’t learned “mug-ness.” They’ve learned “right-handed mug-ness.”
Machine learning models face the same trap.
For years, researchers have celebrated symmetry-aware neural networks, models built on the insight that rotating or rearranging an object shouldn’t change what it fundamentally is. A molecule rotated 90 degrees is still the same molecule, so the model’s predictions should rotate accordingly. This idea has driven real breakthroughs in materials science, drug discovery, and robotics.
But there’s a hidden assumption baked into all of it: that rotated versions of your data appear just as often in the real world as the originals. A new paper from MIT and Northeastern asks bluntly: what if they’re not?
Hannah Lawrence, Elyssa Hofgard, and colleagues built a diagnostic tool to measure exactly how badly real-world datasets violate this assumption. What they found is that some of the most popular benchmarks in AI and physics are deeply skewed, with real consequences for whether symmetry-aware methods actually help.
Key Insight: The benefits of equivariant machine learning depend critically on whether training data is uniformly distributed across orientations. Most benchmark datasets are not, which can cause equivariant methods to hurt rather than help.
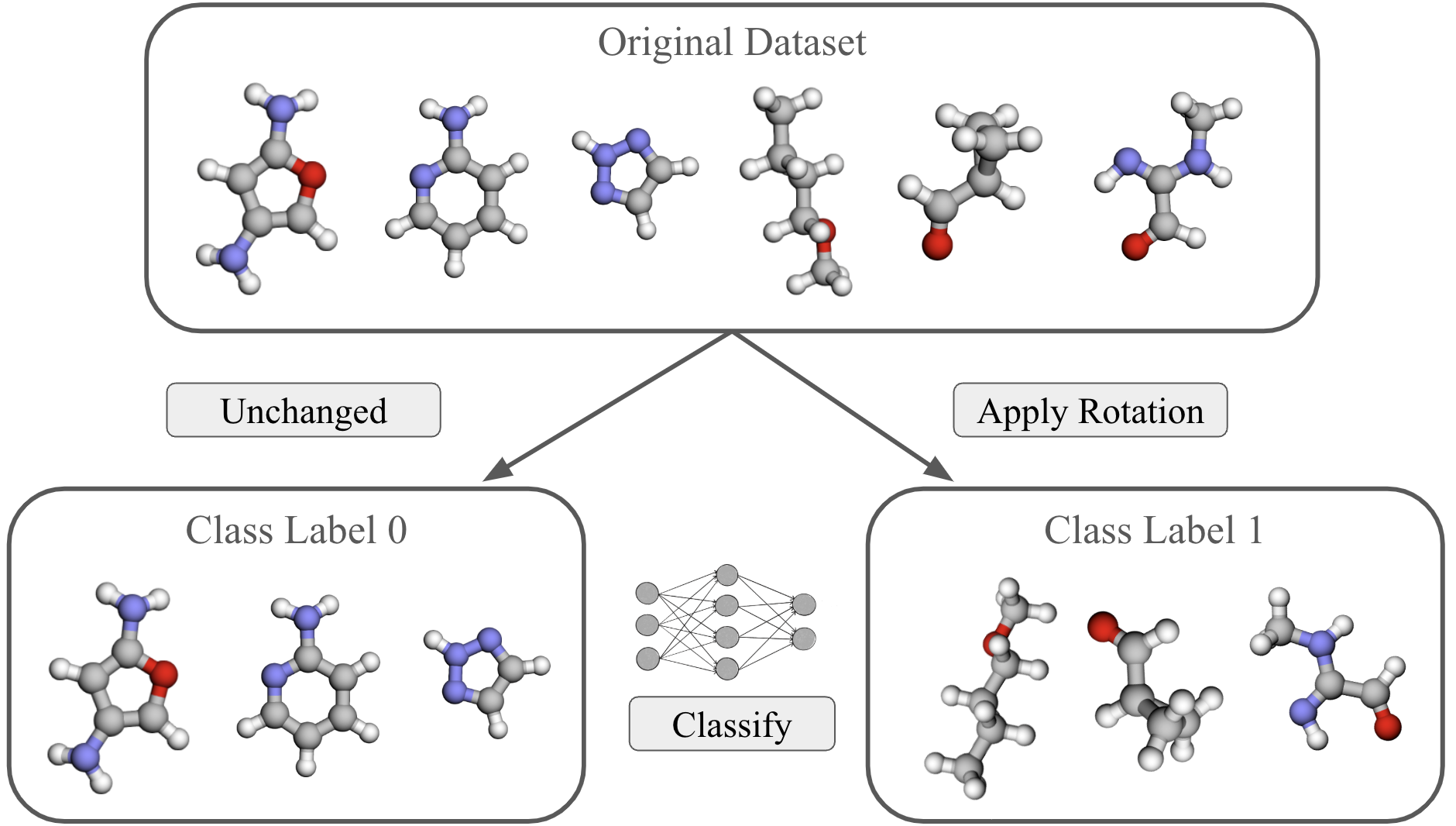
How It Works
The core concept is distributional symmetry breaking: when a data point $x$ and its transformed version $gx$ (say, a rotated molecule) appear with very different frequencies in your dataset. At one extreme, data is isotropic: every orientation is equally likely, like a baseball tumbling randomly through the air. At the other extreme, data is fully canonicalized: every object appears in exactly one privileged orientation, like a crystal structure always aligned to a standard axis. Most real datasets fall somewhere in between, but nobody had a clean way to measure where.
The team’s solution: train a classifier to distinguish between the original dataset and a randomly rotated copy of it. If the dataset is perfectly symmetric, no classifier should do better than 50% accuracy; the two distributions look identical. But if the dataset is canonicalized, a smart classifier can easily tell “original” from “rotated” by recognizing that certain orientations simply don’t occur naturally.
This two-sample classifier test has several practical virtues:
- It requires no domain knowledge about why the data might be anisotropic
- The output, a test accuracy between 0.5 and 1.0, is directly interpretable
- It can be paired with interpretability methods applied to the classifier itself, revealing which features signal orientation
When applied to widely used benchmarks, the picture was clear. Point cloud datasets including QM9 (molecular quantum chemistry), revised MD17 (molecular dynamics), OC20 (open catalyst), and ModelNet40 (3D object shapes) all showed high degrees of non-uniformity under 3D rotations. These are the standard training grounds for equivariant graph neural networks (GNNs) and molecular property predictors, and they are far more canonicalized than the field has assumed.
The theoretical half of the paper formalizes why this matters. Using invariant ridge regression as a tractable model, the team proves that data augmentation can actively harm performance when invariant and non-invariant features are correlated. The intuition: if orientation encodes useful information and you destroy it through augmentation, your model loses signal it could have used. Even when true labels are rotation-invariant, the path to learning them may run through orientation-dependent features in skewed data.
Why It Matters
This work reframes a foundational question in geometric deep learning. The field has largely treated equivariance as an unambiguous good, a way to build physical knowledge into models. The standard story: if the physics is symmetric, make your model symmetric.
Lawrence et al. show that the data distribution is a third actor in this story, alongside model architecture and the true underlying function. A symmetric model trained on asymmetric data is mismatched in a way that can erode performance even when the labels themselves are symmetric.
The consequences are concrete. Materials scientists using equivariant graph networks to predict crystal properties, drug discovery pipelines relying on molecular geometry models, robotics researchers building rotation-invariant perception: all of them now face a question that goes beyond “is the task symmetric?” They need to ask whether their dataset is symmetric, and whether that mismatch matters. The two-sample classifier test gives them a way to find out.
The empirical picture is not black and white, though. Equivariant methods still outperform on some highly anisotropic datasets, which means the relationship between data symmetry and model performance is dataset-dependent rather than governed by a simple rule. Open questions remain about when canonicalization is benign versus harmful, and whether hybrid approaches like partial augmentation, learned canonicalization, or orientation-aware architectures can thread the needle.
Bottom Line: Equivariant ML has quietly relied on an assumption that training datasets don’t actually satisfy. This paper gives researchers a concrete tool to measure the gap, and theoretical proof that the gap can hurt, demanding a more careful, data-aware approach to symmetry in AI.
IAIFI Research Highlights
This work connects geometric deep learning and physical symmetry, applying rigorous group theory to diagnose when mathematical symmetries used in physics-informed AI are mismatched with training data.
The two-sample classifier metric is architecture-agnostic and broadly applicable. Practitioners can use it to evaluate any dataset before choosing between standard and equivariant architectures.
Popular molecular and materials benchmarks (QM9, MD17, OC20) turn out to be highly canonicalized, calling for re-evaluation of equivariant GNNs used to predict quantum chemical and catalytic properties.
Future directions include developing adaptive methods that exploit orientation information in canonicalized datasets; the full paper is available at [arXiv:2510.01349](https://arxiv.org/abs/2510.01349).
Original Paper Details
To Augment or Not to Augment? Diagnosing Distributional Symmetry Breaking
2510.01349
["Hannah Lawrence", "Elyssa Hofgard", "Vasco Portilheiro", "Yuxuan Chen", "Tess Smidt", "Robin Walters"]
Symmetry-aware methods for machine learning, such as data augmentation and equivariant architectures, encourage correct model behavior on all transformations (e.g. rotations or permutations) of the original dataset. These methods can improve generalization and sample efficiency, under the assumption that the transformed datapoints are highly probable, or "important", under the test distribution. In this work, we develop a method for critically evaluating this assumption. In particular, we propose a metric to quantify the amount of anisotropy, or symmetry-breaking, in a dataset, via a two-sample neural classifier test that distinguishes between the original dataset and its randomly augmented equivalent. We validate our metric on synthetic datasets, and then use it to uncover surprisingly high degrees of alignment in several benchmark point cloud datasets. We show theoretically that distributional symmetry-breaking can actually prevent invariant methods from performing optimally even when the underlying labels are truly invariant, as we show for invariant ridge regression in the infinite feature limit. Empirically, we find that the implication for symmetry-aware methods is dataset-dependent: equivariant methods still impart benefits on some anisotropic datasets, but not others. Overall, these findings suggest that understanding equivariance -- both when it works, and why -- may require rethinking symmetry biases in the data.